






本篇主要对 SOFARegistry 的数据同步模块进行解析,对于注册中心的概念以及 SOFARegistry 的基础架构不做过多阐述,相关介绍可以见海量数据下的注册中心 - SOFARegistry 架构介绍 这篇文章。
本文主要写作思路大致分为下面 2 个部分:第一部分借助 SOFARegistry 中的角色分类来说明哪些角色之间会进行数据同步,第二部分对数据同步的具体实现进行解析。
SOFARegistry 的角色分类
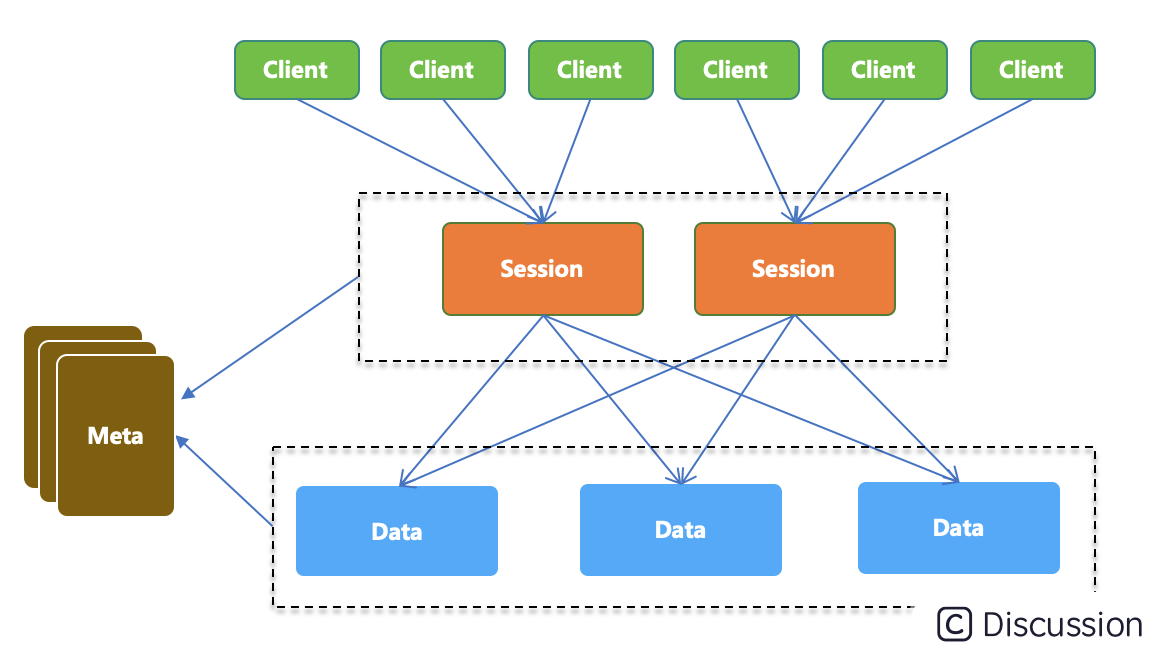
如上图,SOFARegistry 包含 4 个角色:
| 角色 | 说明 | | --- | --- | | Client | 提供应用接入服务注册中心的基本 API 能力,应用系统通过依赖客户端 JAR 包,通过编程方式调用服务注册中心的服务订阅和服务发布能力。 | | SessionServer | 会话服务器,负责接受 Client 的服务发布和服务订阅请求,并作为一个中间层将写操作转发 DataServer 层。SessionServer 这一层可随业务机器数的规模的增长而扩容。 | | DataServer | 数据服务器,负责存储具体的服务数据,数据按 dataInfoId 进行一致性 Hash 分片存储,支持多副本备份,保证数据高可用。这一层可随服务数据量的规模的增长而扩容。 | | MetaServer | 元数据服务器,负责维护集群 SessionServer 和 DataServer 的一致列表,作为 SOFARegistry 集群内部的地址发现服务,在 SessionServer 或 DataServer 节点变更时可以通知到整个集群。 |
在这 4 个角色中,MetaServer 作为元数据服务器本身不处理实际的业务数据,仅负责维护集群 SessionServer 和 DataServer 的一致列表,不涉及数据同步问题;Client 与 SessionServer 之间的核心动作是订阅和发布,从广义上来说,属于用户侧客户端与 SOFARegistry 集群的数据同步,可以见:https://github.com/sofastack/sofa-registry/issues/195,因此不在本文讨论范畴之内。
SessionServer 作为会话服务,它主要解决海量客户端连接问题,其次是缓存客户端发布的所有 pub 数据;session 本身不持久化服务数据,而是将数据转写到 DataServer。DataServer 存储服务数据是按照 dataInfoId 进行一致性 Hash 分片存储的,支持多副本备份,保证数据高可用。
从 SessionServer 和 DataServer 的功能分析中可以得出:
- SessionServer 缓存的服务数据需要与 DataServer 存储的服务数据保持一致
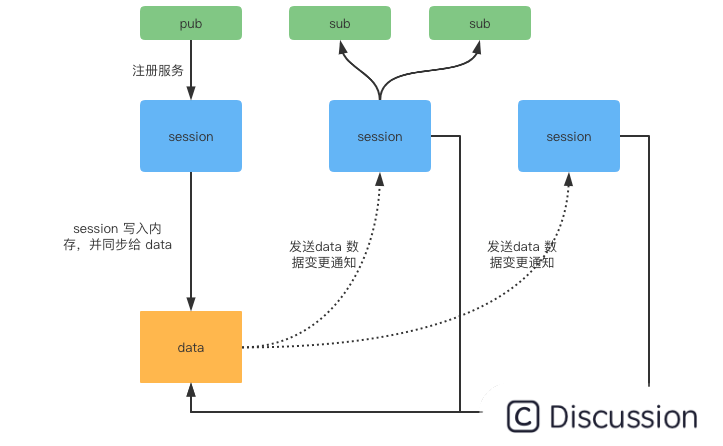
- DataServer 支持多副本来保证高可用,因此 DataServer 多副本之间需要保持服务数据一致。
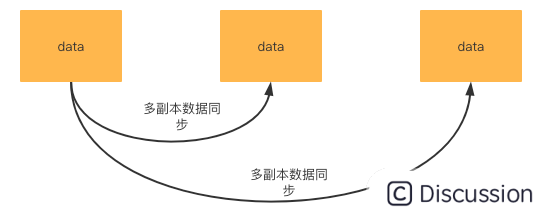
SOFARegistry 中对于上述两个对于数据一致性保证就是通过数据同步机制来实现的。
数据同步的具体实现
下面主要介绍数据同步的实现细节,主要包括 SessionServer 和 DataServer 之间的数据同步 和 DataServer 多副本之间的数据同步两块。
SessionServer 和 DataServer 之间的数据同步
SessionServer 和 DataServer 之间的数据同步,是基于推拉结合的机制
- 推:DataServer 在数据有变化时,会主动通知 SessionServer,SessionServer 检查确认需要更新(对比 version) 后主动向 DataServer 获取数据。
- 拉:除了上述的 DataServer 主动推以外,SessionServer 每隔一定的时间间隔,会主动向 DataServer 查询所有 dataInfoId 的 version 信息,然后再与 SessionServer 内存的 version 作比较,若发现 version 有变化,则主动向 DataServer 获取数据。这个“拉”的逻辑,主要是对“推”的一个补充,若在“推”的过程有错漏的情况可以在这个时候及时弥补。
关于推和拉两种模式检查的 version 有一些差异,可以详见下面 推模式下的数据同步 和 *拉模式下的数据同步 *中的具体介绍
推模式下的数据同步流程
推模式是通过 SyncingWatchDog 这个守护线程不断 loop 执行来实现数据变更检查和通知发起的。 java // 这里遍历所有的 slot for (SlotState slotState : slotTableStates.slotStates.values()) { try { sync(slotState, syncSessionIntervalMs, syncLeaderIntervalMs, slotTableEpoch); } catch (Throwable e) { SYNC_ERROR_LOGGER.error( "[syncCommit]failed to do sync slot {}, migrated={}", slotState.slot, slotState.migrated, e); } } 按 slot 分组汇总数据版本。data 与每个 session 的连接都对应一个 SyncSessionTask,SyncSessionTask 负责执行同步数据的任务,核心同步逻辑在 com.alipay.sofa.registry.server.data.slot.SlotDiffSyncer#sync方法中完成,大致流程如下面时序图所示: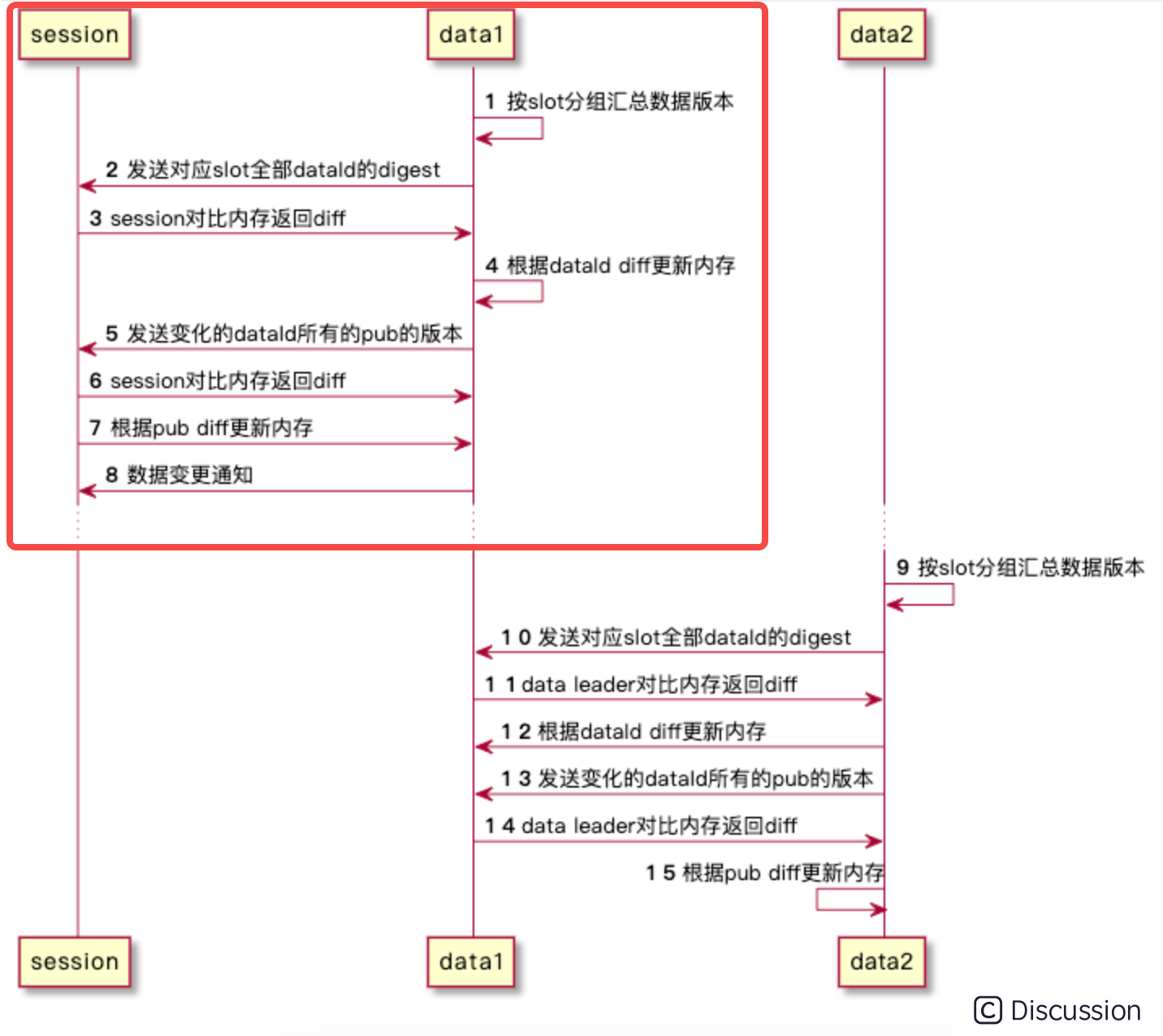
这上图圈红部分的逻辑第四步,根据 dataInfoId diff 更新 data 内存数据,这里仅处理了被移除的 dataInfoId,对于新增和更新的没有做任务处理,而是通过后面的第 5 -7 步来完成;这么做的主要原因在于避免产生空推送导致一些危险情况发生。
第 5 步中,比较的是所有变更 dataInfoId 的 pub version,具体比较逻辑参考后面 diffPublisher 小节中的介绍。
数据变更的事件通知处理
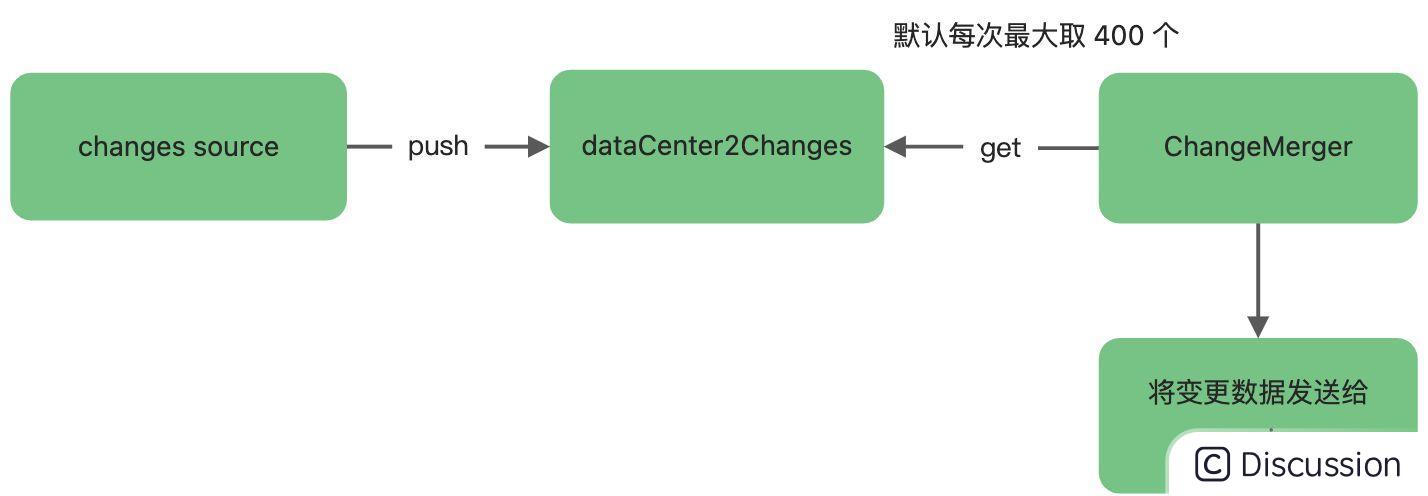
数据变更事件会被收集在 DataChangeEventCenter 的 dataCenter2Changes 缓存中,然后由一个守护线程 ChangeMerger 负责从 dataCenter2Changes 缓存中不断的读取,这些被捞到的事件源会被组装成 ChangeNotifier 任务,提交给一个单独的线程池(notifyExecutor)处理,整个过程全部是异步的。
拉模式下的数据同步流程
拉模式下,由 SessionServer 负责发起,com.alipay.sofa.registry.server.session.registry.SessionRegistry.VersionWatchDog默认情况下每 5 秒扫描一次版本数据,如果版本有发生变更,则主动进行拉取一次,流程大致如下: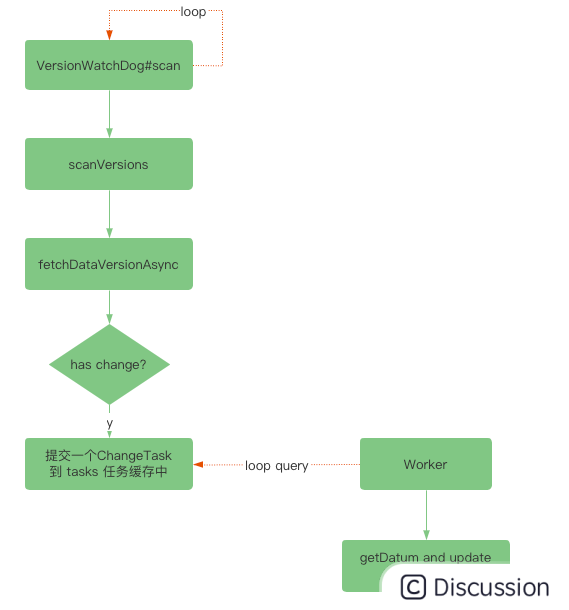
需要注意的是,拉模式对推送流程的补充,这里的 version 是每个 sub 的 lastPushedVersion, 而 推模式的version 是 pub 的数据的 version。关于 lastPushedVersion 的获取可以参考 com.alipay.sofa.registry.server.session.store.SessionInterests#selectSubscribers java store.forEach((String dataInfoId, Map<String, Subscriber> subs) -> { // ... long maxVersion = 0; for (Subscriber sub : subs.values()) { // ... // 获取当前 sub 的 pushVersion final long pushVersion = sub.getPushedVersion(dataCenter); // 如果 pushVersion 比最大(最新)版本大,则将当前 pushVersion 作为最新版本推送版本 if (maxVersion < pushVersion) { maxVersion = pushVersion; } } versions.put(dataInfoId, new DatumVersion(maxVersion)); });
DataServer 多副本之间的数据同步
主要是 slot对应的 data 的 follower 定期和 leader 进行数据同步,其同步逻辑与 SessionServer 和 DataServer 之间的数据同步逻辑差异不大;发起方式也是一样的;data 判断如果当前节点不是 leader,就会进行与 leader 之间的数据同步。 java if (localIsLeader(slot)) { // 如果当前是 leader,则执行 session 同步或者 migrating } else { // 如果当前不是 leader,则和 leader 同步数据 syncLeader(slotState, syncLeaderIntervalMs, slotTableEpoch); }
篇幅原因,这部分不展开讨论。
增量同步 diff 计算逻辑分析
不管是 SessionServer 和 DataServer 之间的同步,还是 DataServer 多副本之间的同步,都是基于增量 diff 同步的,不会一次性同步全量数据。本节对增量同步 diff 计算逻辑进行简单分析,核心代码在 com.alipay.sofa.registry.common.model.slot.DataSlotDiffUtils(建议阅读这部分代码时直接结合代码中的测试用例来看);主要包括计算 digest 和 publishers 两个。
diffDigest
DataSlotDiffUtils#diffDigest 方法接收两个参数
- targetDigestMap 可以理解为目标数据
- sourceDigestMap 可以理解为基线数据
核心计算逻辑如下代码分析



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











