









一、K-means算法(K-means++)
1、随机生成K个种子点。
2、将待聚类的所有点与K个种子点进行距离运算。
3、根据最短距离进行分类,然后移动种子点到本次聚类后,各个簇的中心。
4、迭代2、3直至种子点位置不变。
K-means++是对步骤1中的K进行更加详细的计算,而不是人为给定。
二、贝叶斯分类
这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率: 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
1、朴素贝叶斯分类(特征属性必须有条件独立或基本独立)
整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。

2、贝叶斯网络
现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。
贝叶斯网络主要用于概率推理及决策,具体来说,就是在信息不完备的情况下通过可以观察随机变量推断不可观察的随机变量,并且不可观察随机变量可以多于以一个,一般初期将不可观察变量置为随机值,然后进行概率推理。
1、对所有可观察随机变量节点用观察值实例化;对不可观察节点实例化为随机值。
2、对DAG进行遍历,对每一个不可观察节点y,计算,其中wi表示除y以外的其它所有节点,a为正规化因子,sj表示y的第j个子节点。
3、使用第三步计算出的各个y作为未知节点的新值进行实例化,重复第二步,直到结果充分收敛。
4、将收敛结果作为推断值。
3、分类算法——决策树(decision tree)。
相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置,因此在实际应用中,对于探测式的知识发现,决策树更加适用。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
ID3算法
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
而信息增益即为两者的差值:
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。
C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法首先定义了“分裂信息”,其定义可以表示成:
其中各符号意义与ID3算法相同,然后,增益率被定义为:
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
其他问题:多数表决和减枝。三、KNN算法
1、何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1时,算法便成了最近邻算法,即寻找最近的那个邻居。为何要找邻居?打个比方来说,假设你来到一个陌生的村庄,现在你要找到与你有着相似特征的人群融入他们,所谓入伙。
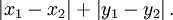 ,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。曼哈顿距离也称为城市街区距离(City Block distance)。
,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。曼哈顿距离也称为城市街区距离(City Block distance)。
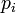 及
及
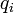 ,则两者之间的切比雪夫距离定义如下:
,则两者之间的切比雪夫距离定义如下:
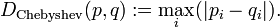 ,
,
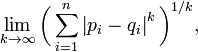 ,因此切比雪夫距离也称为L∞度量。
,因此切比雪夫距离也称为L∞度量。
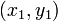 及
及
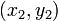 ,则切比雪夫距离为:
,则切比雪夫距离为:
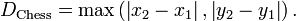 。
。
(1) 闵氏距离的定义两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为: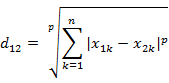 其中p是一个变参数。当p=1时,就是曼哈顿距离当p=2时,就是欧氏距离当p→∞时,就是切比雪夫距离根据变参数的不同,闵氏距离可以表示一类的距离。
其中p是一个变参数。当p=1时,就是曼哈顿距离当p=2时,就是欧氏距离当p→∞时,就是切比雪夫距离根据变参数的不同,闵氏距离可以表示一类的距离。
(4)标准化欧式距离(加权欧式距离)
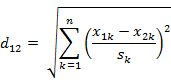
(5)马氏距离
马氏距离的优缺点:量纲无关,排除变量之间的相关性的干扰。
(6)巴氏距离(Bhattacharyya Distance),在统计中,Bhattacharyya距离测量两个离散或连续概率分布的相似性。
五、KD树:空间划分树。
1. 凸集,凸函数,凹集,凹函数的概念
2. Jensen's inequality
3. EM算法两步迭代过程与收敛性证明
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









