






前言(容器编排兴起的原因)
Kubernetes的本质,从容器到容器云。
在Linux中,容器的具体实现方式,实际上是一个由Linux Namespace、Linux Cgroups和rootfs三种技术构建出来的进程的隔离环境。
一个正在运行的Linux容器,其实可以被“一分为二”地看待:
- 一组联合挂载在/var/lib/docker/aufs/mnt上的rootfs,这一部分我们称为“容器镜像”(Container Image),是容器的静态视图;
- 一个由Namespace+Cgroups构成的隔离环境,这一部分我们称为“容器运行时”(Container Runtime),是容器的动态视图。
在整个“开发-测试-发布”的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。 这正是容器圈在Docker项目成功后不久,迅速走向了“容器编排”这个“上层建筑”的主要原因:作为一家云服务商或者基础设施提供商,只要能够将用户提交的Docker镜像以容器的方式运行起来,就能成为这个非常热闹的容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在我的这个节点上。
更重要的是,只要从我这个承载点向Docker镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如CI/CD、监控、安全、网络、存储等等,都有我可以发挥和盈利的余地。这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和潜在用户(即,开发者)直接关联起来。 容器技术实现了从“容器”到“容器云”的飞跃,标志着它真正得到了市场和生态的认可。
这样,容器就从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角;而能够定义容器组织和管理规范的“容器编排”技术,则当仁不让地坐上了容器技术领域的“头把交椅”。
Kubernetes项目
首先,Kubernetes项目要解决的问题是什么?
编排?调度?容器云?还是集群管理?
Kubernetes项目的架构,跟它的原型项目Borg非常类似,都由Master和Node两种节点组成,而这两种角色分别对应着控制节点和计算节点:
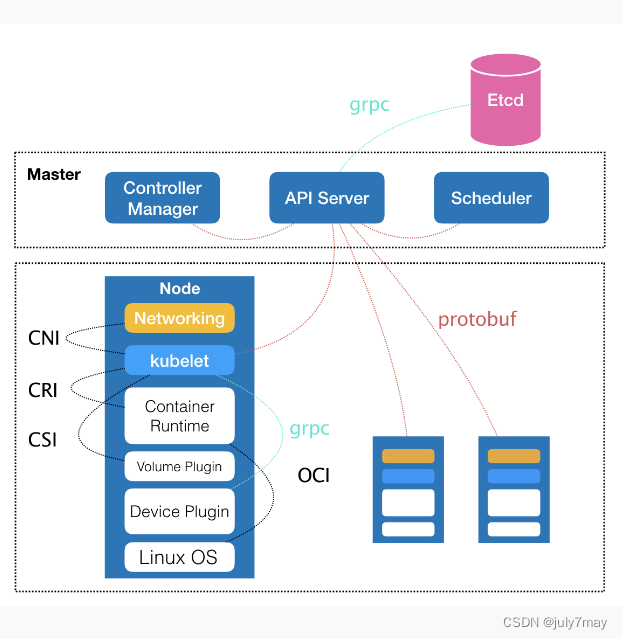
其中,控制节点,即Master节点,由三个紧密协作的独立组件组合而成,它们分别是负责API服务的kube-apiserver、负责调度的kube-scheduler,以及负责容器编排的kube-controller-manager。整个集群的持久化数据,则由kube-apiserver处理后保存在Etcd中。
而计算节点上最核心的部分,则是一个叫作kubelet的组件。在Kubernetes项目中,kubelet主要负责同容器运行时(比如Docker项目)打交道。而这个交互所依赖的,是一个称作CRI(Container Runtime Interface)的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。
Kubernetes项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现CRI接入到Kubernetes项目当中。而具体的容器运行时,比如Docker项目,则一般通过OCI这个容器运行时规范同底层的Linux操作系统进行交互,即:把CRI请求翻译成对Linux操作系统的调用(操作Linux Namespace和Cgroups等)。
此外,kubelet还通过gRPC协议同一个叫作Device Plugin的插件进行交互。这个插件,是Kubernetes项目用来管理GPU等宿主机物理设备的主要组件,也是基于Kubernetes项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
kubelet的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与kubelet进行交互的接口,分别是CNI(Container Networking Interface)和CSI(Container Storage Interface)。
从一开始,Kubernetes项目就没有像同时期的各种“容器云”项目那样,把Docker作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。Kubernetes项目要着重解决的问题,来自于Borg的研究人员在论文中提到的一个非常重要的观点:
运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
Kubernetes项目最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
k8s核心功能
全景图:

从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了Pod;有了Pod之后,我们希望能一次启动多个应用的实例,这样就需要Deployment这个Pod的多实例管理器;而有了这样一组相同的Pod后,我们又需要通过一个固定的IP地址和端口以负载均衡的方式访问它,于是就有了Service。
如果现在两个不同Pod之间不仅有“访问关系”,还要求在发起时加上授权信息。最典型的例子就是Web应用对数据库访问时需要Credential(数据库的用户名和密码)信息。Kubernetes项目提供了一种叫作Secret的对象,它其实是一个保存在Etcd里的键值对数据。这样,你把Credential信息以Secret的方式存在Etcd里,Kubernetes就会在你指定的Pod(比如,Web应用的Pod)启动时,自动把Secret里的数据以Volume的方式挂载到容器里。这样,这个Web应用就可以访问数据库了。
除了应用与应用之间的关系外,应用运行的形态是影响“如何容器化这个应用”的第二个重要因素。
为此,Kubernetes定义了新的、基于Pod改进后的对象。比如Job,用来描述一次性运行的Pod(比如,大数据任务);再比如DaemonSet,用来描述每个宿主机上必须且只能运行一个副本的守护进程服务;又比如CronJob,则用于描述定时任务等等。
设计核心:声明式API
Kubernetes项目并没有像其他项目那样,为每一个管理功能创建一个指令,然后在项目中实现其中的逻辑。这种做法,的确可以解决当前的问题,但是在更多的问题来临之后,往往会力不从心。
相比之下,Kubernetes项目中所推崇的使用方法是:
- 首先,通过一个“编排对象”,比如Pod、Job、CronJob等,来描述你试图管理的应用;
- 然后,再为它定义一些“服务对象”,比如Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式API”。这种API对应的“编排对象”和“服务对象”,都是Kubernetes项目中的API对象(API Object)。这就是Kubernetes最核心的设计理念。
附
此文章为3月Day13学习笔记,内容来源于极客时间《深入剖析Kubernetes》
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









