









HashMap源码解析
一,哈希表
数组随机访问快增删慢,链表访问慢增删快,哈希表则综合了二者的优势。
哈希表是根据键来访问值的一种数据结构,值被映射在了表里的某个位置。映射有取余等多种方法,映射后同一位置可能对应多个数据,会有冲突,常用解决方法有:
1. 开放定址法
Hi=(H(key)+di)mod m,i=1,2,…,k(k≤m−1)
哈希值加上探测散列值di然后再取余
探测散列包括线性探测散列(…,i,…)、二次探测散列(…,i^2,…)、伪随机探测散列等
2. 再哈希法
Hi=H2(H1(key)),用新的哈希函数再求一次哈希
3. 拉链法
HashMap的实现方案
4. 公共溢出区
二,源码分析
1,父类AbstractMap
HashMap
2,HashMap
((Android源码里的版本))
transient HashMapEntry<K,V>[] table
哈希图通过散列表的数据结构实现了map的功能,具体是通过拉链法的方式实现的。
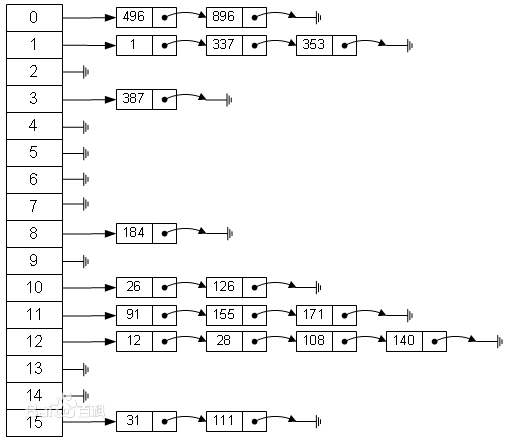
哈希图由数组和链表组成。成员变量数组table,存储了链表的头结点HashMapEntry,结点字段包括key、value、hash、next(下一个结点)
static class HashMapEntry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
HashMapEntry<K,V> next;
int hash;
}
2.1 put
每次插入元素时,先遍历table数组,寻找hash和key都匹配上的结点,如果有,更新值;如果没有,根据hash值找到对应的链表头结点在table中的索引,也即找到对应的链表头结点,新建一个HashMapEntry,保存键、值、hash,并将该新结点插入到链表头部作为头结点,然后将table中该链表对应的索引上的元素替换成该新结点。
int buketIndex= indexFor(hash, table.length);
HashMapEntry<K,V> e = table[bucketIndex];
table[bucketIndex] = new HashMapEntry<>(hash, key, value, e);
size++;
2.2 get
跟据键key换算出hash,然后换算出对应索引,在table数组里找到对应链表头结点。遍历这条链表,直到hash值和key都匹配上为止。
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 :
sun.misc.Hashing.singleWordWangJenkinsHash(key);
for (HashMapEntry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
3,Hashtable
3.1 Hashtable和HashMap的区别
- Hashtable是线程安全的(使用了synchronized),HashMap非线程安全,但是效率比Hashtable高
- Hashtable的key不允许null,但是HashMap可以
3.2 Hashtable的线程安全的实现
Hashtable对方法使用了synchronized进行同步,如put
public synchronized V put(K key, V value) {
4,ConcurrentHashMap
HashMap非现场安全,而Hashtable虽然线程安全,但由于对整个方法进行同步,多线程要访问同一方法的话,一开始就需要竞争同一把锁,效率低下。
ConcurrentHashMap是线程安全的HashMap,它使用了锁分段技术,不同数据段使用不同的锁,多线程访问不同数据段的时候不需要竞争锁,效率比Hashtable高。
4.1 java7 的实现
ConcurrentHashMap里包含了数组Segment<K,V>[] segments
Segment是ReentrantLock的子类,这是一个可重入锁,它内部有一个HashEntry数组,类似于HashMap的结构,每个HashEntry都是一个链表的头结点
transient volatile HashEntry<K,V>[] table;
1. put操作
ConcurrentHashMap每一把锁Segment锁住了一段区域,要修改、添加该区域内的结点数据,需要获取对应的Segment锁,然后再Segment里修改、添加结点等。
2. get操作
get操作没有加锁,效率比hashtable高。
4.2 java8 的实现
java8放弃了Segment,改用桶数组的桶来代表分段区域。
ConcurrentHashMap用了两个桶数组,一个是存放各个桶头结点的数组table,一个是扩容用的数组nextTable。
table延迟加载直到第一个元素插入,table的大小总是2的n次幂。
transient volatile Node<K,V>[] table;
private transient volatile Node<K,V>[] nextTable;
1. put操作
桶空的时候的直接CAS插入,桶不空的时候对头结点加锁然后以链表的形式插入,如果链表长度超过8,就转换成红黑树。
桶空的时候直接CAS插入
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//f指向桶头结点 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin桶不空的时候,桶不空的时候对头结点加锁然后插入到链表尾部或者红黑树里,如果链表长度超过8,就转换成红黑树
V oldVal = null; synchronized (f) {//桶的头结点加锁 if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) {//遍历链表,binCount记录了链表长度 K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {//hash与key相同时修改结点的值 oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) {//插入尾部 pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) {//如果桶头结点是树的头结点TreeBin,那么按照红黑树来添加 Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD)//如果链表长度超过8,就转换成红黑树 treeifyBin(tab, i); if (oldVal != null) return oldVal; break; }转变成红黑树的treeifyBin()操作里
Node结点被转变成TreeNode结点,Node链表转变成TreeNode链表,然后TreeNode链表通过
new TreeBin(TreeNode<K,V> b)转变成红黑树















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









