






VietOCR 官网原文链接 VietOCR
VietOCR, available in Java and .NET executable, is a GUI frontend for Tesseract OCR engine. Both versions sport similar graphic user interface and are capable of recognizing text from images of common formats. The program can also function as a console application, executing from the command line.
Batch processing is supported as well. The program monitors a watch folder for new image files, automatically processes them through the OCR engine, and outputs recognition results to an output folder.
Language data for Vietnamese and English is already bundled with the program. Data for other languages can be downloaded from Tesseract website and should be placed into tessdata folder. Note that the language data files for Tesseract 2.0x and 3.0 are of different format and not interchangeable, so be sure to download the ones compatible with your Tesseract version (2.0x - 3.02, 3.03, and 4.00).
Notes: Some languages — such as Arabic or Hindi — have cube components; they need to be downloaded and copied into tessdata as well.
Installation
The Java version requires Java Runtime Environment 8 or later (installation instructions). On Windows, Microsoft Visual C++ 2015-2019 Redistributable Package is also required.
For Linux, Tesseract and its language data packages are in the Graphics (universe) repository. They can be installed using Synaptic or by the following command:
sudo apt-get install tesseract-ocr tesseract-ocr-vie
The files will be placed in /usr/bin and /usr/share/tesseract-ocr/tessdata, respectively.
On the other hand, if Tesseract is built and installed from the source, they will be placed in /usr/local/bin and /usr/local/share/tessdata. VietOCR is designed to know the language data files at those locations; however, in case tessdata is located in another directory besides those mentioned, you will need to set the environment variable TESSDATA_PREFIX, for example:
export TESSDATA_PREFIX=/usr/local/share/
(or equivalent) in your .profile or whatever or setenv to set the environment variable. Note that the directory path must end in a /.
Optionnal support for Tess4J library is provided. Be noted that any exception from inside Tess4J will cause the program to crash.
The .NET version requires Microsoft .NET Framework 4.8. If you encounter "Exception has been thrown by the target of an invocation" or "The program can't start because VCRUNTIME140.dll is missing from your computer" errors, please install Microsoft Visual C++ 2015-2019 Redistributable Package.
|
|
|
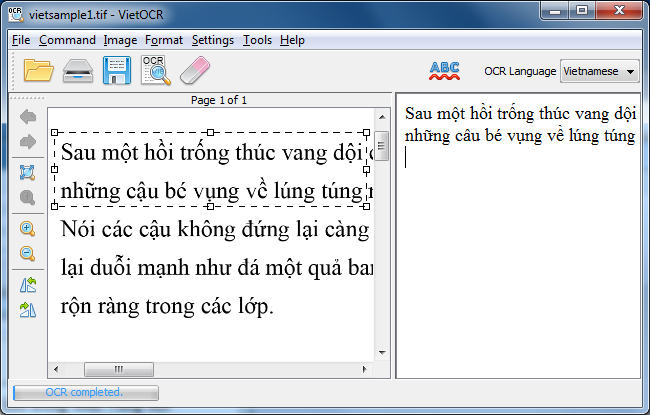
| Figure 1: VietOCR.NET WinForm GUI | Figure 2: VietOCR Swing GUI |

Scanning support on Windows is provided via the Windows Image Acquisition Library v2.0, which requires Windows XP Service Pack 1 (SP1) or later; the library comes standard with Windows Vista and 7. To install the WIA Library on Windows XP, copy the wiaaut.dll file to your System32 directory (usually located at C:\Windows\System32) and run from the command line:
regsvr32 C:\Windows\System32\wiaaut.dll
On Linux, scanning requires installation of SANE packages:
sudo apt-get install libsane sane sane-utils libsane-extras xsane
PDF support is possible via GPL Ghostscript. After installation of the library, please ensure the shared library object (gsdll32.dll or libgs.so) is in the search path by setting the appropriate environment variable. On Windows, append the following to Path value (accessible through Control Panel > System > Advanced > Environment Variables) for GS version 9.52:
;C:\Program Files\gs\gs9.52\bin
To install GS on Linux:
sudo apt-get install ghostscript
To set path:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
where in /usr/local/lib, libgs.so link to libgs.so.9.52 is located. However, this step may not be needed since path might have been set during the installation of GS.
Spellcheck functionality is available through Hunspell, whose dictionary files (.aff, .dic) should be placed in dict folder of VietOCR. user.dic is an UTF-8-encoded file which contains a list of custom words, one word per line.
On Linux, Hunspell and its dictionaries can be installed by Synaptic or apt, as follows:
sudo apt-get install hunspell hunspell-en-us
OCR Operation
The included Vietnamese language data were generated specifically for Times New Roman, Arial, Verdana, and Courier New fonts. Therefore, the recognition would have better success rate for images having similar font glyphs. OCRing images that have font glyphs look different from the supported fonts generally will require training Tesseract to create another language data pack specifically for those typefaces.
Update: More language data has been generated for legacy Vietnamese fonts, VNI and TCVN3 (ABC). It can be downloaded through the Download Language Data submenu.
The images to be OCRed should be scanned at resolution from at least 200 DPI (dot per inch) to 400 DPI. Scanning at higher resolutions will not necessarily result in better recognition accuracy, which currently can be higher than 97% for Vietnamese (reference image) — the next release of Tesseract may improve it even further. Even so, the actual rates still depend greatly on the quality of the scanned image.
The typical settings for scanning are 300 DPI and 1 bpp (bit per pixel) black&white or 8 bpp grayscale uncompressed TIFF or PNG format. PNG is smaller in size than other image formats and still keeps high quality due to its employing lossless data compression algorithms; TIFF has the advantage of the ability to contain multiple images (pages) in a file.
The Screenshot Mode offers better recognition rates for low-resolution images, such as screen prints, by rescaling them to 300 DPI.
Tips: OCR on selection zones on the image (region of interest) defined by mouse drag is generally found to produce better accuracy.
In addition to the built-in text postprocessing algorithm, you can add your own custom text replacement scheme via a UTF-8-encoded tab-delimited text file named x.DangAmbigs.txt, where x is the ISO639-3 language code. Both plain and Regex text replacements are supported.
Some built-in tools are provided to merge several images or PDF files into a single one for convenient OCR operations, or to split a PDF file into smaller ones if it is too large, which can cause out-of-memory exceptions. Pasting images from clipboard is supported.
Postprocessing
The recognition errors can be classified into three categories. Many of the errors are related to the letter cases — for example: hOa, nhắC — which can be easily corrected by popular Unicode text editors. Many other errors are a result of the OCR process, such as missing diacritical marks, wrong letters with similar shape, etc. — huu – hưu, mang – marg, h0a – hoa, la – 1a, uhìu - nhìn. These can also be easily fixed by Vietnamese spell checker programs. VietOCR's built-in Postprocessing function can help correct many of the above errors.
The last category of errors is more difficult to detect because they are semantic errors, which means that the words are valid entries in the dictionary but are wrong in the context — e.g., tinh – tình, vân – vấn. These errors require the editor to read though and manually correct them according to the original image.
The following editing process using the built-in functionality is suggested:
- Group lines. The lines need to be grouped to the paragraph they belong, as being OCRed, each line becomes a separate 1-line paragraph. Use Remove Line Breaks function under Format menu. Note that this operation may not be needed for poems.
- Select Change Case, also under Format menu, and choose Sentence case to correct the letter case errors. Locate and fix the rest of remaining letter case errors.
- Correct the misspelled errors using the integrated Spell Check.
Through the above steps, most of common errors should be eliminated. The remaining, semantic errors are few, but it requires a human editor to read though and make necessary edits to make the document look just like the original scanned document. If heavier editing is required, you can use word processors or full-featured text editors — Word, Writer, Notepad, VietPad, etc. — for such task.
Limitations
Tesseract 2.0x does not support page layout, therefore can only recognize one column text. Tesseract 3.0x has included page layout analysis, supporting recognition of multi-column documents.















 3004
3004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









