






“””
Created on Mon Jun 20 17:24:22 2016
@author: Red
“””
##笔者目的在于抓取如下加拿大外交及国际贸易署网站中的旅游风险提示及目的地,并从cotent中识别相关地名,最后将提取出的地名进行map可视化:
##主要利用BeautifulSoup及jieba编写爬虫和分词,利用pandas处理数据结构
import urllib
import urllib2
from bs4 import BeautifulSoup
import pandas as pd
import jieba
##模仿浏览器
my_header = {
“Host”: “baidu.com”,
“Connection”: “keep-alive”,
“Cache-Control”: “max-age=0”,
“Accept”: “text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8”,
“User-Agent”: “Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36”,
“Referer”: “http://www.baidu.com“,
“Accept-Language”: “zh-CN,zh;q=0.8”
}
def get_soup(self,url):
##使用代理IP
proxy={‘http’:’124.113.5.3:8118’}
proxy_support=urllib2.ProxyHandler(proxy)
opener=urllib2.build_opener(proxy_support)
urllib2.install_opener(opener)
try:
res=urllib2.urlopen(urllib2.Request(url,headers=my_header))
except urllib2.HTTPError:
return None
else:
page=res.read()
soup=BeautifulSoup(page,from_encoding=’utf-8’)
return soup
##读取停用词词典并转化成小写
stopwords=open(‘c:/users/hzins/desktop/spider/stopwords.txt’,’r’).readlines()
”’
for i in range(len(stopwords)):
stopwords[i]=stopwords[i].lower().strip()
”’
##读取地名词典并转化成小写
dist=open(‘c:/users/hzins/desktop/spider/district_name.txt’,’r’).readlines()
for i in range(len(dist)):
dist[i]=dist[i].lower().strip()
class spider:
def __init__(self):
pass
def get_gcca(self):
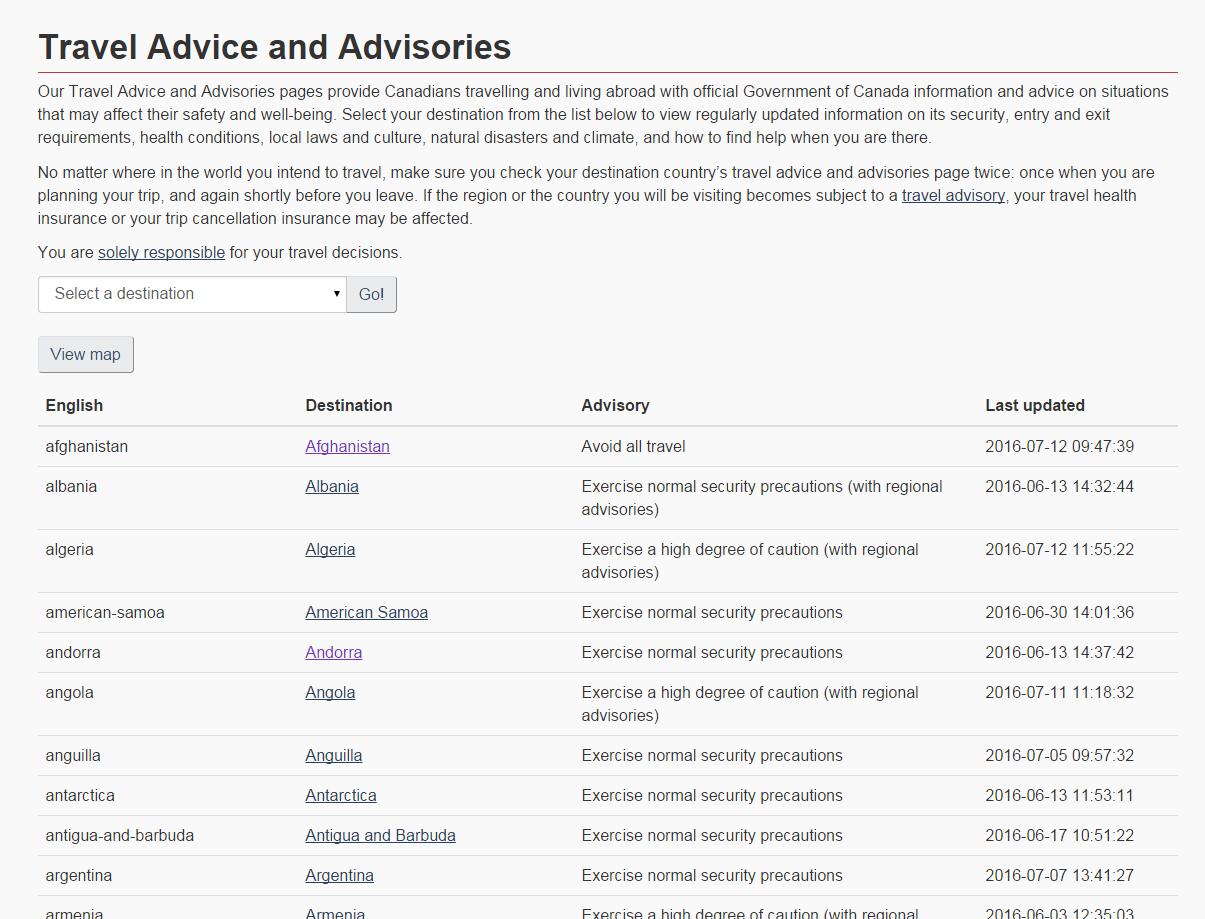
url='https://travel.gc.ca/travelling/advisories'
soup=get_soup(self,url)
info={}
p1=soup.select('.gradeX')
info['date']=[p1[j].select('td')[3].text for j in range(len(p1))]
info['title']=[p1[j].select('td')[2].text for j in range(len(p1))]
info['destination']=[p1[j].select('td')[1].text for j in range(len(p1))]
info['source']=['加拿大外交及国际贸易署网' for j in range(len(p1))]
info['urls']=['https://travel.gc.ca'+ p1[j].select('td')[1].select('a')[0].get('href') for j in range(len(p1))]
info['deadline']=['unknow' for j in range(len(p1))]
info['content']=range(len(info['urls']))
info=pd.DataFrame(info)
for i in range(len(info['urls'])):
page=urllib.urlopen(info['urls'][i]).read()
soup=BeautifulSoup(page,from_encoding='utf-8')
p2=soup.select('div.AdvisoryContainer')
if len(p2)>0:
info['content'][i]=p2[0].text
else:
info['content'][i]='NULL'
info['risk type']=range(len(info['url']))
info['risk rating']=range(len(info['url']))
info['title_cut']=range(len(info))
info['content_cut']=range(len(info))
for i in range(len(info)):
title_cut=list(jieba.cut(info['title'][i]))
title_list=[]
for word in title_cut:
if word in stopwords or word=='\n':
continue
else:
title_list.append(word)
content_cut=list(jieba.cut(info['content'][i]))
content_list=[]
for word in content_cut:
if word in stopwords or word=='\n':
continue
else:
content_list.append(word)
info['title_cut'][i]=title_list
info['content_cut'][i]=content_list
info['risk type'][i]=''
info['risk rating'][i]=''
##info=info.drop_duplicates()
print u'总共从【加拿大外交及国际贸易署】返回'+str(len(info))+u'条警示信息'
return info[['title','content','date','deadline','source','destination','risk type','risk rating','urls']]
if name == ‘main‘:
ss = spider()
info=ss.get_gcca()
info=info.sort_index(by='date',ascending=False)
##对文章title和content进行分词,并提取出包含在地名词典中的单词
for i in range(len(info)):
try:
cut1=jieba.cut(info['title'][i],cut_all=False)
except AttributeError:
info['title_cut'][i]=None
else:
cut1_list=[]
for word in cut1:
if word in stopwords or word=='\n':
continue
else:
cut1_list.append(word)
info['title_cut'][i]=cut1_list
try:
cut2=jieba.cut(info['content'][i],cut_all=False)
except AttributeError:
info['content_cut'][i]=None
else:
cut2_list=[]
for word in cut2:
if word in stopwords or word=='\n':
continue
else:
cut2_list.append(word)
info['content_cut'][i]=cut2_list
info['des1']=range(len(info))
info['des2']=range(len(info))
for i in range(len(info)):
list1=[]
list2=[]
for word in info['title_cut'][i]:
if word.lower() in dist and word!='\n':
list1.append(word)
info['des1'][i]=list1
for word in info['content_cut'][i]:
if word.lower() in dist and word!='\n':
list2.append(word)
info['des2'][i]=list2
#basic:title,content,date,deadline,source,destination,risk type,risk rating,url,title_cut
info.to_csv('c:/users/hzins/desktop/spider/new_gcca.csv',encoding='gb18030')
#打开本地结果如下:

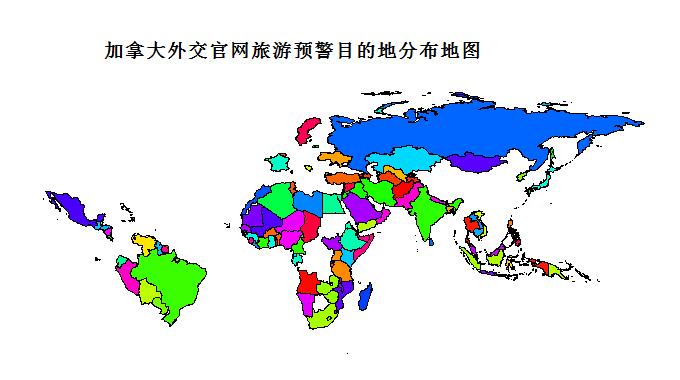
##下面利用R对整理后的地名进行可视化:
library(maps)
map(‘world’,region=c(‘turkey’,
+ ‘South Sudan’,
+ ‘Djibouti’,
+ ‘Eritrea’,
+ ‘Ghana’,
+ ‘Guatemala’,
+ ‘Guyana’,
+ ‘Iran’,
+ ‘Iraq’,
+ ‘Jordan’,
+ ‘Libya’,
+ ‘Madagascar’,
+ ‘Mozambique’,
…
+ ),col=rainbow(200),fill=T,mar = c(6.1, 6.1, par(“mar”)[3], 0.1))















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









