






当网站文章数量打到百万级的时候估计开源的cms就很难满足要求了,仅仅是分页,相信就可以将网站卡死。大数据量优化的方式有很多,提高服务器配置,数据分表,sql语句优化,等等
1,表的类型
mysql常用的表类型有两种:MyISAM和InnoDB,MyISAM表对与select执行效率要高于InnoDB类型的表,测试时仅有5W数据,执行select `id` from `text` limit 40000,1;效率相差在1000倍左右。
创建表test:
CREATE TABLE IF NOT EXISTS `test` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`title` varchar(10) CHARACTER SET utf8 NOT NULL DEFAULT '0',
`content` text CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=gbk COMMENT='id索引' AUTO_INCREMENT=1 ;
然后用php写循环,插入5W条数据做测试,但是数据量超大,做变态测试5W条记录,达到2G,笔记本电脑,配置一般(ThinkPad R400 A17)

2,大数据信息分页优化
依旧是4W数据,MyISAM类型表,sql语句:
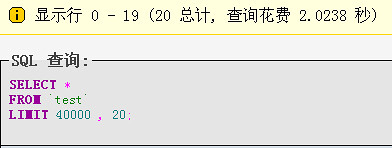
最常用分表sql语句执行效率:select * from `test` limit 40000,20; 第一次执行时间49.9991(由于mysql缓存原因,执行玩第一次后的执行时间为2.0238S): 测试图如下:
第一次:
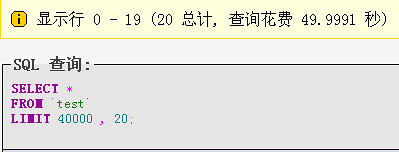
第二次:
添加where限制:select * from `test` where id>=40000 limit 100000,20;首次执行时间执:11.6099,以后稳定在0.4849S这仅仅是5W数据,真正打到百万级数据,相差会更大。
第一次:
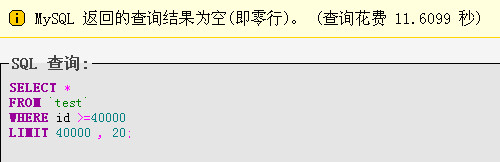
第二次:
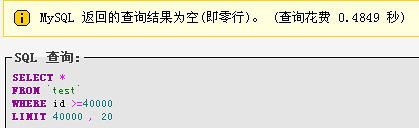
总结:添加where限制条件,让查询飞快,不添加where条件的时候,mysql会将前40000条数据全部读取一遍,然后获取后面的20条数据,添加where限制条件就不会,效率会高出很多,当然变态测试,主要是看效果。
3,其他小技巧:
select 的字段最好不要添加索引,select id from text limit 10000,20;在id添加索引后效率明显降低。
尽可能多的占用浏览器连接,比如新浪、比如人人网首页上的文件都存放在好多域名下,比如a.sina.com.cn、b.sina.com.cn、d.sinacom.cn等等,因为浏览器默认为每个域名打开固定的连接数,ie6为打开两个,ie7增加到四个,域名用的越多,站的连接数越多,相当于加载的线程越多,速度当然就要快。
1,表的类型
mysql常用的表类型有两种:MyISAM和InnoDB,MyISAM表对与select执行效率要高于InnoDB类型的表,测试时仅有5W数据,执行select `id` from `text` limit 40000,1;效率相差在1000倍左右。
创建表test:
CREATE TABLE IF NOT EXISTS `test` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`title` varchar(10) CHARACTER SET utf8 NOT NULL DEFAULT '0',
`content` text CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=gbk COMMENT='id索引' AUTO_INCREMENT=1 ;
然后用php写循环,插入5W条数据做测试,但是数据量超大,做变态测试5W条记录,达到2G,笔记本电脑,配置一般(ThinkPad R400 A17)
2,大数据信息分页优化
依旧是4W数据,MyISAM类型表,sql语句:
最常用分表sql语句执行效率:select * from `test` limit 40000,20; 第一次执行时间49.9991(由于mysql缓存原因,执行玩第一次后的执行时间为2.0238S): 测试图如下:
第一次:
第二次:
添加where限制:select * from `test` where id>=40000 limit 100000,20;首次执行时间执:11.6099,以后稳定在0.4849S这仅仅是5W数据,真正打到百万级数据,相差会更大。
第一次:
第二次:
总结:添加where限制条件,让查询飞快,不添加where条件的时候,mysql会将前40000条数据全部读取一遍,然后获取后面的20条数据,添加where限制条件就不会,效率会高出很多,当然变态测试,主要是看效果。
3,其他小技巧:
select 的字段最好不要添加索引,select id from text limit 10000,20;在id添加索引后效率明显降低。
尽可能多的占用浏览器连接,比如新浪、比如人人网首页上的文件都存放在好多域名下,比如a.sina.com.cn、b.sina.com.cn、d.sinacom.cn等等,因为浏览器默认为每个域名打开固定的连接数,ie6为打开两个,ie7增加到四个,域名用的越多,站的连接数越多,相当于加载的线程越多,速度当然就要快。















 6931
6931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









