







聚合操作——combineByKey
当数据集一键值对形式组织的时候,聚合具有相同键的元素进行一些统计是很常见的操作。对于Pair RDD常见的聚合操作如:reduceByKey,foldByKey,groupByKey,combineByKey。这里重点要说的是combineByKey。
在数据分析中,处理Key,Value的Pair数据是极为常见的场景,例如我们可以针对这样的数据进行分组、聚合或者将两个包含Pair数据的RDD根据key进行join。从函数的抽象层面看,这些操作具有共同的特征,都是将类型为RDD[(K,V)]的数据处理为RDD[(K,C)]。这里的V和C可以是相同类型,也可以是不同类型。这种数据处理操作并非单纯的对Pair的value进行map,而是针对不同的key值对原有的value进行联合(Combine)。因而,不仅类型可能不同,元素个数也可能不同。
combineByKey函数主要接受了三个函数作为参数,分别为createCombiner、mergeValue、mergeCombiners。这三个函数足以说明它究竟做了什么。理解了这三个函数,就可以很好地理解combineByKey。
要理解combineByKey(),要先理解它在处理数据时是如何处理每个元素的。由于combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的键相同。combineByKey()的处理流程如下:
如果是一个新的元素,此时使用createCombiner()来创建那个键对应的累加器的初始值。(!注意:这个过程会在每个分区第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生。)
如果这是一个在处理当前分区中之前已经遇到键,此时combineByKey()使用mergeValue()将该键的累加器对应的当前值与这个新值进行合并。
3.由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()将各个分区的结果进行合并。
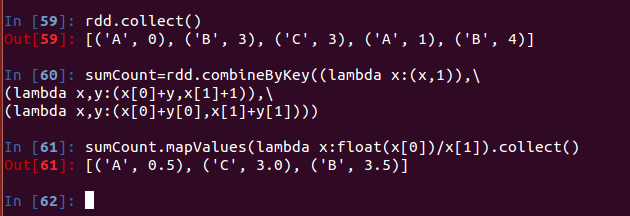
示例:















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









