







最近和实验室的朋友尝试着在几台虚拟机上搭了搭Hadoop,期间遇到很多问题,百度上很多答案要么是表意不清,要么是版本太老,坑得我们走了很多弯路。其实只要理解了相应的配置文件和操作,还是很简单的,一个下午安装hadoop,hbase,zookeeper,nutch问题不大。才接触hadoop不久,有需要改进的地方希望朋友们给指出来,谢啦。
我是根据虾皮工作室的这篇文章来安装的:点击打开链接,里面解释得非常清楚,小白理解起来也绝不会有压力。
1、集群部署介绍
1.1环境说明
由于实验室服务器资源有限,我们也分为好几个hadoop小组,每组的实验资源是四台虚拟机,分别模拟集群中的4个节点,各节点均为Centos6.3系统,创建的账户名均为hadoop。
节点IP地址分布如下:
机器名称: IP地址:
Master 172.31.62.51
Slave1 172.31.62.52
Slave2 172.31.62.53
Slave3 172.31.62.54
Master机器主要配置NameNode和JobTracker的角色(小集群无需分开配置),负责总管分布式数据和分解任务的执行;3个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
1.2 网络配置
1)修改当前机器名称:
通过vim /etc/sysconfig/network 修改其中的HOSTNAME属性值
2)修改IP地址:
修改/etc/sysconfig/network-scripts/ifcfg-eth0 中的“IPADDR”属性
3)配置/etc/hosts文件:
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息,是记载各主机的对应[HostName和IP]用的。在进行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的"/etc/hosts"文件末尾中都要添加如下内容:
172.31.62.51 Master
172.31.62.52 Slave1
172.31.62.53 Slave2
172.31.62.54 Slave3
此处我们应注意一点:hosts文件中对应有”127.0.0.1”一项,默认对应于”localhost”或”centos”,应将此属性值删除。
注:由于127.0.0.1是回送地址,主要用于网络软件测试以及本地机进程间通信,无论什么程序,一旦使用回送地址发送数据,协议软件立即返回,不进行任何网络传输。猜测:此处如果不删除,可能会无法启动namenode,就像“本机被屏蔽”一样,之后的Hbase配置也与此有关,所以最好还是将该项删除。
1.3所需软件
1)jdk
虽然此centos内置openjdk,但考虑到openjdk只包含最精简的JDK,不包含部署功能,无Rhino Java DB JAXP等软件包,为了后期开发方便还是安装了jdk1.8.0,其jdk安装地址为:
/usr/jdk1.8
2)hadoop(1.2.1版本)
下载地址:http://hadoop.apache.org/common/releases.html
3)使用Xshell连接到虚拟机,它自带了XFTP可以传文件,无需使用VSFTP。
2、SSH无密码访问验证配置
在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到NameNode。
2.1通过以下两个命令,我们得知ssh和rsync服务已经安装:
rpm –qa |grep openssh
rpm –qa |grep rsync
2.2配置Master无密码登陆Slave
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
2)Master机器上生成密码对
在Master节点上执行以下命令:
ssh -keygen –t rsa –P ''
生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。接着执行:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
把id_rsa.pub追加到授权的key里面去。在验证前,需要修改文件"authorized_keys"权限,还要用root用户设置"/etc/ssh/sshd_config"的内容。使其无密码登录有效。
1.chmod 600 ~/.ssh/authorized_keys
2.Vim /etc/ssh/sshd_config
RSAAuthenticationyes # 启用 RSA 认证
PubkeyAuthenticationyes # 启用公钥私钥配对认证方式
AuthorizedKeysFile.ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
设置完之后重启SSH服务,service sshd restart,使刚才设置有效。
验证是否成功:ssh localhost
如Master成功登陆Slave1,会显示
Last login: Sun Jan 18 22:45:30 2015 from 172.31.62.253
然后把公钥复制所有的Slave机器上。使用下面的命令格式进行复制公钥:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
下面就针对IP为"172.31.62.52"的Slave1.Hadoop的节点进行配置。
1) 把Master.Hadoop上的公钥复制到Slave1.Hadoop上
2)在"/home/hadoop/"下创建".ssh"文件夹:mkdir ~/.ssh,并修改权限:chmod 700 ~/.ssh
3)追加到授权文件"authorized_keys"
使用下面命令进行追加并修改"authorized_keys"文件权限:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600~/.ssh/authorized_keys
追加成功后可cat authorized_keys查看,里面是一堆乱七八糟的序列,但可以看到刚才追加了keys的对应主机名。
4)用root用户修改"/etc/ssh/sshd_config"
5)用Master.Hadoop使用SSH无密码登录Slave1.Hadoop
当前面的步骤设置完毕,就可以使用下面命令格式进行SSH无密码登录了。
ssh 远程服务器IP
最后把"/home/hadoop/"目录下的"id_rsa.pub"文件删除掉。
rm –r~/id_rsa.pub
到此为止,我们实现了从"Master.Hadoop"到"Slave1.Hadoop"SSH无密码登录,下面就是重复上面的步骤把剩余的两台(Slave2.Hadoop和Slave3.Hadoop)Slave服务器进行配置。这样,我们就完成了"配置Master无密码登录所有的Slave服务器"。因为要使得从Slave到Master相互间可以无密码登陆,故技重施,将Slave生成的公钥追加到Master之中,此处从略。最后完成效果应该是:Master能无密码验证登录每个Slave,每个Slave也能无密码验证登录到Master。
3、安装JAVA
此处从略,安装好后记得配置环境变量。
在尾部加入:
# setjava environment
exportJAVA_HOME=/usr/jdk1.8
exportCLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
exportPATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
执行下面命令使其配置立即生效。
source /etc/profile (*必不可少)
java–version
验证JDK无问题。
4、Hadoop集群安装
把"hadoop-1.2.1.tar.gz"复制到"/usr"目录下面。
cp/home/hadoop/hadoop-1.2.1.tar.gz /usr/new/
把"hadoop-1.0.0.tar.gz"进行解压,并将其命名为"hadoop",把该文件夹的读权限分配给普通用户hadoop,然后删除"hadoop-1.0.0.tar.gz"安装包。最后在"/usr/new/hadoop"下面创建tmp文件夹:
1.tar -zxvf hadoop-1.0.0.tar.gz
2.mv hadoop-1.0.0.tar.gz hadoop
3.[root@Master usr]chown -R hadoop:hadoop hadoop (递归地将hadoop文件夹权限分配给hadoop用户,冒号两端分别为用户和所在组名)
把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件(配置java环境变量的文件),将以下语句添加到末尾,并使其有效:
# sethadoop path
exportHADOOP_HOME=/usr/new/hadoop
exportPATH=$PATH:$HADOOP_HOME/bin
(可建立软连接: ln -s /usr/new/hadoop /hadoop )
4.2 配置hadoop
1)配置hadoop-env.sh
在文件的末尾添加下面内容。
# setjava environment
export JAVA_HOME=/usr/jdk1.8
Hadoop配置文件在conf目录下,之前的版本的配置文件主要是Hadoop-default.xml和Hadoop-site.xml。由于Hadoop发展迅速,代码量急剧增加,代码开发分为了core,hdfs和map/reduce三部分,配置文件也被分成了三个core-site.xml、hdfs-site.xml、mapred-site.xml。
2)配置core-site.xml文件
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/new/hadoop/tmp</value>
<description>A base for othertemporary directories.</description>
</property>
<!--file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://172.31.62.51:9000</value>
</property>
</configuration>
备注:hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果不配置它会默认指向临时目录,而该目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。fs.default.name是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表
3)配置hdfs-site.xml文件
修改Hadoop中HDFS的配置,配置的备份方式默认为3。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>(备注:replication 是数据副本数量,默认为3,salve少于3台就会报错)
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/new/hadoop/data</value> (这个参数用于确定将HDFS文件系统的数据保存在什么目录下)
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/new/hadoop/tmp</value>(这个参数用于确定将HDFS文件系统的元信息保存在什么目录下,namenode下配置)
</property><configuration>
4)配置mapred-site.xml文件
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://172.31.62.51:9001</value>
</property>
</configuration>
5)配置masters文件
去掉"localhost",加入Master机器的IP:172.31.62.51
6)配置slaves文件(Master主机特有)
去掉"localhost",加入集群中所有Slave机器的IP,也是每行一个。
现在在Master机器上的Hadoop配置就结束了,剩下的就是配置Slave机器上的Hadoop。
将 Master上配置好的hadoop所在文件夹"/usr/new/hadoop"复制到所有的Slave的"/usr"目录下。用下面命令格式进行。(备注:此时用户可以为hadoop也可以为root)
scp -r/usr/hadoop root@服务器IP:/usr/
此时,我们要将hadoop文件夹的权限进行修改,要给要给"Slave1.Hadoop"服务器上的用户hadoop添加对"/usr/new/hadoop"读权限,否则在启动hadoop时会出现权限不足的问题。以root用户登录"Slave1.Hadoop",执行:chown -R hadoop:hadoop(用户名:用户组)hadoop(文件夹)
接着在"Slave1 .Hadoop"上修改"/etc/profile"文件(配置 java 环境变量的文件),配置hadoop的环境变量,参照Master配置即可,并使其有效(source /etc/profile)。
到此为此在一台Slave机器上的Hadoop配置就结束了。剩下的事儿就是照葫芦画瓢把剩余的几台Slave机器进行部署Hadoop。
4.3启动及验证
1)格式化HDFS文件系统
在"Master.Hadoop"上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode -format
2)启动hadoop
在启动前关闭集群中所有机器的防火墙(每次机器reboot都要重新关闭),不然会出现datanode开后又自动关闭。
service iptables stop
使用下面命令启动:
start-all.sh(stop-all.sh是关闭)
可以通过以下启动日志看出,首先启动namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动jobtracker,然后启动tasktracker1,tasktracker2,…。启动 hadoop成功后,在 Master 中的 tmp 文件夹中生成了 dfs 文件夹,在Slave 中的 tmp 文件夹中均生成了 dfs 文件夹和 mapred 文件夹。
3)验证hadoop
(1)验证方法一:用"jps"命令
在Master上用java自带的小工具jps查看进程:
xxxx NameNode
xxxx JobTracker
xxxx SecondaryNameNode
xxxx Jps
在Slave1上用jps查看进程:
xxxx TaskTracker
xxxx DataNode
xxxx Jps
(2)验证方式二:用"hadoop dfsadmin -report"
用这个命令可以查看Hadoop集群的状态:
Configured Capacity: 627311050752 (584.23 GB)
Present Capacity: 575630934016 (536.1 GB)
DFS Remaining: 569248821248 (530.15 GB)
DFS Used: 6382112768 (5.94 GB)
DFS Used%: 1.11%
Under replicated blocks: 3
Blocks with corrupt replicas: 0
Missing blocks: 0
出现类似的信息即可。
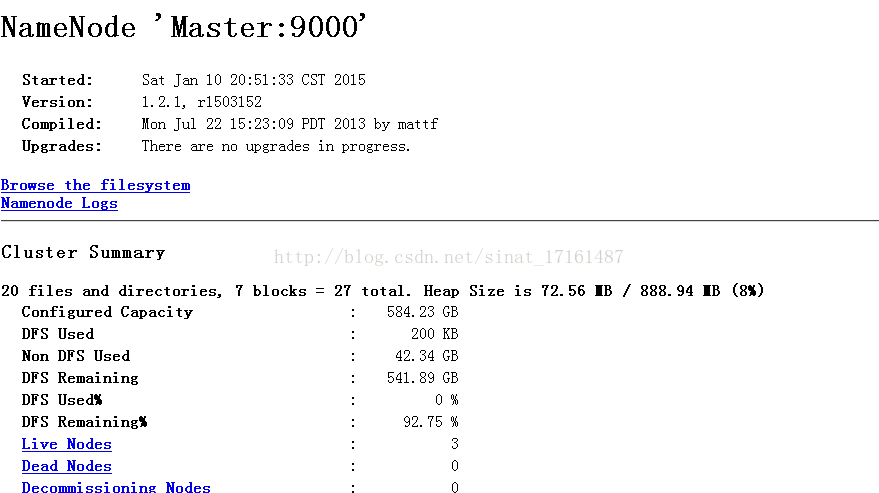
4.4 网页查看集群
1)访问"http:172.31.62.51:50030"
2)访问"http: 172.31.62.51:50070"















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









