








作者:橘子派
声明:版权所有,转载请注明出处,谢谢。
实验环境:
Windows10
Sublime
Anaconda 1.6.0
Python3.6
代码功能包括:
一.ubyte数据集转换成csv形式
#将mnist数据集转换成CSV格式
import struct
def to_csv(name,maxdata):
lbl_f = open("./data/"+name+"-labels.idx1-ubyte","rb")
#打开标签数据集
img_f = open("./data/"+name+"-images.idx3-ubyte","rb")
#打开图像数据集
csv_f = open("./data/"+name+",csv","w",encoding="utf-8")
#写入CSV文件
mag,lbl_count=struct.unpack(">II",lbl_f.read(8))
#将字节流转换成python数据类型复制给标签
mag,img_count=struct.unpack(">II",img_f.read(8))
#将字节流转换成python数据类型复制给图像
rows,cols=struct.unpack(">II",img_f.read(8))
#将字节流转换成python数据类型复制给行列
pixels=rows*cols
#计算数据总量
res=[]
for idx in range(lbl_count):
if idx > maxdata:break
#设置计数器,大于数据个数总量时跳出循环
label=struct.unpack("B",lbl_f.read(1))[0]
bdata=img_f.read(pixels)
sdata=list(map(lambda n:str(n),bdata))
csv_f.write(str(label)+",")
#写入标签
csv_f.write(",".join(sdata)+"\r\n")
#写入数据(数字)
if idx < 10:
s="P2 28 28 255\n"
s+=" ".join(sdata)
iname="./data/{0}-{1}-{2}.pgm".format(name,idx,label)
with open(iname,"w",encoding="utf-8") as f:
f.write(s)
csv_f.close()
#关闭CSV流
lbl_f.close()
#关闭标签流
img_f.close()
#关闭图像流
to_csv("train",1000)
#转换到train.csv 1000个数据
to_csv("t10k",1000)
#转换到t10k.csv 1000个数据
二.用sklearn的交叉验证处理数据,SVM训练数据预测结果,metrics生成分类报告和准确率
#用sklearn中的SVM来训练模型,预测数据集
from sklearn import cross_validation,svm,metrics
def load_csv(fname):
labels=[]
images=[]
with open(fname,"r") as f:
for line in f:
cols=line.split(",")
if len(cols)<2:continue
labels.append(int(cols.pop(0)))
vals=list(map(lambda n: int(n) / 256,cols))
images.append(vals)
return {"labels":labels,"images":images}
data=load_csv("./data/train.csv")
test=load_csv("./data/t10k.csv")
clf=svm.SVC()
clf.fit(data["images"],data["labels"])
#训练数据集
predict=clf.predict(test["images"])
#预测测试集
score=metrics.accuracy_score(test["labels"],predict)
#生成测试精度
report=metrics.classification_report(test["labels"],predict)
#生成交叉验证的报告
print(score)
#显示数据精度
print(report)
#显示交叉验证数据集报告
运行结果
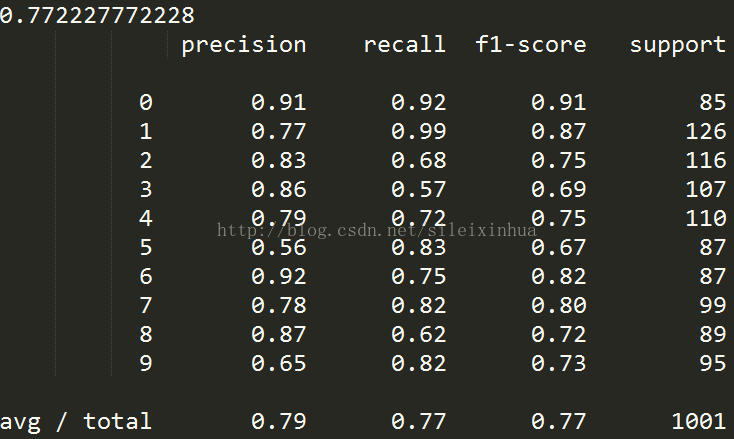
三组平均测试精度为0.772
参考文献:
《统计学习方法》
《
Web scraping and machine learning by python》
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









