







《Causal Inference in Python: Applying Causal Inference in the Tech Industry》因果推断啃书系列
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
《Causal Inference in Python》第5章 倾向得分
第5章 倾向得分
在第4章中,你学习了如何使用线性回归调整混杂因子。除此之外,还介绍了通过正交化去偏的概念,这是可用的最有用的偏差调整技术之一。然而,还有另一种技巧你需要学习—倾向加权。该技术涉及对干预分配机制进行建模,并使用模型的预测来重新加权数据,而不是像正交化那样构建残差。在本章中,你还将学习如何将第4章的原则与倾向加权相结合,以实现所谓的双重鲁棒性。
5.1 管理能力培训的作用
科技公司的一个常见现象是,有才华的个人贡献者(ICs)扩展到管理轨道。但由于管理需要的技能集合往往与让他们成为ICs的技能非常不同,这种过渡往往远非易事。不仅对新上任的管理者是这样,对他们管理的人来说,也会带来高昂的个人成本。
为了让这种转变不那么痛苦,一家大型跨国公司决定对新经理进行管理培训。此外,为了衡量培训的有效性,该公司试图随机选择经理参加该项目。他们的想法是,将那些参加了培训的经理的员工与那些没有参与培训的经理的员工的敬业度得分进行比较。通过适当的随机化,这种简单的比较将给出培训的平均干预效果。
不幸的是,事情并没有那么简单。一些经理不想去参加培训,所以他们根本就没有出现。其他人即使没有被分配接受培训,也设法获得了培训。结果是,原本是随机的研究最终看起来很像观察性研究。
不顺从性(Noncompliance)
人们没有得到他们想要的干预被称为不服从。当我们在第11章讨论工具变量时,你会看到更多相关内容。
现在,作为一名必须阅读这些数据的分析师,你必须通过调整混杂因子使干预组和未干预组具有可比性。为了做到这一点,你会得到关于公司经理们的数据以及一些描述他们的协变量:
# 初始化
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import graphviz as gr
from matplotlib import style
import seaborn as sns
from matplotlib import pyplot as plt
style.use("ggplot")
import statsmodels.formula.api as smf
import matplotlib
from cycler import cycler
color=['0.2', '0.6', '1.0']
default_cycler = (cycler(color=color))
linestyle=['-', '--', ':', '-.']
marker=['o', 'v', 'd', 'p']
plt.rc('axes', prop_cycle=default_cycler)
import pandas as pd
import numpy as np
df = pd.read_csv("data/management_training.csv")
df.head()
| departament_id | intervention | engagement_score | tenure | n_of_reports | gender | role | last_engagement_score | department_score | department_size | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 76 | 1 | 0.277359 | 6 | 4 | 2 | 4 | 0.614261 | 0.224077 | 843 |
| 1 | 76 | 1 | -0.449646 | 4 | 8 | 2 | 4 | 0.069636 | 0.224077 | 843 |
| 2 | 76 | 1 | 0.769703 | 6 | 4 | 2 | 4 | 0.866918 | 0.224077 | 843 |
| 3 | 76 | 1 | -0.121763 | 6 | 4 | 2 | 4 | 0.029071 | 0.224077 | 843 |
| 4 | 76 | 1 | 1.526147 | 6 | 4 | 1 | 4 | 0.589857 | 0.224077 | 843 |
干预变量是intervention,你感兴趣的结果是engagement_score,就是该经理的员工的平均标准化敬业得分。除干预和结果外,本数据中的协变量为:
- department_id
部门的唯一标识符 - tenure
经理在公司任职的年数(作为员工的工作年数,不是指成为经理的年数) - n_of_reports
经理拥有的报告数量 - gender
经理性别对应的分类变量 - role
公司内部的工作类别 - department_size
同一部门的雇员人数 - department_score
同一部门的平均敬业度得分 - last_engagement_score
该经理在之前的敬业度调查中获得的平均敬业度分数
你希望,通过控制部分或所有这些变量,你可能会设法减少甚至消除估算管理培训和员工敬业度之间的因果关系的偏差。
模拟数据
这个数据集改编自Susan Athey和Stefan Wager在研究《用因果森林估计治疗效果:一个应用》(Estimating Treatment Effects with Causal Forests: An Application)中使用的数据集。
5.2 使用回归进行调整
在讨论倾向加权之前,让我们回顾一下如何使用回归来调整混杂因子。一般来说,当学习新东西时,有一些你信任的基准来作为比较总是一个好主意。这里的想法是检查倾向加权估算是否至少与回归估算一致。现在,让我们开始吧。
首先,如果你简单地比较干预组和对照组,你会得到这样的结果:
import statsmodels.formula.api as smf
smf.ols("engagement_score ~ intervention",
data=df).fit().summary().tables[1]
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -0.2347 | 0.014 | -16.619 | 0.000 | -0.262 | -0.207 |
| intervention | 0.4346 | 0.019 | 22.616 | 0.000 | 0.397 | 0.472 |
但话又说回来,这个结果可能是有偏差的,因为干预不是完全随机的。为了减少这种偏差,你可以对数据中的协变量进行调整,估算以下模型:
e n g a g e m e n t i = τ T i + θ X i + e i engagement_i=\tau T_i +\theta X_i +e_i engagementi=τTi+θXi+ei
其中 X X X 是所有的混杂因子加上一个作为截距的常数列。此外,性别gender和角色role都是分类变量,所以你必须将它们封装在OLS模块中的C()函数中:
model = smf.ols("""engagement_score ~ intervention
+ tenure + last_engagement_score + department_score
+ n_of_reports + C(gender) + C(role)""", data=df).fit()
print("ATE:", model.params["intervention"])
print("95% CI:", model.conf_int().loc["intervention", :].values.T)
ATE: 0.2677908576676856
95% CI: [0.23357751 0.30200421]
注意这里的效果估算值比你之前得到的要小得多。这在一定程度上表明了正值偏差,这意味着那些下属员工更投入的经理更有可能参加管理培训项目。好了,序言就到此为止。我们来看看倾向加权是关于什么的。
5.3 倾向得分(Propensity Score)
倾向加权围绕着倾向得分的概念展开,来源于这样一个认识:不需要直接控制混杂因子
X
X
X 就能实现条件独立性
(
Y
1
,
Y
0
)
⊥
T
∣
X
(Y_1,Y_0) \perp T|X
(Y1,Y0)⊥T∣X。相反,控制估算
E
(
T
∣
X
)
E(T|X)
E(T∣X) 的平衡得分(balancing score)就足够了。这种平衡得分通常是干预的条件概率
P
(
T
∣
X
)
P(T|X)
P(T∣X),也称为倾向得分(Propensity Score)
e
(
x
)
e(x)
e(x)。
倾向得分可以被视为一种降维技术。不是对可能是高基维的 X X X 设定条件,而是你可以简单地对倾向得分设置条件,以阻止后门路径通过 X X X: ( Y 1 , Y 0 ) ⊥ T ∣ P ( x ) (Y_1,Y_0) \perp T|P(x) (Y1,Y0)⊥T∣P(x)。
这里有一个正式的证明。并不复杂,但有点超出了本书的范围。在这里,你可以用一种更直观的方式来处理这个问题。倾向得分是接受干预的条件概率,所以你可以把它想象成某种转化 X X X 为干预 T T T 的函数。倾向得分创建了变量 X X X 和干预 T T T 之间的中间地带。这是它在因果图中的样子:
g = gr.Digraph(graph_attr={"rankdir":"LR"})
g.edge("T", "Y")
g.edge("X", "Y")
g.edge("X", "e(x)")
g.edge("e(x)", "T")
g
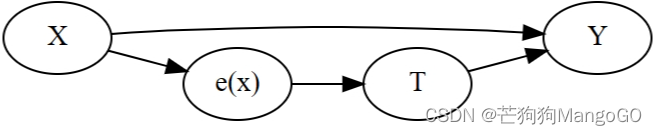
在这个图形中,如果你知道 e ( x ) e(x) e(x) 什么是, X X X 就不能单独提供关于 T T T 的进一步信息。这意味着控制 e ( x ) e(x) e(x) 和直接控制 X X X 的作用是一样的。
从管理培训计划的角度来考虑,干预组和非干预组最初是不可比较的,因为有更多直接参与报告的经理更有可能参与培训。然而,如果你取两个管理人员,一个来自被干预组,一个来自对照组,但接受干预的概率相同,他们是有可比性的。想想看,如果他们接受干预的概率完全相同,实际他们一个接受了,而另一个没有,唯一的原因是纯粹的偶然。给定相同的倾向得分,干预就像是随机的了。
5.3.1 倾向分数估算
在理想世界中,你可能会得到真实的倾向得分 e ( x ) e(x) e(x)。在条件随机实验的情况下分配机制是已知不确定的,可能会有这种情况。然而,在大多数情况下,分配干预的机制是未知的,你需要用 e ( x ) e(x) e(x) 的估算值来取代真实的倾向得分。
由于你使用的是二元干预,估算 e ( x ) e(x) e(x) 的一个很好的候选方法是逻辑回归。要使用statmodel拟合逻辑回归,可以简单地将方法ols更改为logit:
ps_model = smf.logit("""intervention ~
tenure + last_engagement_score + department_score
+ C(n_of_reports) + C(gender) + C(role)""", data=df).fit(disp=0)
将你估算的倾向得分保存在一个数据框(dataframe)中;你将在下面的内容部分中大量使用这个数据,我将向你展示如何使用这个数据以及它在做什么:
data_ps = df.assign(
propensity_score = ps_model.predict(df),
)
data_ps[["intervention", "engagement_score", "propensity_score"]].head()
| intervention | engagement_score | propensity_score | |
|---|---|---|---|
| 0 | 1 | 0.277359 | 0.596106 |
| 1 | 1 | -0.449646 | 0.391138 |
| 2 | 1 | 0.769703 | 0.602578 |
| 3 | 1 | -0.121763 | 0.580990 |
| 4 | 1 | 1.526147 | 0.619976 |
倾向得分与机器学习
或者,你可以使用机器学习模型来估算倾向得分。但你要更加小心。首先,你必须确保ML模型输出一个经过校准的概率预测。其次,需要使用折外预测(out-of-fold),以避免由于过拟合而产生的偏差。对于第一个任务,可以使用sklearn的校准模块calibration,对于后一个任务,可以使用模型选择模块中的cross_val_predict函数。
5.3.2 倾向得分与正交化
如果你回想一下前一章,根据FLW定理,线性回归也可以做一些非常类似于估算倾向得分的事情。在去偏步骤中,回归对 E ( T ∣ X ) E(T|X) E(T∣X) 进行估算。因此,就像倾向得分估算一样,OLS也对干预分配机制进行建模。这意味着你也可以在线性回归中使用倾向得分 e ( x ) e(x) e(x),以调整混杂因子 X X X:
model = smf.ols("engagement_score ~ intervention + propensity_score",
data=data_ps).fit()
model.params["intervention"]
0.26331267490277066
你用这种方法得到的ATE估算与你之前用干预和混淆因子拟合一个线性模型得到的结果非常相似。这一点也不奇怪,因为这两种方法都是是将干预正交化。唯一不同的是,OLS使用线性回归来建模,而这个倾向得分估算是通过逻辑回归得到的。
5.3.3 倾向得分匹配
控制倾向得分的另一种流行方法是匹配估算。这种方法搜索具有类似可观察特征的单元对,并将接受干预的人和未接受干预的人的结果进行比较。如果你有数据科学背景,可以将匹配视为一个简单的K-Nearest-Neighbors (KNN)算法,其中K=1。首先,你在干预的单元上拟合一个KNN模型,使用倾向得分作为唯一特征,并使用它来估算对照组的 Y 1 Y_1 Y1。接下来,在未干预的单元上拟合一个KNN模型,并使用它估算干预组的 Y 0 Y_0 Y0。在这两种情况下,估算值只是匹配单元的结果,其中匹配是基于倾向得分:
from sklearn.neighbors import KNeighborsRegressor
T = "intervention"
X = "propensity_score"
Y = "engagement_score"
treated = data_ps.query(f"{T}==1")
untreated = data_ps.query(f"{T}==0")
mt0 = KNeighborsRegressor(n_neighbors=1).fit(untreated[[X]],
untreated[Y])
mt1 = KNeighborsRegressor(n_neighbors=1).fit(treated[[X]], treated[Y])
predicted = pd.concat([
# find matches for the treated looking at the untreated knn model
treated.assign(match=mt0.predict(treated[[X]])),
# find matches for the untreated looking at the treated knn model
untreated.assign(match=mt1.predict(untreated[[X]]))
])
predicted.head()
| departament_id | intervention | engagement_score | tenure | n_of_reports | gender | role | last_engagement_score | department_score | department_size | propensity_score | match | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 76 | 1 | 0.277359 | 6 | 4 | 2 | 4 | 0.614261 | 0.224077 | 843 | 0.596106 | 0.557680 |
| 1 | 76 | 1 | -0.449646 | 4 | 8 | 2 | 4 | 0.069636 | 0.224077 | 843 | 0.391138 | -0.952622 |
| 2 | 76 | 1 | 0.769703 | 6 | 4 | 2 | 4 | 0.866918 | 0.224077 | 843 | 0.602578 | -0.618381 |
| 3 | 76 | 1 | -0.121763 | 6 | 4 | 2 | 4 | 0.029071 | 0.224077 | 843 | 0.580990 | -1.404962 |
| 4 | 76 | 1 | 1.526147 | 6 | 4 | 1 | 4 | 0.589857 | 0.224077 | 843 | 0.619976 | 0.000354 |
一旦你有每个单位的匹配结果,你可以估算ATE:
A T E ^ = 1 N ∑ [ ( Y i − Y j m ( i ) ) T i + ( Y j m ( i ) − Y i ) ( 1 − T i ) ] \widehat{ATE}=\frac{1}{N}\sum{[(Y_i-Y_{jm}(i))T_i +(Y_{jm}(i)-Y_i)(1-T_i)]} ATE =N1∑[(Yi−Yjm(i))Ti+(Yjm(i)−Yi)(1−Ti)]
其中 Y j m ( i ) Y_{jm}(i) Yjm(i) 是单元 i i i 从另外一个组获取的匹配:
np.mean((predicted[Y] - predicted["match"])*predicted[T]
+ (predicted["match"] - predicted[Y])*(1-predicted[T]))
0.28777443474045966
匹配估算的偏差
你不需要只使用倾向得分进行匹配。相反,你可以直接匹配用于构建倾向得分估算 P ^ ( T ∣ X ) \hat{P}(T|X) P^(T∣X) 的原始特征 X X X。但是,这样的匹配估算量是有偏差的,且这种偏差随着 X X X 的维数的增加而增加。维数越高,数据越稀疏,匹配越差。设 μ 0 ( X ) \mu_0(X) μ0(X) 和 μ 1 ( X ) \mu_1(X) μ1(X) 分别为对照组和干预组的预期结果函数。偏差是预期结果与匹配结果之间的差异: μ 0 ( X i ) − μ 0 ( X j m ) \mu_0(X_i)-\mu_0(X_{jm}) μ0(Xi)−μ0(Xjm) 是干预单元的偏差, μ 1 ( X j m ) − μ 1 ( X i ) \mu_1(X_{jm})-\mu_1(X_i) μ1(Xjm)−μ1(Xi) 是对照单元的偏差,其中 X j m X_{jm} Xjm 是匹配的协变量。
这意味着,如果你想使用匹配但避免其偏差,你必须应用一个偏差修正项:
A T E ^ = 1 N ∑ { ( Y i − Y j m ( i ) − ( μ ^ 0 ( X i ) − μ ^ 0 ( X j m ) ) ) T i + ( Y j m ( i ) − Y i − ( μ ^ 1 ( X j m ) − μ ^ 1 ( X i ) ) ) ( 1 − T i ) } \begin{aligned} \widehat{ATE}&=\frac{1}{N} \sum{\{ (Y_i -Y_{jm}(i) -( \widehat \mu_0(X_i) -\widehat \mu_0(X_{jm}) ) )T_i }\\ &\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ +(Y_{jm}(i)-Y_i -( \widehat \mu_1(X_{jm}) -\widehat \mu_1(X_i)) )(1-T_i) \} \end{aligned} ATE =N1∑{(Yi−Yjm(i)−(μ 0(Xi)−μ 0(Xjm)))Ti +(Yjm(i)−Yi−(μ 1(Xjm)−μ 1(Xi)))(1−Ti)}
其中 μ ^ 1 \widehat \mu_1 μ 1 和 μ ^ 0 \widehat \mu_0 μ 0 可以使用线性回归进行估算。
完全诚实地说,我不是这个估算器的超级粉丝,首先它是有偏差的,其次很难推导出它的方差,第三我在数据科学方面的经验让我对KNN持怀疑态度,主要是因为它在高维 X X X 情况下效率非常低。如果你只匹配倾向得分,最后一个问题就不是问题,但前两个问题仍然存在。我在这里讲这个方法主要是因为它很有名,你们可能别的地方也看到过。
另请参阅
King和Nielsen的论文《为什么倾向得分不应该用于匹配》(Why Propensity Scores Should Not Be Used for Matching),对倾向得分匹配问题进行了更技术性的讨论。
5.3.4 逆倾向加权
我发现另一种广泛使用的利用倾向得分的方法是反向倾向加权(IPW)。该方法根据干预的反概率对数据进行重新加权,使干预在重新加权后的数据中看起来像是随机分配的。为了做到这一点,我们重新调整了样本的权重 1 / P ( T = t ∣ X ) 1/P(T=t|X) 1/P(T=t∣X),以创建一个伪群体(pseudo-population),接近如果每个人都接受了干预 T T T 会发生的情况:
E ( Y i ) = E [ 1 ( T = t ) Y P ( T = t ∣ X ) ] E(Y_i)=E\left[ \frac{1(T=t)Y}{P(T=t|X)} \right] E(Yi)=E[P(T=t∣X)1(T=t)Y]
同样,这个公式的证明并不复杂,但这不是重点。我们还是用直觉吧。假设你想知道 Y 1 Y_1 Y1 的期望,也就是所有经理都接受了培训的情况下的平均敬业度。为了得到这个结果,你把所有接受培训的人都乘上获得培训的概率倒数。这让那些干预概率很低的但实际获得干预的人得到了很高的权重。你实际上是在给罕见的干预案例增加权重。
这说得通,对吧?如果一个接受干预的人得到干预的概率很低,那么这个人看起来就和没有接受干预的人很像。这一定很有趣!这个干预过的单元看起来像未干预过,可能会提供很多信息关于未干预过的人若被干预会发生什么, Y 1 ∣ T = 0 Y_1|T=0 Y1∣T=0。这就是为什么你给这个单元很高的权重。对照组也是一样。如果一个对照单元看起来很像是干预组的,它可能是一个很好的 Y 0 ∣ T = 1 Y_0|T=1 Y0∣T=1 的估算,所以你给它更高的权重。
以下是在管理培训数据开展上面这个过程的情况,每个点的大小表示权重的大小:
g_data = (data_ps
.assign(
weight = data_ps["intervention"]/data_ps["propensity_score"] + (1-data_ps["intervention"])/(1-data_ps["propensity_score"]),
propensity_score=data_ps["propensity_score"].round(2)
)
.groupby(["propensity_score", "intervention"])
[["weight", "engagement_score"]]
.mean()
.reset_index())
plt.figure(figsize=(10,4))
for t in [0, 1]:
sns.scatterplot(data=g_data.query(f"intervention=={t}"), y="engagement_score", x="propensity_score", size="weight",
sizes=(1,100), color=color[t], legend=None, label=f"T={t}", marker=marker[t])
plt.title("Inverse Probability of Treatment Weighting")
plt.legend()
<matplotlib.legend.Legend at 0x7ff2110ed750>
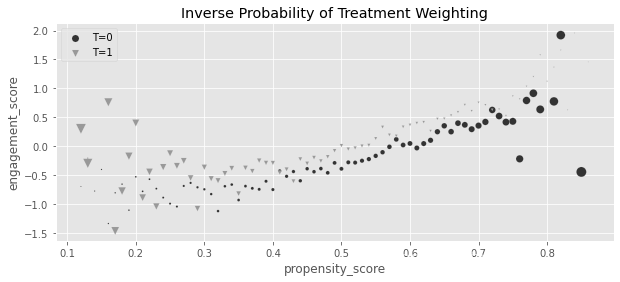
请注意,那些受过培训的经理, T = 1 T=1 T=1,在 e ^ ( X ) \hat e(X) e^(X) 低的时候拥有高权重。你对那些看起来像是未干预的但实际被干预的人给予了高度重视。相反,未干预的人在 e ^ ( X ) \hat e(X) e^(X) 高时,或者说 P ^ ( T = 0 ∣ X ) \hat P(T=0|X) P^(T=0∣X) 低时,拥有高权重。此时,你非常重视那些看起来像是被干预过实际未干预的人。
如果你可以使用倾向得分来恢复平均潜在结果,这也意味着你可以使用它来恢复ATE:
A T E = E [ 1 ( T = 1 ) Y P ( T = 1 ∣ X ) ] − E [ 1 ( T = 0 ) Y P ( T = 0 ∣ X ) ] ATE=E \left[ \frac{1(T=1)Y}{P(T=1|X)} \right] - E \left[ \frac{1(T=0)Y}{P(T=0|X)} \right] ATE=E[P(T=1∣X)1(T=1)Y]−E[P(T=0∣X)1(T=0)Y]
这两个期望都可以通过非常简单的代码从数据中估算:
weight_t = 1/data_ps.query("intervention==1")["propensity_score"]
weight_nt = 1/(1-data_ps.query("intervention==0")["propensity_score"])
t1 = data_ps.query("intervention==1")["engagement_score"]
t0 = data_ps.query("intervention==0")["engagement_score"]
y1 = sum(t1*weight_t)/len(data_ps)
y0 = sum(t0*weight_nt)/len(data_ps)
print("E[Y1]:", y1)
print("E[Y0]:", y0)
print("ATE", y1 - y0)
E[Y1]: 0.11656317232946772
E[Y0]: -0.1494155364781444
ATE 0.2659787088076121
使用这种方法,ATE再次比你天真地得到的那个小,没有调整 X X X。此外,这个结果看起来与你通过使用OLS得到的结果非常相似,这是一个很好的检查确保您没有做错任何事情。还值得注意的是,ATE表达式可以简化为:
A T E = E [ Y T − e ( x ) e ( x ) ( 1 − e ( x ) ) ] ATE=E \left[ Y \frac{T-e(x)}{e(x)(1-e(x))} \right] ATE=E[Ye(x)(1−e(x))T−e(x)]
果然,它产生了与之前完全相同的结果:
np.mean(data_ps["engagement_score"]
* (data_ps["intervention"] - data_ps["propensity_score"])
/ (data_ps["propensity_score"]*(1-data_ps["propensity_score"])))
0.26597870880761226
回归与IPW
前面的公式非常巧妙,它也让你对IPW与回归的比较有了一些了解。使用回归,你正在恢复干预效果
τ o l s = E [ Y ( T − E ( T ∣ X ) ) ] E [ V a r ( T ∣ X ) ] \tau_{ols}=\frac{E[Y(T-E(T|X))]} {E[Var(T|X)]} τols=E[Var(T∣X)]E[Y(T−E(T∣X))]
记住这一点,回想一下概率是 p p p 的伯努利变量的方差就是简单的 p ( 1 − p ) p(1-p) p(1−p),因此,IPW使用下面的公式恢复干预效果:
τ i p w = E [ Y ( T − E ( T ∣ X ) ) V a r ( T ∣ X ) ] \tau_{ipw}=E \left[ \frac{Y(T-E(T|X))} {Var(T|X)} \right] τipw=E[Var(T∣X)Y(T−E(T∣X))]
注意到其中的相似性了吗?为了使它更透明,由于 1 / E [ V a r ( T ∣ X ) ] 1/E[Var(T|X)] 1/E[Var(T∣X)] 是一个常量,你可以将它移动到期望中,并将回归估算量重写如下:
τ o l s = E [ Y ( T − E ( T ∣ X ) ) E [ V a r ( T ∣ X ) ] ] = E [ Y ( T − E ( T ∣ X ) ) V a r ( T ∣ X ) ∗ W ] \tau_{ols}=E \left[ \frac{Y(T-E(T|X))} {E[Var(T|X)]} \right] =E \left[ \frac{Y(T-E(T|X))} {Var(T|X)} *W \right] τols=E[E[Var(T∣X)]Y(T−E(T∣X))]=E[Var(T∣X)Y(T−E(T∣X))∗W]
其中 W = V a r ( T ∣ X ) / E [ V a r ( T ∣ X ) ] W=Var(T|X)/E[Var(T|X)] W=Var(T∣X)/E[Var(T∣X)]
现在,在IPW估算量的期望内的东西确定了 X X X 定义的分组的影响(CATE)。因此,IPW与OLS的差值是第一次对每个样本加权1,而回归则是通过条件干预方差对分组效果进行加权。这与你在前一章中所学到的内容一致,关于回归加权效应,干预差异很大。因此,尽管回归和IPW看起来不同,但它们在加权点上做的事情几乎是一样的。
5.3.5 IPW的方差
不幸的是,计算IPW的标准误差不像线性回归那样简单。获取IPW估算值的置信区间最直接的方法是使用自助法(bootstrap)。使用这种方法,你将重复地对数据进行重新采样并进行替换,以获得多个IPW估算量。然后,你可以计算这些估算值的2.5和97.5百分位作为95%的置信区间。
为了编写代码,让我们首先将IPW估算值封装到一个可重复使用的函数中。注意我是如何用sklearn替换statsmodels的。statmodel中的logit函数比sklearn中的logistic回归模型慢,所以这个变化将节省你的时间。此外,由于你可能不想失去从statmodel中获得公式的方便性,可以使用patsy的dmatrix函数。这个函数基于R语言模块工程化了一个特征矩阵,就像你到目前为止一直在使用的公式:
from sklearn.linear_model import LogisticRegression
from patsy import dmatrix
# define function that computes the IPW estimator
def est_ate_with_ps(df, ps_formula, T, Y):
X = dmatrix(ps_formula, df)
ps_model = LogisticRegression(penalty="none",
max_iter=1000).fit(X, df[T])
ps = ps_model.predict_proba(X)[:, 1]
# compute the ATE
return np.mean((df[T]-ps) / (ps*(1-ps)) * df[Y])
概率预测
默认情况下,sklearn的分类器是根据逻辑 P ^ ( Y ∣ X ) > 0.5 \hat P(Y|X)>0.5 P^(Y∣X)>0.5 输出结果为0或1的预测。因为你希望模型输出一个概率,所以必须使用predict_proba方法。这个方法输出一个两列的矩阵,其中第一列是 P ^ ( Y = 0 ∣ X ) \hat P(Y=0|X) P^(Y=0∣X),第二列是 P ^ ( Y = 1 ∣ X ) \hat P(Y=1|X) P^(Y=1∣X)。你只需要第二列,因此索引为[:,1]。
下面演示如何使用这个函数:
formula = """tenure + last_engagement_score + department_score
+ C(n_of_reports) + C(gender) + C(role)"""
T = "intervention"
Y = "engagement_score"
est_ate_with_ps(df, formula, T, Y)
0.2659755621752663
现在你已经有了在一个简洁的函数中计算ATE的代码,可以在一个自助法的过程中进行应用。为了加快速度,我还将并行运行重采样。你所要做的就是调用数据框(dataframe)方法.sample(frac=1, replace=True)来获得一个自助法样本。然后,将这个样本传递给前面创建的函数。为了使自助法代码更通用,它的一个参数是一个估算函数est_fn,它接受一个数据框(dataframe)并返回一个数字作为估算值。我使用了四个进程,你可以随意将其设置为你的计算机中的核心数量。
每个自助法样本中运行一次估算器,多个样本将得到一个估算数组。最后,要得到95%的CI,只需取该数组的2.5和97.5百分位:
from joblib import Parallel, delayed # for parallel processing
def bootstrap(data, est_fn, rounds=200, seed=123, pcts=[2.5, 97.5]):
np.random.seed(seed)
stats = Parallel(n_jobs=4)(
delayed(est_fn)(data.sample(frac=1, replace=True))
for _ in range(rounds)
)
return np.percentile(stats, pcts)
在我的代码中,我倾向于函数式编程,这可能不是每个人都熟悉的。出于这个原因,我将添加注释来解释我正在使用的一些函数,从partial函数开始。
partial
partial接受一个函数和它的一些参数,将这些参数应用到输入函数,并返回另一个和输入函数相似的函数:def addNumber(x, number): return x + number add2 = partial(addNumber, number=2) add4 = partial(addNumber, number=4) add2(3) >>> 5 add4(3) >>> 7
我将使用partial获取est_ate_with_ps函数,并部分应用公式(formula)、干预和结果参数。这将输出一个函数,以一个数据框作为唯一输入,并输出ATE的估算值。然后,我可以将这个函数作为est_fn参数传递给我之前创建的自助法函数:
from toolz import partial
print(f"ATE: {est_ate_with_ps(df, formula, T, Y)}")
est_fn = partial(est_ate_with_ps, ps_formula=formula, T=T, Y=Y)
print(f"95% C.I.: ", bootstrap(df, est_fn))
ATE: 0.2659755621752663
95% C.I.: [0.22654315 0.30072595]
这个95%和你之前用线性回归得到的差不多。重要的是要意识到,如果权重很大,倾向得分估算值的方差就会很大。较大的权重意味着一些单元在最终估算中有较大的影响。在最终估算值有很大影响的少数单元正是导致这样的方差的原因。
如果你在倾向得分高的区域有几个对照单元,或者在倾向得分低的区域有几个处理单元,你就会有很大的权重。这将导致你只有很少的单元来估算反事实 Y 0 ∣ T = 1 Y_0|T=1 Y0∣T=1 和 Y 1 ∣ T = 0 Y_1|T=0 Y1∣T=0,这可能会给你一个非常嘈杂的结果。
因果上下文强盗(Contextual bandits)
上下文强盗是一种强化学习,其目标是学习可选的决策策略。它合并了一个采样部分(在未开发区域收集数据与分配最佳干预之间取得平衡)和一个估算部分(试图利用可用数据找出最佳干预方法)。
估算部分可以很容易地划分为因果推理问题,你希望学习最佳干预分配机制,其中最佳是根据你希望优化的预期结果 Y Y Y 的期望值定义的。由于算法的目标是以最优的方式分配干预,因此它收集的数据是混杂的(而不是随机的)。这就是为什么上下文强盗的因果方法可以产生显著的改进。
如果决策过程是概率性的,则可以存储分配每个干预的概率,即倾向得分。然后,你可以使用这个倾向评分来重新加权过去的数据,在这些数据中,已经选择了干预方法,并且已经观察到了结果。这些重新加权的数据应该是不混淆的,因此更容易了解什么是最佳干预。
5.3.6 稳定倾向权重
使用 1 / P ( T = 1 ∣ X ) 1/P(T=1|X) 1/P(T=1∣X) 对干预过的样本进行加权,创建了一个与原始样本大小相同的伪群体,其中每个单元都好像被干预过一样。这意味着权重之和与原始样本量大致相同。同样,通过创建一个伪群体,使用 1 / P ( T = 0 ∣ X ) 1/P(T=0|X) 1/P(T=0∣X) 给对照组进行加权,就好像每个单元都未被干预一样。
如果你有机器学习背景,可能会认识到IPW是重要性抽样的一个应用。假设你有来自原始分布 q ( x ) q(x) q(x) 的数据,但希望从目标分布 p ( x ) p(x) p(x) 中抽样,就可以使用重要性抽样。为了实现这个目标,你可以将数据的权重由 q ( x ) q(x) q(x) 重新加权为 p ( x ) / q ( x ) p(x)/q(x) p(x)/q(x)。将这个应用到IPW场景,使用 1 / P ( T = 1 ∣ X ) 1/P(T=1|X) 1/P(T=1∣X) 给干预加权本质上意味着你正在从 P ( T = 1 ∣ X ) P(T=1|X) P(T=1∣X) 获取数据,
在IPW的背景下,用 1 / P ( T = 1 ∣ X ) 1/P(T=1|X) 1/P(T=1∣X) 对干预过的数据进行加权,本质上意味着你从 P ( T = 1 ∣ X ) P(T=1|X) P(T=1∣X) 中获得数据(如果 X X X 影响 Y Y Y,会有偏差的),并使得 P ( T = 1 ) = 1 P(T=1)=1 P(T=1)=1,其中干预概率不依赖于 X X X,因为它就是1。这也解释了为什么重新加权的结果样本表现为好像原始样本中的每个人都得到了干预。
另一种方法是弄清楚为什么干预组和未干预组的权重之和与原始样本量相当接近:
print("Original Sample Size", data_ps.shape[0])
print("Treated Pseudo-Population Sample Size", sum(weight_t))
print("Untreated Pseudo-Population Sample Size", sum(weight_nt))
Original Sample Size 10391
Treated Pseudo-Population Sample Size 10435.089079197916
Untreated Pseudo-Population Sample Size 10354.298899788304
只要你的权重不太大,一切都好。但如果干预非常不可能发生,即 P ( T ∣ X ) P(T|X) P(T∣X) 可能很小,这可能会给你带来一些计算问题。一个简单的解决方案是使用干预的边际概率 P ( T = t ) P(T=t) P(T=t) 来稳定权重:
ω = P ( T = t ) P ( T = t ∣ X ) \omega=\frac{P(T=t)}{P(T=t|X)} ω=P(T=t∣X)P(T=t)
有了这些权重,低概率的干预不会有巨大的权重,因为小分母将被小分子平衡。这不会改变你之前得到的结果,但它在计算上更稳定。
此外,稳定的权重重建了一个伪群体,其中干预组和对照组的有效大小(权重之和)分别与原始干预组和对照组的有效大小相匹配。再一次,类似重要性抽样,使用稳定的权重,你来自一个干预依赖于 X X X 的分布 P ( T = t ∣ X ) P(T=t|X) P(T=t∣X),但重定义为边际概率 P ( T = t ) P(T=t) P(T=t):
p_of_t = data_ps["intervention"].mean()
t1 = data_ps.query("intervention==1")
t0 = data_ps.query("intervention==0")
weight_t_stable = p_of_t/t1["propensity_score"]
weight_nt_stable = (1-p_of_t)/(1-t0["propensity_score"])
print("Treat size:", len(t1))
print("W treat", sum(weight_t_stable))
print("Control size:", len(t0))
print("W treat", sum(weight_nt_stable))
Treat size: 5611
W treat 5634.807508745978
Control size: 4780
W treat 4763.116999421415
同样,这种稳定性保持了原始倾向得分的相同平衡属性。你可以验证它的ATE与你之前的估算值完全相同:
nt = len(t1)
nc = len(t0)
y1 = sum(t1["engagement_score"]*weight_t_stable)/nt
y0 = sum(t0["engagement_score"]*weight_nt_stable)/nc
print("ATE: ", y1 - y0)
ATE: 0.26597870880761176
5.3.7 伪群体(Pseudo-Populations)
前面已经提到了伪群体,更好地理解伪群体,将有助于更好地理解IPW是如何消除偏差的。让我们先从 P ( T ∣ X ) P(T|X) P(T∣X) 的角度来思考偏差是什么。如果干预是随机分配,假设概率为10%,你知道干预将不会依赖 X X X,或者那个 P ( T ∣ X ) = P ( T ) = 10 P(T|X)=P(T)=10% P(T∣X)=P(T)=10。所以,如果干预独立于 X X X,通过 X X X 你就不会有混淆偏差,也就不需要调整。如果你确实有一些偏差,那么一些单元就有更高的机会得到干预。例如,那些非常热情的经理,他们已经拥有一个非常投入的团队,可能比那些不那么投入的团队的经理更有可能接受培训(拥有更高的 e ( T ) e(T) e(T))。
如果按照干预状态绘制 e ^ ( x ) \hat e(x) e^(x) 分布图,由于管理者没有相同的机会接受培训(治疗不是随机的),接受干预的个体将有更高的 e ^ ( x ) \hat e(x) e^(x) 。你可以在下面左边的图中看到,干预组 e ^ ( x ) \hat e(x) e^(x) 的分布有点向右移动:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5), sharex=True, sharey=True)
sns.histplot(data_ps.query("intervention==0")["propensity_score"], stat="probability",
label="Not Treated", color="C0", bins=30, ax=ax1, alpha=0.5)
sns.histplot(data_ps.query("intervention==1")["propensity_score"], stat="probability",
label="Treated", color="C2", alpha=0.5, bins=30, ax=ax1)
ax1.set_title("Propensity Distribution")
sns.histplot(data_ps.query("intervention==0").assign(w=weight_nt_stable),
x="propensity_score", stat="probability",
color="C0", weights="w", label="Non Treated", bins=30, ax=ax2, alpha=0.5)
sns.histplot(data_ps.query("intervention==1").assign(w=weight_t_stable),
x="propensity_score", stat="probability",
color="C2", weights="w", label="Treated", bins=30, alpha=0.5, ax=ax2)
ax2.set_title("Weighted Propensity Distribution")
plt.legend()
plt.tight_layout()
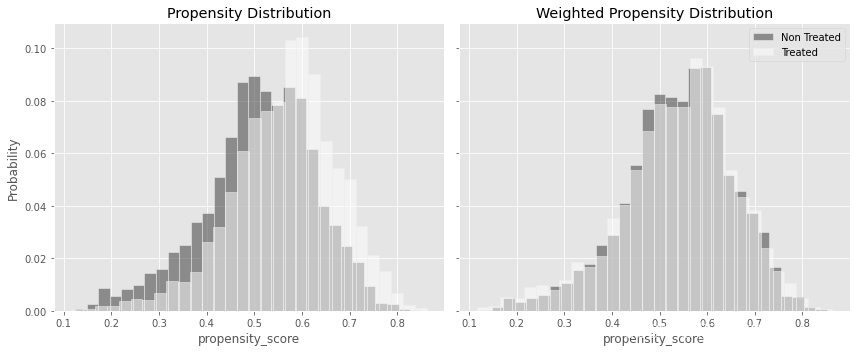
与右边的图对比一下,在 e ^ ( x ) \hat e(x) e^(x) 较低的区域,干预组权重被加强,对照组权重被减弱。同样,当 e ^ ( x ) \hat e(x) e^(x) 处于高位时,干预单元权重被减弱,对照单位权重被加强。这些变化使两个分布重叠。这一事实意味着,在加权之后的数据中,干预组和对照组获得干预的机会是相同的。换句话说,干预的分配看起来是随机的了(当然,假设没有不可观察的混杂因子)。
这也说明了IPW正在做什么。通过计算被干预者的结果 Y ∣ T = 1 Y|T=1 Y∣T=1,对 e ^ ( x ) \hat e(x) e^(x) 低的单元增加权重,对 e ^ ( x ) \hat e(x) e^(x) 高的单元降低权重,你就可以弄清楚 Y 1 ∣ T = 0 Y_1|T=0 Y1∣T=0 是什么样子。类似的,你也可以使用 1 / ( 1 − P ( T = 1 ) ) 1/(1-P(T=1)) 1/(1−P(T=1)) 调整对照样本的权重来得到 Y 0 ∣ T = 1 Y_0|T=1 Y0∣T=1。
5.3.8 选择偏差(Selection Bias)
这里使用的例子是为了说明如何使用倾向得分加权来调整共同原因,使干预组类似于对照组,反之亦然。也就是说,你看到了如何使用倾向得分加权来解释和控制混淆偏差。然而,IPW也可以用来调整选择问题。事实上,正如霍维茨和汤普森在1952年提出的那样,IPW估算值最初被用于处理这种情况。由于这个原因,你可能会将IPW估算器称为Horvitz-Thompson估算器。
举个例子,假设你想知道你的客户对你的APP的满意度。所以你发送了一份调查,让他们在1到5的范围内评价你的产品。当然,一些客户没有回应。但问题是,这可能会让你的分析产生偏差。如果没有被调查者大多是不满意的顾客,那么你从调查中得到的结果将是一个人为夸大的比率。
为了调整这一点,给定客户的协变量(如年龄,收入,APP使用情况等),你可以估算用户响应 R R R 的概率 P ( R = 1 ∣ X ) P(R=1|X) P(R=1∣X)。然后,你可以 重设那些回应的权重为 1 / P ^ ( R = 1 ) 1/\hat P(R=1) 1/P^(R=1)。这将增加那些看起来像非受访者(低 P ^ ( R = 1 ) \hat P(R=1) P^(R=1))的受访者的权重。这样,一个回答了问卷的人不仅会说明他自己的情况,还会说明其他像他一样的人的情况,从而创造出一个伪群体,这个伪群体的行为应该像最初的那个人一样,但就好像伪群体的每个人都对调查做出了回应。
有时(希望不是很多),您将不得不同时面对混淆和选择偏差。在这种情况下,你可以使用选择和混淆的权重的乘积。由于这个乘积可以非常小,我建议用边际概率 P ( T = t ) P(T=t) P(T=t) 稳定混杂偏差权重:
W = P ^ ( T = t ) P ^ ( R = 1 ∣ X ) P ^ ( T = t ∣ X ) W=\frac{\hat P(T=t)}{\hat P(R=1|X) \hat P(T=t|X)} W=P^(R=1∣X)P^(T=t∣X)P^(T=t)
5.3.9 偏差-方差权衡
作为一个天真的数据科学家,当我了解到倾向得分时,我想“哦,天哪!这是件大事!我可以将因果推理问题转化为预测问题。如果我能预测,我就成功了!”不幸的是,事情并没有那么简单。在我看来,这是一个很容易犯的错误。乍一看,你对干预分配机制的估算越好,你的因果估算就越好。但事实并非如此。
还记得在第4章中学习过噪声诱导控制吗?同样的逻辑也适用于这里。如果协变量 X k X_k Xk 是 T T T 一个很好的预测器,这个变量会给你一个 e ( x ) e(x) e(x) 的非常准确的模型。但如果相同的变量没有影响 Y Y Y,它就不是一个混杂因子,它只会增加你的IPW估算的方差。为了看到这一点,想想如果你有一个很好的 T T T 模型,该模型将对所有干预单元输出一个非常高的 e ( x ) e(x) e(x)(因为模型正确地预测了它们被干预),而对所有对照单元输出一个非常低的值(因为模型正确地预测了它们没有被干预)。这将使你没有低 e ( x ) e(x) e(x) 的干预单位来估算 Y 1 ∣ T = 0 Y_1|T=0 Y1∣T=0,也没有高 e ( x ) e(x) e(x) 的对照单位来估算 Y 0 ∣ T = 1 Y_0|T=1 Y0∣T=1。
相反,想想如果干预是随机的, e ( x ) e(x) e(x) 的预测能力应该是零!在管理者培训的例子中,在随机化的情况下,高 e ( x ) e(x) e(x) 的管理者并不比低 e ( x ) e(x) e(x) 的管理者更有可能参与培训。然而,即使没有预测能力,这也是你在估算干预效果方面能得到的最好情况。
正如你所看到的,当涉及到IPW时,也存在偏差-方差权衡。一般而言,倾向得分模型越精确,偏差越低。然而,一个非常精确的 e ( x ) e(x) e(x) 模型将产生一个非常不精确的效果估算。这意味着你必须使模型足够精确,以控制偏差,但不能太过精确,否则将遇到方差问题。
裁剪
降低IPW估算值方差的一种方法是将倾向得分调整为始终高于某个数字(比如1%),以避免权重过大(比如超过100)。同样,你可以直接裁剪权重,使其永远不会太大。权值被裁剪后的IPW不再是无偏的,但如果方差降低显著,则可能具有更低的均方误差。
5.3.10 正值性
偏差-方差权衡也可以根据两个因果推断假设来看待:条件独立性(无混淆性)和正值性。你的 e ( x ) e(x) e(x) 模型越精确,比如通过添加更多的变量,你就越倾向于让CIA保持不变。然而,由于你已经看到的原因,你也使正值性的可能性变得不那么可信:你将把干预集中在 e ( x ) e(x) e(x) 较低的区域,远离对照组,反之亦然。
IPW重建是可能的,只要你对样本重新加权。如果在低倾向得分(不干预的可能性很高)的区域没有被干预的样本,那么在该区域就没有样本重设权重来重建 Y 1 Y_1 Y1。这就是IPW下的违背正值性的情况。此外,即使不完全违反正值性,有些单元的倾向得分很小或很大,IPW也会遭受高方差的影响。
为了更直观地看到这一点,请考虑以下模拟数据。这里,真正的ATE是1。然而, x x x 混淆了 T T T 和 Y Y Y 之间的关系。 X X X 越高, Y Y Y 越小,但被干预的机会就越高。因此,在干预组和对照组之间的平均结果的简单比较得到的偏差将偏小的,甚至可能是负值:
np.random.seed(1)
n = 1000
x = np.random.normal(0, 1, n)
t = np.random.normal(x, 0.5, n) > 0
y0 = -x
y1 = y0 + t # ate of 1
y = np.random.normal((1-t)*y0 + t*y1, 0.2)
df_no_pos = pd.DataFrame(dict(x=x,t=t.astype(int),y=y))
df_no_pos.head()
| x | t | y | |
|---|---|---|---|
| 0 | 1.624345 | 1 | -0.526442 |
| 1 | -0.611756 | 0 | 0.659516 |
| 2 | -0.528172 | 0 | 0.438549 |
| 3 | -1.072969 | 0 | 0.950810 |
| 4 | 0.865408 | 1 | -0.271397 |
如果你在这些数据中估算倾向得分,一些(高 x x x)单元的倾向得分非常接近1,这意味着它们几乎不可能成为对照。类似的,一些(低 x x x)单元获得干预的机会几乎为零。你可以在下面的图中看到这一点。请注意,干预和未干预的倾向得分分布之间缺乏重叠。这是非常麻烦的,因为这意味着在 e ( x ) e(x) e(x)接近零的区域的大量对照单元分布被压缩,但在该区域你没有足够的干预单元来重建。因此,你最终会缺乏对大部分数据的 Y 1 ∣ T = 0 Y_1|T=0 Y1∣T=0 的良好估算:
ps_model_sim = smf.logit("""t ~ x""", data=df_no_pos).fit(disp=0)
df_no_pos_ps = df_no_pos.assign(ps=ps_model_sim.predict(df_no_pos))
ps = ps_model_sim.predict(df_no_pos)
w = df_no_pos["t"]*df_no_pos["t"].mean()/ps + (1-df_no_pos["t"])*((1-df_no_pos["t"].mean())/(1-ps))
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(16,7))
sns.scatterplot(data=df_no_pos_ps.assign(w=w), x="x", y="y", hue="t", ax=ax1);
ax1.set_title("Original Data")
sns.histplot(df_no_pos_ps.query("t==0")["ps"], stat="probability",
label="Non Treated", color="C0", bins=30, ax=ax2)
sns.histplot(df_no_pos_ps.query("t==1")["ps"], stat="probability",
label="Treated", color="C1", alpha=0.5, bins=30, ax=ax2)
ax2.set_xlabel("e(x)")
ax2.legend()
ax2.set_title("Positivity Check")
sns.scatterplot(data=df_no_pos_ps.assign(**{"1/P(T=t)":w}), x="x", y="y", hue="t", ax=ax3, size="1/P(T=t)", sizes=(1, 100));
ax3.set_title("IPW Data")
plt.tight_layout()
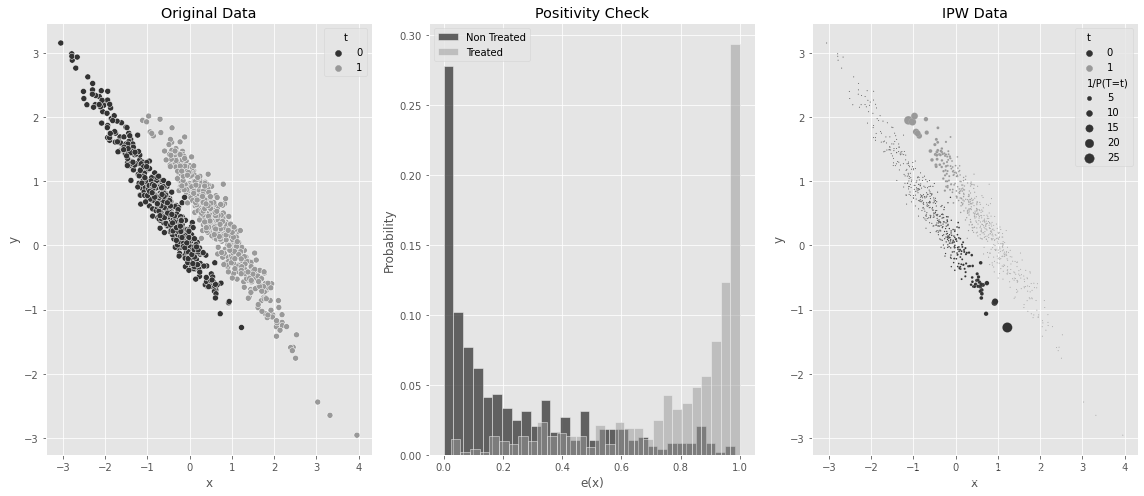
此外,正如你在上面第三张图中所看到的那样,右边的对照单元(高 e ( x ) e(x) e(x))具有巨大的权重。同样的情况也适用于左边的干预单元(低 e ( x ) e(x) e(x))。正如你现在所知道的,这些巨大的权重通常会增加IPW估算量的方差。
结合这两个问题——高方差和违反正值性,你将看到IPW估算器是如何无法恢复该数据中的ATE为1:
est_fn = partial(est_ate_with_ps, ps_formula="x", T="t", Y="y")
print("ATE:", est_fn(df_no_pos))
print(f"95% C.I.: ", bootstrap(df_no_pos, est_fn))
ATE: 0.6478011810615735
95% C.I.: [0.41710504 0.88840195]
需要注意的是,这并不是一个简单的高方差问题。当然,这个估计值的95% CI很大,但还不止于此。具体而言,置信区间的上限似乎仍然明显低于真实的等于1的ATE。
缺乏正值性不仅是IPW估算者的问题。然而,IPW在正值性问题上可以更加透明。例如,如果你绘制干预变量的倾向得分分布(上面中间的图),你可以直观地检查是否有良好的正值性水平。
事实上,让我们将IPW估算器与线性回归进行对比。你知道回归对于违反正值性的行为不会很透明。相反,它将外推到你没有任何数据的区域。在一些非常幸运的情况下,这甚至可能奏效。例如,在这个非常简单的模拟数据中,回归可以恢复ATE为1,但这只是因为它正确地推断了没有实际数据的干预和对照区域的 Y 0 Y_0 Y0 和 Y 1 Y_1 Y1:
smf.ols("t ~ x + t", data=df_no_pos).fit().params["t"]
1.0
从某种意义上说,回归可以在 E ( Y ∣ T , X ) E(Y|T,X) E(Y∣T,X) 上用参数假设代替正值性假设,参数假设本质上是关于潜在结果的平滑性假设。如果线性模型对条件期望有很好的拟合,即使在正值性不成立的区域,它也能设法恢复ATE。相反,IPW对潜在结果的情况不作任何假设。因此,当需要外推时,它就失败了。
5.4 基于设计的识别与基于模型的识别
你刚刚学习了如何使用倾向得分加权来估算干预效果。除了回归,已经给出了两种最重要的非实验数据去偏的方法。但是应该在什么时候使用哪一种呢?回归还是IPW?
这个选择隐含了关于基于模型和基于设计的识别的讨论。基于模型的识别涉及以干预和额外协变量为条件的潜在结果模型的形式作出假设。从这个角度来看,目标是估算所需的缺失的潜在结果。相比之下,基于设计的识别完全是关于对干预分配机制的假设。在第4章中,你看到了回归如何适配这两种策略:从正交化的角度来看,它是基于设计的;从潜在结果模型的估算器的角度来看,它是基于模型的。在本章中,你学习了纯粹基于设计的IPW,在后面的章节中,你将学习纯粹基于模型的合成控制(Synthetic Control)。
因此,为了在基于设计的识别和基于模型的识别之间做出选择,你需要问问自己,哪一种类型的假设更适合你。你对如何分配干预有一个很好的了解吗?或者你是否有更好的机会正确地指定一个潜在的结果模型?
5.5 双重鲁棒性估算
好消息是,当你有疑问时,你可以两者都选!双重鲁棒性(DR)估算是一种结合基于模型和基于设计的识别的方法,希望其中至少有一种是正确的。在这里,让我们看看如何用一种方式将倾向得分和线性回归结合起来,这种方式只需要正确指定其中一个方法。让我向你展示一个流行的DR估算器,并告诉你为什么它是了不起的。
很一般地,反事实 Y t Y_t Yt 的双重鲁棒性估算量可以写为:
μ ^ t D R ( m ^ , e ^ ) = 1 N ∑ m ^ ( X ) + 1 N ∑ [ T e ^ ( x ) ( Y − m ^ ( X ) ) ] \widehat \mu_t^{DR} (\widehat m, \hat e) =\frac{1}{N} \sum \widehat m(X) +\frac{1}{N} \sum \left[ \frac{T}{\hat e(x)} (Y-\widehat m(X)) \right] μ tDR(m ,e^)=N1∑m (X)+N1∑[e^(x)T(Y−m (X))]
其中 m ^ ( X ) \widehat m(X) m (X) 是 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 的模型(例如线性模型), e ^ ( X ) \hat e(X) e^(X) 是计算 P ( T ∣ X ) P(T|X) P(T∣X) 的倾向得分模型。现在,这之所以令人惊讶,以及为什么它被称为双重鲁棒性的原因是,它只需要其中一个模型, m ^ ( X ) \widehat m(X) m (X) 或者 e ^ ( X ) \hat e(X) e^(X),被正确地指定。
例如,假设倾向得分模型是错误的,但结果模型 m ^ ( X ) \widehat m(X) m (X) 是正确的。在这种情况下,第二项会收敛于0,因为 E ( Y = m ^ ( X ) ) = 0 E (Y=\widehat m(X))=0 E(Y=m (X))=0。你会剩下第一项,也就是正确的结果模型。
接下来,让我们考虑结果模型不正确,但倾向得分模型准确的场景。为了探索这种可能性,你可以对前面的公式进行一些代数操作,将其重写为以下形式:
μ ^ t D R ( m ^ , e ^ ) = 1 N ∑ T Y e ^ ( X ) + 1 N ∑ [ T − e ^ ( X ) e ^ ( X ) m ^ ( X ) ] \widehat \mu_t^{DR} (\widehat m, \hat e) =\frac{1}{N} \sum \frac{TY}{\hat e(X)} +\frac{1}{N} \sum \left[ \frac{T-\hat e(X)}{\hat e(X)} \widehat m(X) \right] μ tDR(m ,e^)=N1∑e^(X)TY+N1∑[e^(X)T−e^(X)m (X)]
我希望这能让你看得更清楚。如果倾向模型是正确的, T − e ^ ( X ) T-\hat e(X) T−e^(X) 将收敛到零。这样就只剩下第一项了,也就是IPW估算量。由于倾向模型是正确的,那么这个估算量也是正确的。这就是这个双重鲁棒性估算器的美妙之处:它收敛于任何一个正确的模型。
前面的估算器会估算平均反事实结果 Y t Y_t Yt。如果你想估算平均干预效果,你所要做的就是把这两个估算器放在一起,一个为 E ( Y 0 ) E(Y_0) E(Y0),一个为 E ( Y 1 ) E(Y_1) E(Y1),然后取其差值:
A T E = μ ^ 1 D R ( m ^ , e ^ ) − μ ^ 0 D R ( m ^ , e ^ ) ATE=\widehat \mu_1^{DR} (\widehat m, \hat e)-\widehat \mu_0^{DR} (\widehat m, \hat e) ATE=μ 1DR(m ,e^)−μ 0DR(m ,e^)
在理解了DR背后的理论之后,是时候进行编码了。模型 e ^ \hat e e^ 和 m ^ \widehat m m 不需要分别是逻辑回归和线性回归,但我认为它们是很好的入门候选人。再一次,我将使用稻草人程序库(patsy)的dmatrix中的R风格公式来设计协变量矩阵 X X X。接下来,我用逻辑回归来拟合倾向模型,得到 e ^ ( X ) \hat e(X) e^(X)。然后是输出模型部分。我为每个干预变量(干预和未干预)拟合一个线性回归。每个模型都对其干预变量的数据子集进行拟合,但是对整个数据集进行预测。例如,对照模型只拟合 T = 0 T=0 T=0 的数据,但它预测所有数据,得到估算量 Y 0 Y_0 Y0。
最后,我将两个模型结合起来,形成 E ( Y 0 ) E(Y_0) E(Y0) 和 E ( Y 1 ) E(Y_1) E(Y1) 的DR估算器。下面是将刚才看到的公式转换成代码:
from sklearn.linear_model import LinearRegression
def doubly_robust(df, formula, T, Y):
X = dmatrix(formula, df)
ps_model = LogisticRegression(penalty="none",
max_iter=1000).fit(X, df[T])
ps = ps_model.predict_proba(X)[:, 1]
m0 = LinearRegression().fit(X[df[T]==0, :], df.query(f"{T}==0")[Y])
m1 = LinearRegression().fit(X[df[T]==1, :], df.query(f"{T}==1")[Y])
m0_hat = m0.predict(X)
m1_hat = m1.predict(X)
return (
np.mean(df[T]*(df[Y] - m1_hat)/ps + m1_hat) -
np.mean((1-df[T])*(df[Y] - m0_hat)/(1-ps) + m0_hat)
)
让我们看看该模型在管理培训数据中的表现。你也可以将模型传递给你的自主法(bootstrap)函数来构建一个DR ATE估算的置信区间:
formula = """tenure + last_engagement_score + department_score
+ C(n_of_reports) + C(gender) + C(role)"""
T = "intervention"
Y = "engagement_score"
print("DR ATE:", doubly_robust(df, formula, T, Y))
est_fn = partial(doubly_robust, formula=formula, T=T, Y=Y)
print("95% CI", bootstrap(df, est_fn))
DR ATE: 0.27115831057931455
95% CI [0.23012681 0.30524944]
正如你所看到的,计算值与你前面看到的IPW和回归估算量都非常一致。这是一个好消息,因为这意味着DR估算器没有做任何疯狂的事情。但老实说,这个例子有点无聊,并没有确切地展示出DR的力量。为了更好地理解为什么DR如此有趣,让我们制作两个新的例子。它们将相当简单,但非常具有说明性。
5.5.1 当干预容易建模
在第一个例子中,干预分配相当容易建模,但结果模型有点复杂。具体而言,干预遵循伯努利分布,概率由以下倾向得分给出:
e ( x ) = 1 1 + e − ( 1 + 1.5 x ) e(x)=\frac{1}{1+e^{-(1+1.5x)}} e(x)=1+e−(1+1.5x)1
这正是逻辑回归假设的形式,所以估算它应该很容易。此外,由于 P ( T ∣ X ) P(T|X) P(T∣X) 易于建模,使用IPW评分找到真实的ATE(这里接近2)应该没有问题。相反,由于结果 Y Y Y 有点棘手,回归模型可能会遇到一些麻烦:
np.random.seed(123)
n = 10000
x = np.random.beta(1,1, n).round(2)*2
e = 1/(1+np.exp(-(1+1.5*x)))
t = np.random.binomial(1, e)
y1 = 1
y0 = 1 - 1*x**3
y = t*(y1) + (1-t)*y0 + np.random.normal(0, 1, n)
df_easy_t = pd.DataFrame(dict(y=y, x=x, t=t))
print("True ATE:", np.mean(y1-y0))
True ATE: 2.0056243152
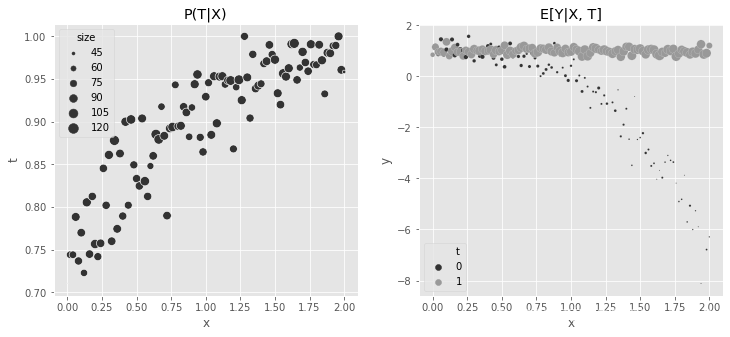
下面两个图显示了这些数据的样子。有趣的是,在第二张图中很容易看到数据中的效果异质性。注意,当 x x x 值较低时,效果是0,随着 x x x 值的增加,效果呈非线性增长。这种异质性通常很难让回归正确:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
sns.scatterplot(data=(df_easy_t
.assign(size=1)
.groupby(["x"])
.agg({"size":"sum", "t":"mean"})
.reset_index()),
x="x", y="t", sizes=(1, 100), size="size", ax=ax1);
ax1.set_title("P(T|X)")
sns.scatterplot(data=(df_easy_t
.assign(size=1)
.groupby(["x", "t"])
.agg({"size":"sum", "y":"mean"})
.reset_index()),
x="x", y="y", hue="t", sizes=(1, 100), size="size", ax=ax2)
ax2.set_title("E[Y|X, T]")
h,l = ax2.get_legend_handles_labels()
plt.legend(h[0:3],l[0:3])
<matplotlib.legend.Legend at 0x7ff244570c90>
现在,让我们看看回归是如何在这些数据中发挥作用的。这里,我再次分别拟合 m ^ 1 \widehat m_1 m 1 和 m ^ 0 \widehat m_0 m 0,估算ATE作为整个数据集中不同预测的平均值, N − 1 ∑ ( m ^ 1 ( x ) − m ^ 0 ( X ) ) N^{-1} \sum (\widehat m_1 (x) -\widehat m_0 (X)) N−1∑(m 1(x)−m 0(X)):
m0 = smf.ols("y~x", data=df_easy_t.query("t==0")).fit()
m1 = smf.ols("y~x", data=df_easy_t.query("t==1")).fit()
regr_ate = (m1.predict(df_easy_t) - m0.predict(df_easy_t)).mean()
print("Regression ATE:", regr_ate)
Regression ATE: 1.786678396833022
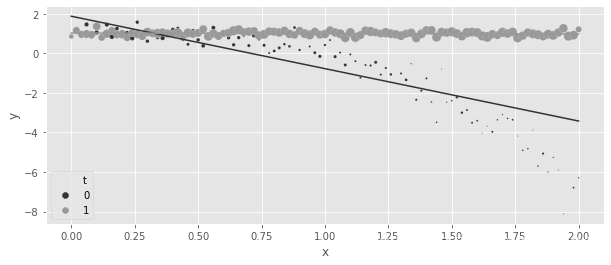
正如预期的那样,回归模型未能恢复到2的真实ATE。如果你根据原始数据绘制预测值,就可以看到原因。回归未能捕捉到对照组的曲线:
regr = smf.ols("y~x*t", data=df_easy_t).fit()
plt.figure(figsize=(10,4))
sns.scatterplot(data=(df_easy_t
.assign(count=1)
.groupby(["x", "t"])
.agg({"count":"sum", "y":"mean"})
.reset_index()),
x="x", y="y", hue="t", sizes=(1, 100), size="count");
g = sns.lineplot(data=(df_easy_t
.assign(pred=regr.fittedvalues)
.groupby(["x", "t"])
.mean()
.reset_index()),
x="x", y="pred", hue="t", sizes=(1, 100))
h,l = g.get_legend_handles_labels()
plt.legend(h[0:3],l[0:3])
<matplotlib.legend.Legend at 0x7ff200433fd0>
需要明确的是,这并不意味着不能用回归正确估计ATE。如果你知道数据的真实曲率,你几乎可以正确地建模:
m = smf.ols("y~t*(x + np.power(x, 3))", data=df_easy_t).fit()
regr_ate = (m.predict(df_easy_t.assign(t=1))
- m.predict(df_easy_t.assign(t=0))).mean()
print("Regression ATE:", regr_ate)
Regression ATE: 1.9970999747190072
但是,当然,在现实中,你并不知道这些数据是如何产生的。所以,更有可能的是,回归会让你在这里失败。相比之下,让我们看看IPW的表现。同样,由于建模干预分配相当容易,你应该期望IPW在这些数据上表现得相当好:
est_fn = partial(est_ate_with_ps, ps_formula="x", T="t", Y="y")
print("Propensity Score ATE:", est_fn(df_easy_t))
print("95% CI", bootstrap(df_easy_t, est_fn))
Propensity Score ATE: 2.002350388474011
95% CI [1.80802227 2.22565667]
请注意,IPW几乎确定了正确的ATE。
最后,你期待已久的时刻到来了,让我们看看DR估计的实际效果。请记住,DR要求 P ( T ∣ X ) P(T|X) P(T∣X) 或 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 中的至少一个模型是正确的。在此数据中, P ( T ∣ X ) P(T|X) P(T∣X) 模型是正确的,但 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 模型是错误的:
est_fn = partial(doubly_robust, formula="x", T="t", Y="y")
print("DR ATE:", est_fn(df_easy_t))
print("95% CI", bootstrap(df_easy_t, est_fn))
DR ATE: 2.001617934263116
95% CI [1.87088771 2.145382 ]
正如预期的那样,DR在这里表现得相当好,也恢复了真正的ATE。但不止如此,请注意,95% CI是小于纯IPW估算的,这意味着这里的DR估算更精确。这个简单的例子展示了DR如何在 P ( T ∣ X ) P(T|X) P(T∣X) 容易建模的情况下表现良好,即使 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 出错了。那么,反过来会怎么样呢?
5.5.2 当结果容易建模
在下一个简单但具有说明性的示例中,复杂性体现再 P ( T ∣ X ) P(T|X) P(T∣X),而不是 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 。注意 P ( T ∣ X ) P(T|X) P(T∣X) 中的非线性,而结果函数只是线性的。这里,真正的ATE是-1:
np.random.seed(123)
n = 10000
x = np.random.beta(1,1, n).round(2)*2
e = 1/(1+np.exp(-(2*x - x**3)))
t = np.random.binomial(1, e)
y1 = x
y0 = y1 + 1 # ate of -1
y = t*(y1) + (1-t)*y0 + np.random.normal(0, 1, n)
df_easy_y = pd.DataFrame(dict(y=y, x=x, t=t))
print("True ATE:", np.mean(y1-y0))
True ATE: -1.0
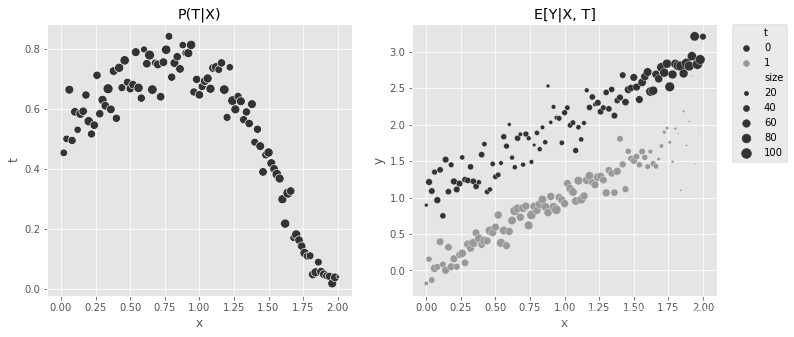
同样的图表可以用来显示 P ( T ∣ X ) P(T|X) P(T∣X) 的复杂函数和 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 的简单线条:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,5))
sns.scatterplot(data=(df_easy_y
.assign(size=1)
.groupby(["x"])
.agg({"size":"sum", "t":"mean"})
.reset_index()),
x="x", y="t", sizes=(1, 100), size="size", ax=ax1, legend=None);
sns.scatterplot(data=(df_easy_y
.assign(size=1)
.groupby(["x", "t"])
.agg({"size":"sum", "y":"mean"})
.reset_index()),
x="x", y="y", hue="t", sizes=(1, 100), size="size", ax=ax2);
ax1.set_title("P(T|X)")
ax2.set_title("E[Y|X, T]")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
<matplotlib.legend.Legend at 0x7ff230d2b490>
在这些数据中,由于倾向得分模型相对复杂,IPW无法恢复真实的ATE:
est_fn = partial(est_ate_with_ps, ps_formula="x", T="t", Y="y")
print("Propensity Score ATE:", est_fn(df_easy_y))
print("95% CI", bootstrap(df_easy_y, est_fn))
Propensity Score ATE: -1.1042900278680896
95% CI [-1.14326893 -1.06576358]
但回归却能精确地得出结论:
m0 = smf.ols("y~x", data=df_easy_y.query("t==0")).fit()
m1 = smf.ols("y~x", data=df_easy_y.query("t==1")).fit()
regr_ate = (m1.predict(df_easy_y) - m0.predict(df_easy_y)).mean()
print("Regression ATE:", regr_ate)
Regression ATE: -1.0008783612504342
同样,由于DR只需要正确计算其中一个模型,也可以在这里恢复真正的ATE:
est_fn = partial(doubly_robust, formula="x", T="t", Y="y")
print("DR ATE:", est_fn(df_easy_y))
print("95% CI", bootstrap(df_easy_y, est_fn))
DR ATE: -1.0028459347805823
95% CI [-1.04156952 -0.96353366]
希望这两个例子能更清楚地说明为什么双重鲁棒性估算会很有趣。最重要的是,它给了你两次达到正确的机会。在某些情况下, P ( T ∣ X ) P(T|X) P(T∣X) 很难建模,但 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 很容易建模。在另外一些场景下,情况可能正好相反。无论如何,只要您能够正确地建模其中一个,您就可以组合 P ( T ∣ X ) P(T|X) P(T∣X) 模型和 E ( Y t ∣ X ) E(Y_t|X) E(Yt∣X) 模型。这就是双重鲁棒性估算器的真正力量。
另请参阅
这里介绍的DR估算器只是其中之一。仅举一些例子,你可以使用本章所述的DR估计器,但将回归模型的权重设置为 e ^ ( x ) \hat e(x) e^(x)。或者,你可以将 e ^ ( x ) \hat e(x) e^(x) 添加到回归模型中。有趣的是,线性回归单独是一个将干预建模为 e ( x ) = β X e(x)=\beta X e(x)=βX 的DR估算器。它不是一个很好的DR估算器,因为 β X \beta X βX 不像概率模型那样有0到1的界限,但它仍然是一个DR估算器。要了解更多关于其他DR估计器的信息,请查看Robins等人2008年发表的《评论:当“逆概率”权重高度可变时双重鲁棒性估算器的性能》(Comment: Performance of Double-Robust Estimators When ‘Inverse Probability’)一文中的精彩讨论。
5.6 连续干预的广义倾向得分
到目前为止,本章只展示了如何使用倾向分数进行离散处理。连续干预要复杂得多,以至于我想说因果推断作为一门科学,还没有很好的方法来处理。
在第4章中,你通过假设干预反馈公式成功地规避了连续干预,类似于 y = a + b t y=a+bt y=a+bt(线性形式)或 y = a + b t y=a+b \sqrt t y=a+bt(平方根形式),然后你可以用OLS来估计。但当涉及到倾向加权时,就没有参数响应函数了。通过重新加权和取平均值,非参数地估算潜在结果。当 T T T 是连续的,就存在无限多的潜在结果 Y t Y_t Yt。此外,由于连续变量的概率总是零,在这种情况下估算 P ( T = t ∣ X ) P(T=t|X) P(T=t∣X) 是不可行的。
解决这些问题的最简单方法是将连续干预离散化为一个更粗的版本,然后可以作为离散处理。但还有另一种方法,那就是使用广义倾向得分。如果你对传统的倾向得分做一些改变,你将能够适应任何类型的干预。要了解这是如何工作的,请考虑下面的示例。
银行想知道贷款利率如何影响客户选择偿还贷款的期限(以月为单位)。直观地说,利息对期限的影响应该是负的,因为人们喜欢尽快偿还高利率贷款,以避免支付过多的利息。
为了回答这个问题,银行可以将利率随机化,但这将在金钱和时间上付出高昂代价。相反,银行希望使用已经拥有的数据。银行知道利率是由两个机器学习模型分配的:ml_1和ml_2。此外,由于该银行的数据科学家非常聪明,他们在利率决策过程中添加了随机高斯噪声。这确保了策略是不确定性的,并且不违反正值性假设。观测(非随机)利率数据,以及关于混杂因子 ml_1 和 ml_2 的信息和结果期限存储在df_cont_t数据框中:
df_cont_t = pd.read_csv("./data/interest_rate.csv")
df_cont_t.head()
| ml_1 | ml_2 | interest | duration | |
|---|---|---|---|---|
| 0 | 0.392938 | 0.326285 | 7.1 | 12.0 |
| 1 | -0.427721 | 0.679573 | 5.6 | 17.0 |
| 2 | -0.546297 | 0.647309 | 11.1 | 12.0 |
| 3 | 0.102630 | -0.264776 | 7.2 | 18.0 |
| 4 | 0.438938 | -0.648818 | 9.5 | 19.0 |
你的任务是通过调整 ml_1 和 ml_2,消除利率和期限之间关系的偏差。请注意,如果你简单地估算干预效果,不做任何调整,你会发现一个正值的干预效果。正如前面所讨论的,这在商业上没有意义,所以这个结果可能是有偏差的:
m_naive = smf.ols("duration ~ interest", data=df_cont_t).fit()
m_naive.summary().tables[1]
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 14.5033 | 0.226 | 64.283 | 0.000 | 14.061 | 14.946 |
| interest | 0.3393 | 0.029 | 11.697 | 0.000 | 0.282 | 0.396 |
为了调整 ml_1 和 ml_2,你可以将它们包含在你的模型中,但让我们看看如何通过调整权重来完成相同的事情。需要解决的第一个挑战是,连续变量在任何地方的概率都是零,即 P ( T = t ) = 0 P(T=t)=0 P(T=t)=0。这是因为概率是由密度下的面积来表示的,而单个点的面积总是零。一个可能的解决方案是使用条件密度函数 f ( T ∣ X ) f(T|X) f(T∣X) 而不是条件概率 P ( T = t ∣ X ) P(T=t|X) P(T=t∣X)。然而,这种方法带来了另一个问题,即需要指定干预的分布。
这里,为了简单起见,我们假设干预是一个正态分布 T → N ( μ i , σ 2 ) T \to N(\mu_i,\sigma^2) T→N(μi,σ2)。这是一个相当合理的简化,特别是因为正态分布可以用来近似其他分布。此外,让我们假设方差 σ 2 \sigma^2 σ2 为常数,而不是随每个个体变化。
回想一下,正态分布的密度由以下函数给出:
f ( t i ) = e x p ( − 1 2 ( t i − μ i s i g m a ) 2 ) σ 2 π f(t_i) = \frac {exp \left(-\frac {1}{2} \left( \frac {t_i-\mu_i} {sigma} \right)^2 \right)} {\sigma \sqrt {2 \pi}} f(ti)=σ2πexp(−21(sigmati−μi)2)
现在需要估算条件高斯分布的参数,也就是均值和标准差。最简单的方法是使用OLS拟合干预变量:
model_t = smf.ols("interest~ml_1+ml_2", data=df_cont_t).fit()
然后,拟合值为 μ i \mu_i μi,残差的标准差为 σ \sigma σ。有了这个,你就有了条件密度的估算。接下来,你需要在给定干预下评估条件密度,这就是为什么我在以下代码中将 T T T 传递给密度函数中的x参数:
def conditional_density(x, mean, std):
denom = std*np.sqrt(2*np.pi)
num = np.exp(-((1/2)*((x-mean)/std)**2))
return (num/denom).ravel()
gps = conditional_density(df_cont_t["interest"],
model_t.fittedvalues,
np.std(model_t.resid))
gps
array([0.1989118 , 0.14524168, 0.03338421, ..., 0.07339096, 0.19365006,
0.15732008])
或者,你可以(也许应该)从scipy中导入正态分布并使用它:
from scipy.stats import norm
gps = norm(loc=model_t.fittedvalues,
scale=np.std(model_t.resid)).pdf(df_cont_t["interest"])
gps
array([0.1989118 , 0.14524168, 0.03338421, ..., 0.07339096, 0.19365006,
0.15732008])
超出正常范围
如果干预遵循的不是正态分布,而是别的分布,你可以使用广义线性模型(glm)来拟合它。例如,如果 T T T 是根据泊松分布分配的,你可以用以下代码来构建GPS权重:
import statsmodels.api as sm from scipy.stats import poisson mt = smf.glm("t~x1+x2", data=df, family=sm.families.Poisson()).fit() gps = poisson(mu=m_pois.fittedvalues).pmf(df["t"]) w = 1/gps
在回归模型中使用GPS的倒数作为权重可以调整偏差。现在你会发现利息对期限的负面影响,这更有商业意义:
final_model = smf.wls("duration~interest",
data=df_cont_t, weights=1/gps).fit()
final_model.params["interest"]
-0.6673977919925854
还可以进行一个改进,这将提供对GPS更直观的理解。使用这个分数来构建权重将使不太可能干预的点得到更大的重视。具体来说,你将在已拟合的干预模型中为具有高残差的单元分配高权重。此外,由于正态密度的指数性质,权重将随着残差的大小呈指数增长。
为了说明这一点,假设您只使用 ml_1 来拟合利率,而不是同时使用 ml_1 和 ml_2。这种简化使所有内容都可以在一个图中呈现。得到的权重将在下图中显示。第一个图显示了原始数据,由混杂因子 ml_1 用颜色标记。在 ml_1 上得分较低的客户通常会选择更长的期限来偿还贷款。此外,ml_1 得分较低的客户被分配更高的利率。因此,利率与期限的关系的偏差被高估。
第二幅图显示了干预模型的拟合值和GPS从该模型获得的权重。距离拟合线越远,它们就越大。这是有道理的,因为GPS更重视不可能的干预。但看看权重能有多大,有些甚至超过1000!
np.random.seed(1)
sample = df_cont_t.sample(2000)
model_ex = smf.ols("interest~ml_1", data=sample).fit()
gps_ex = norm(loc=model_ex.fittedvalues, scale=np.std(model_ex.resid)).pdf(sample["interest"])
w_ex = 1/gps_ex
m = smf.ols("duration~interest", data=sample).fit()
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(16, 6))
sns.scatterplot(data=sample, x="interest", y="duration", alpha=1, ax=ax1, hue="ml_1", palette = 'gray')
ax1.plot(sample["interest"], m.fittedvalues)
ax1.set_ylabel("Duration")
ax1.set_xlabel("Interest")
ax1.set_title("Original Data");
sns.scatterplot(data=sample.assign(w=w_ex), x="ml_1", y="interest",size="w",
sizes=(1,200), alpha=0.5, ax=ax2)
ax2.plot(sample["ml_1"], model_ex.fittedvalues)
ax2.set_ylabel("Interest")
ax2.set_xlabel("ML-1")
ax2.set_title("Weights")
m = smf.wls("duration~interest", data=sample, weights=w_ex).fit()
sns.scatterplot(data=sample.assign(w=w_ex), x="interest", y="duration",size="w",
sizes=(1,200), alpha=1, ax=ax3, hue="ml_1", legend=None, palette = 'gray')
ax3.plot(sample["interest"], m.fittedvalues)
ax3.set_ylabel("Duration")
ax3.set_xlabel("Interest")
ax3.set_title("Weighted Data")
plt.tight_layout()

最后一张图显示了相同的权重,但关注的是利息和期限之间的关系。由于 ml_1 低值时的低利率和 ml_1 高值时的高利率都不太可能,GPS权重倒数使得这些点被高度重视。这成功地扭转了利息和期限之间的正向(和偏见)关系。但这个估算器会有很大的方差,因为它实际上只使用了一些数据点——那些权重很高的数据点。此外,因为这个数据是模拟的,我知道真实的ATE是-0.8,但之前的估计只有-0.66。
为了改进它,您可以通过边际密度 f ( t ) f(t) f(t) 来稳定权重。不像离散干预,这里使用GPS使得权重稳定得很好,我想说这是必须的。要估算 f ( t ) f(t) f(t),你可以简单地使用平均干预值。然后,评估在给定干预下的结果密度。
请注意,这乘积(几乎)与原始样本量相等。从重要性抽样的角度来考虑这个问题,这些权重将概率密度从 f ( t ∣ x ) f(t|x) f(t∣x) 转变为 f ( t ) f(t) f(t),一个干预不依赖于 x x x 的密度:
stabilizer = norm(
loc=df_cont_t["interest"].mean(),
scale=np.std(df_cont_t["interest"] - df_cont_t["interest"].mean())
).pdf(df_cont_t["interest"])
gipw = stabilizer/gps
print("Original Sample Size:", len(df_cont_t))
print("Effective Stable Weights Sample Size:", sum(gipw))
Original Sample Size: 10000
Effective Stable Weights Sample Size: 9988.19595174861
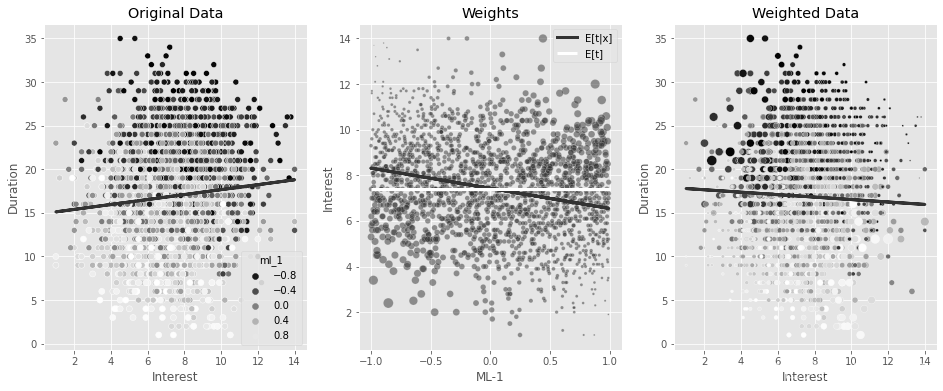
同样,为了理解发生了什么,假设您只使用 ml_1 拟合 f ( t ∣ x ) f(t|x) f(t∣x)。同样,倾向权重倒数对远离干预模型拟合值的点给予高度重视,因为它们落在 f ( t ∣ x ) f(t|x) f(t∣x) 的低密度区域。但除此之外,这个稳定器也给予远离 f ( t ) f(t) f(t) 的点较低的重要性,即远离均值的点。结果是双重的。首先,稳定的权重小得多,这就降低了方差。其次,越来越明显的是,你现在更重视 ml_1 的低值点和低利率的(反之亦然)。你可以通过第一个和第三个图之间颜色模式的变化看到这一点:
np.random.seed(1)
sample = df_cont_t.sample(2000)
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(16, 6))
model_ex = smf.ols("interest~ml_1", data=sample).fit()
gps_ex = norm(loc=model_ex.fittedvalues, scale=np.std(model_ex.resid)).pdf(sample["interest"])
stabilizer_ex = norm(
loc=sample["interest"].mean(),
scale=np.std(sample["interest"] - sample["interest"].mean())
).pdf(sample["interest"])
w_ex = stabilizer_ex/gps_ex
m = smf.ols("duration~interest", data=sample).fit()
sns.scatterplot(data=sample, x="interest", y="duration", alpha=1, ax=ax1, hue="ml_1", palette = 'gray')
ax1.plot(sample["interest"], m.fittedvalues, lw=3)
ax1.set_ylabel("Duration")
ax1.set_xlabel("Interest")
ax1.set_title("Original Data");
sns.scatterplot(data=sample.assign(w=w_ex), x="ml_1", y="interest",size="w",
sizes=(1,100), alpha=0.5, ax=ax2)
ax2.plot(sample["ml_1"], model_ex.fittedvalues, label="E[t|x]", lw=3)
ax2.hlines(sample["interest"].mean(), -1, 1, label="E[t]", color="C2", lw=3)
ax2.set_ylabel("Interest")
ax2.set_xlabel("ML-1")
ax2.set_title("Weights")
h,l = ax2.get_legend_handles_labels()
ax2.legend(h[5:],l[5:],)
m = smf.wls("duration~interest", data=sample, weights=w_ex).fit()
sns.scatterplot(data=sample.assign(w=w_ex), x="interest", y="duration",size="w",
sizes=(1,100), alpha=1, ax=ax3, hue="ml_1", legend=None, palette = 'gray')
ax3.plot(sample["interest"], m.fittedvalues, lw=3)
ax3.set_ylabel("Duration")
ax3.set_xlabel("Interest")
ax3.set_title("Weighted Data")
Text(0.5, 1.0, 'Weighted Data')
此外,这些稳定的权重让你的估算更接近真实的-0.8:
final_model = smf.wls("duration ~ interest",
data=df_cont_t, weights=gipw).fit()
final_model.params["interest"]
-0.7787046278134069
正如你所看到的,即使权重稳定器在 T T T 是离散的情况下对原因没有影响,但它与连续干预非常相关。它让你更接近你试图估算的参数的真实值,也显著地减少了方差。由于有点重复,所以我省略了计算估算值的95% CI的代码,但这与你以前所做的工作基本相同:只是将整个代码封装在一个函数中并传递给自助法函数。你们可以自己看一下,有无稳定器时,95%的置信区间分别是什么:
def gps_normal_ate(df, formula, T, Y, stable=True):
mt = smf.ols(f"{T}~"+formula, data=df).fit()
gps = norm(loc=mt.fittedvalues, scale=np.std(mt.resid)).pdf(df[T])
stabilizer = norm(
loc=df[T].mean(),
scale=np.std(df[T] - df[T].mean())
).pdf(df[T])
if stable:
return smf.wls(f"{Y}~{T}", data=df, weights=stabilizer/gps).fit().params[T]
else:
return smf.wls(f"{Y}~{T}", data=df, weights=1/gps).fit().params[T]
print("95% CI, non-stable: ", bootstrap(df_cont_t, partial(gps_normal_ate, formula="ml_1 + ml_2", T="interest", Y="duration", stable=False)))
print("95% CI, stable: ", bootstrap(df_cont_t, partial(gps_normal_ate, formula="ml_1 + ml_2", T="interest", Y="duration")))
95% CI, non-stable: [-0.81074164 -0.52605933]
95% CI, stable: [-0.85834311 -0.71001914]
请注意,两者都包含了-0.8的真实值,但具有稳定器的那个要窄得多。
连续干预论文
还有其他方法可以通过预测干预的模型来估算干预效果。一个想法(由Hirano和Imbens提出)是将GPS作为协变量纳入回归函数。另一种选择(由Imai和van Dyk提出)是拟合 T T T,根据预测 T ^ \widehat T T 对数据进行细分,对每个由 T ^ \widehat T T 定义的细分结果上的干预进行回归,并使用加权平均来组合结果,其中权重是每个组的大小。
为了一个更全面的可用选项的调查,我建议查看Douglas Galagate的博士论文《因果推断与连续干预和结果》(Causal Inference with a Continuous Treatment and Outcome)。
还有一个名为causal-curve的Python包,它提供了一个类似scikit-learn的API,用GPS对连续干预进行建模,如果你不想手工编写所有这些代码的话。
5.7 要点总结
逆倾向加权与一般意义上的回归和正交化一样,是因果推理工具箱中用于偏差调整的第二种主要工具。这两种技术都需要你建立干预模型。这应该提醒我们,在任何因果推理问题中,考虑干预分配机制是多么重要。然而,每种技术都以一种非常独特的方式利用这种干预模型。正交化对干预进行了残余化,将其投射到一个新的空间,在这个空间中,它与用来对干预进行建模的协变量 X X X 线性独立(正交)。IPW保持相同的干预维度,但根据干预倾向的倒数重新加权数据:
ω = P ( T = t ) P ( T = t ∣ X ) \omega=\frac{P(T=t)}{P(T=t|X)} ω=P(T=t∣X)P(T=t)
这使得干预看起来像是从分布 P ( T ) P(T) P(T) 中得出的,而不依赖于用于创建倾向模型的协变量 X X X。
下图展示了两种方法的简单比较。在这个数据中,干预效果是正向的,但被 x x x 混淆了,这是在数据点的颜色标记中描述的。第一张图包含了原始数据沿着 t t t 上 y y y的回归线。负斜率是由于来自 x x x 的偏差。接下来的两个图显示了正交化和IPW如何使用非常不同的想法来对这些数据进行处理。两者都恢复了 t t t 对 y y y 的正向因果效应,如各自的回归线所示。
np.random.seed(1)
n=100
df1 = pd.DataFrame(dict(
x=1,
t=np.random.beta(2.5,1, n),
)).assign(y = lambda d: np.random.normal(d["x"]+d["t"], 0.1))
df2 = pd.DataFrame(dict(
x=2,
t=np.random.beta(1,1, n),
)).assign(y = lambda d: np.random.normal(d["x"]+d["t"], 0.1))
df3 = pd.DataFrame(dict(
x=3,
t=np.random.beta(1,2.5, n),
)).assign(y = lambda d: np.random.normal(d["x"]+d["t"], 0.1))
df_example = pd.concat([df1, df2, df3])
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15,6))
m = smf.ols("y~t", data=df_example).fit()
sns.scatterplot(data=df_example, x="t", y="y", hue="x", s=50, ax=ax1, palette = 'gray')
ax1.plot(df_example["t"], m.fittedvalues)
ax1.set_title("Biased Data")
## Orthogonalization
mt = smf.ols("t~x", data=df_example).fit()
my = smf.ols("y~x", data=df_example).fit()
df_ex_res = df_example.assign(
t_res = mt.resid + df_example["t"].mean(),
y_res = my.resid + df_example["y"].mean()
)
m_final = smf.ols("y_res~t_res", data=df_ex_res).fit()
sns.scatterplot(data=df_ex_res, x="t_res", y="y_res", hue="x", s=50, ax=ax2, legend=None, palette = 'gray')
ax2.plot(df_ex_res["t_res"], m_final.fittedvalues)
ax2.set_ylim(df_example["y"].min(), df_example["y"].max())
ax2.set_xlim(df_example["t"].min(), df_example["t"].max())
ax2.set_ylabel("y - E[y|x] + E[y]")
ax2.set_xlabel("t - E[t|x] + E[t]")
ax2.set_title("Orthogonalization")
## IPW
gps_example = norm(loc=mt.fittedvalues, scale=np.std(mt.resid)).pdf(df_example["t"])
stabilizer_example = norm(
loc=df_example["t"].mean(),
scale=np.std(df_example["t"] - df_example["t"].mean())
).pdf(df_example["t"])
w_example = stabilizer_example/gps_example
mw = smf.wls("y~t", data=df_example, weights=w_example).fit()
sns.scatterplot(data=df_example.assign(w=w_example), x="t", y="y", hue="x", ax=ax3, size="w",
legend=None, sizes=(11,100), palette = 'gray')
ax3.plot(df_example["t"], mw.fittedvalues)
ax3.set_title("IPW")
plt.tight_layout()
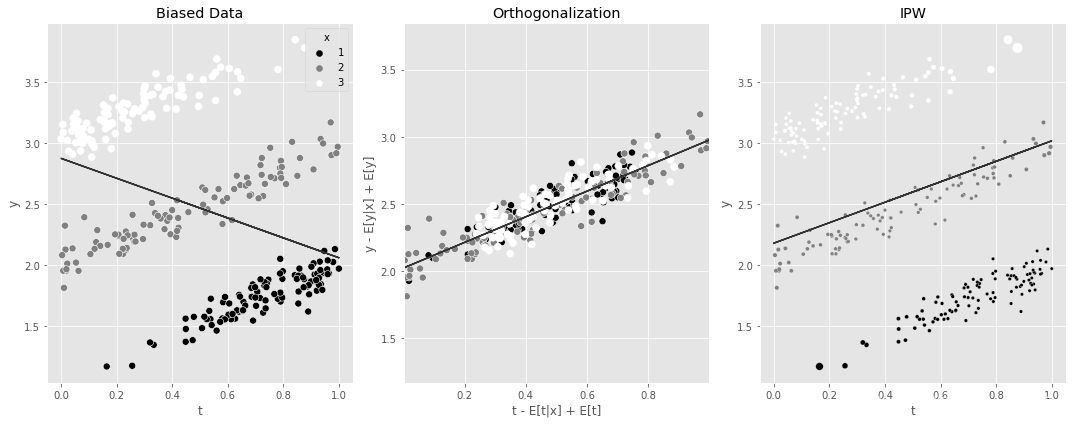
如果这两种方法都能消除数据的偏差,那么自然而然就会产生一个问题:你应该选择哪一种方法?我的看法是,这取决于个人。当干预是离散的时候,我非常喜欢IPW,特别是如果你用一种双重鲁棒性的方法将它与结果建模结合起来。然而,当干预是连续的,我倾向于在第4章看到的那种回归模型。在连续干预中,任何特定干预的数据点都非常少。因此,像IPW这样的方法,没有干预反馈函数的参数假设,变得不那么有吸引力。对我来说,在干预反馈函数中假设一些平滑性是更有成效的,允许你从一个特定干预周围的邻近点收集信息来推断它的反应。
当然,我认为广义倾向得分是非常值得理解的方法,因为它让你进一步直观地了解一般的IPW。这就是为什么我把它包含在这一章中。同时,随着干预文献的不断发展,我希望你能够跟上它,如果你愿意的话。但是日常生活中,当 T T T 是连续的,我认为你使用结果模型更好,如线性回归。
系列文章专栏:
使用Python进行因果推断(Causal Inference in Python)
第1章 因果推断导论
第2章 随机实验与统计学回顾
第3章 图形化因果模型
第4章 线性回归的不合理有效性
第5章 倾向分
第6章 效果异质性
第7章 元学习器
第8章 双重差分
持续更新中:
第9章 综合控制
第10章 Geo实验与Switchback实验
第11章 不依从性与工具
第12章 后续行动
【参考】

















 2449
2449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











