







B站历史弹幕爬虫
以b站弹幕最多的天鹅臂视频为例,可视化效果见哪位艺人的老婆们最有毅力?b站弹幕爬虫及可视化。
1. 最新弹幕
最新弹幕可以通过NetWork中的list.so...获取,具体操作可参考历史弹幕的爬取。
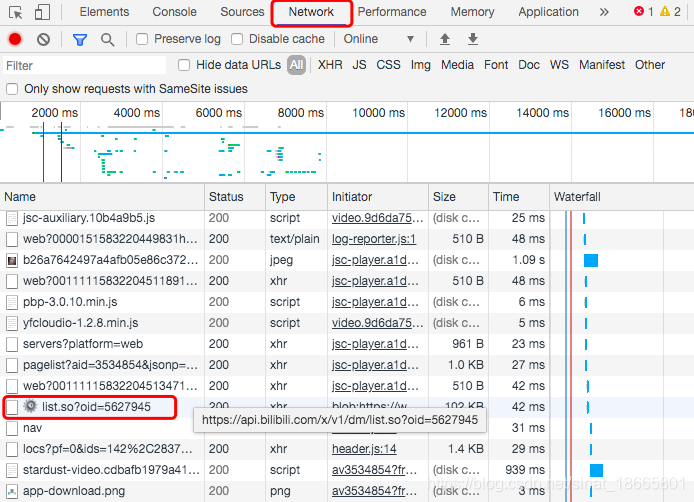
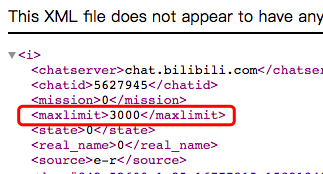
但是最新弹幕只能最多获取3000条,如果视频的弹幕超过3000条,则需要通过别的方式获取。
2. 历史弹幕
2.1 探索
观察弹幕列表可以发现,b站提供了历史弹幕的查看途径。
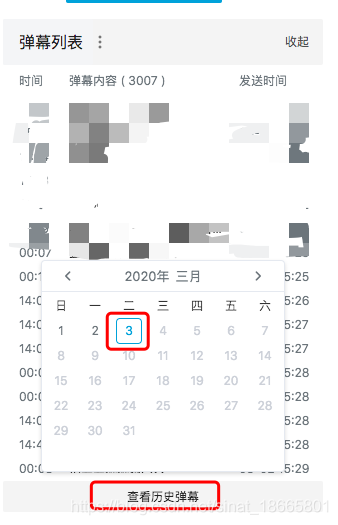
点击不同的日期,可以发现不断有以history?开头的资源加载进来。
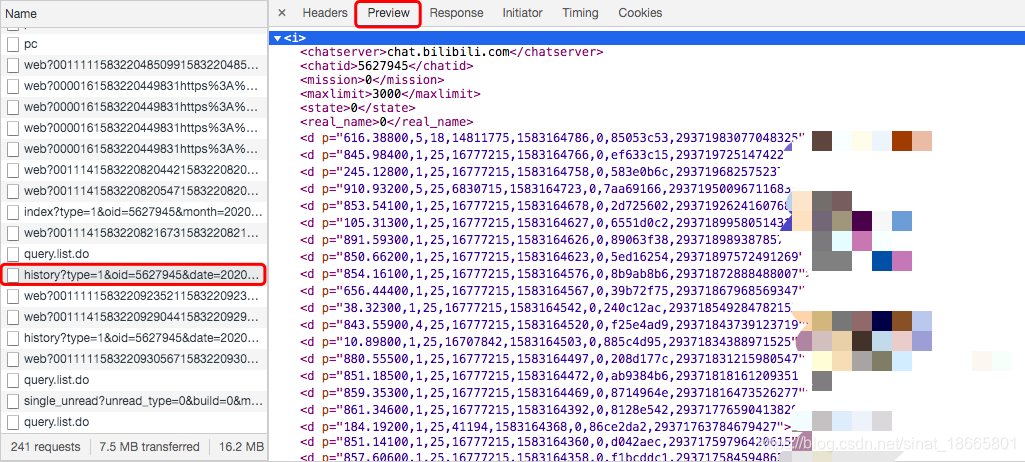
从预览中可以看到,其实就是对应日期最新的3000条弹幕。观察一下url,有关的参数是type、oid和date,oid就是视频对应的id,date则是日期,type暂时不知道干哈的。
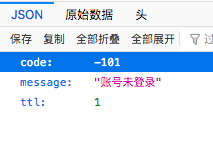
https://api.bilibili.com/x/v2/dm/history?type=1&oid=5627945&date=2020-03-02
再把这个网址放到没有登录b站账号的浏览器打开,显示账号未登录,也就是需要登录才能获取数据,可以考虑用模拟登录解决。
2.2 数据获取
2.2.1 模拟登录
用的是selenium搭配谷歌浏览器,需要先配置一下和浏览器版本匹配的驱动,可自行百度或参考这里的第五点。
# 导入需要的包
from bs4 import BeautifulSoup as bs
import pandas as pd
import re
from selenium import webdriver
import time, datetime
# 模拟登录
## 登录界面链接
url = 'https://passport.bilibili.com/login'
## 模拟登录启动
driver = webdriver.Chrome()
driver.get(url)
## 接下来就是在打开的谷歌浏览器里手动登录一下自己的账号,
## * 因为b站登录需要验证,这一步自动化的代价比较大,所以手动了。
2.2.2 获取每一天的数据
探索部分,看看即可:
# 以2019-01-01为例
date = '2019-01-01'
url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid=5627945&date=%s'%date
# 转入历史弹幕的页面
driver.get(url)
# 获取数据部分的html
html = driver.find_element_by_tag_name('i').get_attribute('innerHTML')
# 解析
soup = bs(html, 'lxml')
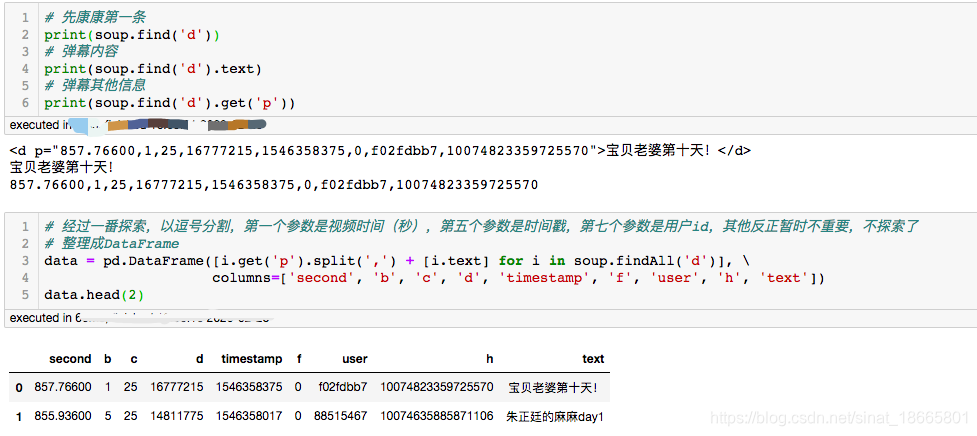
# 先康康第一条
print(soup.find('d'))
# 弹幕内容
print(soup.find('d').text)
# 弹幕其他信息
print(soup.find('d').get('p'))
# 经过一番探索,以逗号分割,第一个参数是视频时间(秒),第五个参数是时间戳,第七个参数是用户id,其他反正暂时不重要,不探索了
# 整理成DataFrame
data = pd.DataFrame([i.get('p').split(',') + [i.text] for i in soup.findAll('d')], \
columns=['second', 'b', 'c', 'd', 'timestamp', 'f', 'user', 'h', 'text'])
data.head(2)
封装成函数后:
def get_per_day(date):
# url
url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid=5627945&date=%s'%date
# 转入历史弹幕的页面
driver.get(url)
# 获取并解析
soup = bs(driver.find_element_by_tag_name('i').get_attribute('innerHTML'), 'lxml')
# 整理成DataFrame
data = pd.DataFrame([i.get('p').split(',') + [i.text] for i in soup.findAll('d')], \
columns=['second'< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









