






http://www.cnblogs.com/herbert/archive/2013/01/07/2848892.html 写的特别清楚的一篇
http://alanland.iteye.com/blog/612459
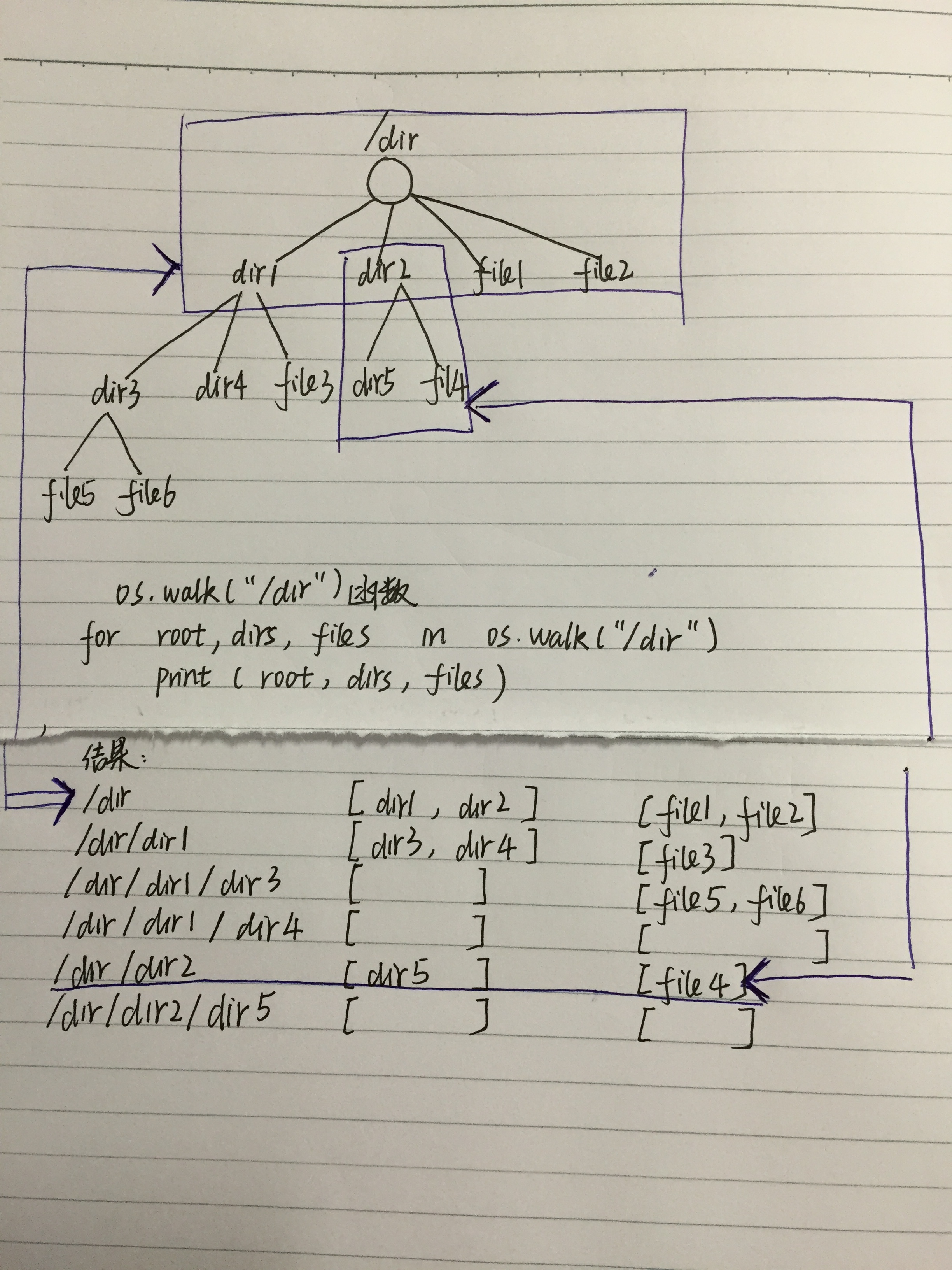
我们可以看到,返回的是一个元组,元祖每一个元素即上面一行的内容,所以用for去遍历它。
然后对应的将这行的第一列的内容给root
第二列 给dirs
第三列 给files
元组每一个元素就是遍历一棵树(包括子树) 根的孩子(注意 不是子孙),如上图中蓝色框中的内容
[(根,孩子文件夹,孩子文件),
(子根,孩子文件夹,孩子文件),
(子根,孩子文件夹,孩子文件),
(子根,孩子文件夹,孩子文件)]
应用:
1.遍历文件夹下的所有文件(为了方便,假设只有一层文件夹)
for parent, dir_names, file_names in os.walk(person_dir):
for file_name in file_names:
print file_name就可以遍历所有的file了
解析:os.walk("/dir")返回的结果是这样的
( /dir, [dir1,dir2......], [ file1,file2,................] ),
( /dir/dir1 , [] , [file10,file12......] ) ,
( /dir/dir2 , [] [file20,...........] ) ,
................................
第一趟循环
parent 为: /dir
dir_names为:[dir1,dir2,.....dirn],
file_names为:[file1,file2,...............]
此时执行for file_name in file_names:
则内循环print出file1,file2.........
即打印出根目录dir下所有文件
第二趟循环
parent 为: /dir/dir1
dir_names为: [],
file_names为:[file10,file12......]
此时执行
for file_name in file_names:则内循环print出file10,file12......... 即打印出dir2下的所有文件
第三趟循环...................
2.那么如何读取所有文件夹名字呢?
for parent, dir_names, file_names in os.walk(person_dir):
for dir_name in dir_names:
print dir_name
第一趟循环
parent 为/dir
dir_names为 [dir1,dir2,.....dirn],
file_names为[file1,file2,............... ]
此时执行
for dir_name in dir_names则内循环print出dir1,dir2, dir3.........
即打印出根目录dir下所有文件夹
第二趟循环
parent 为/dir/dir1
dir_names为 [],
file_names为[file10,file12......]
此时执行
for file_name in file_names:则内循环 为空
第三趟循环内循环同样为空
剩下的内循环同样为空(见上述假设)
这样就打印出了所有文件夹
3.如果只想读取根目录下文件夹下的文件,不想读取根目录下的文件(假设根目录下的文件夹中没有文件夹,只有文件)
for parent, dir_names, file_names in os.walk(dir):
for dir_name in dir_names:
for parent2, dir_names2, file_names2 in os.walk(dir+dir_name):
for file_name in file_names2:请自行体会














 8877
8877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









