









一、集合类存放于 Java.util 包中,主要有 3 种:set(集)、list(列表包含 Queue)和 map(映射)。
1. Collection:Collection 是集合 List、Set、Queue 的最基本的接口。
2. Iterator:迭代器,可以通过迭代器遍历集合中的数据
3. Map:是映射表的基础接口
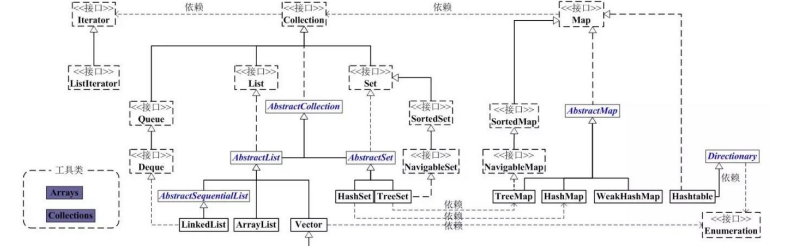
二、说说List,Set,Map三者的区别?
1、List(对付顺序的好帮手): List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
2、Set(注重独一无二的性质): 不允许重复的集合。不会有多个元素引用相同的对象。
Map(用Key来搜索的专家): 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
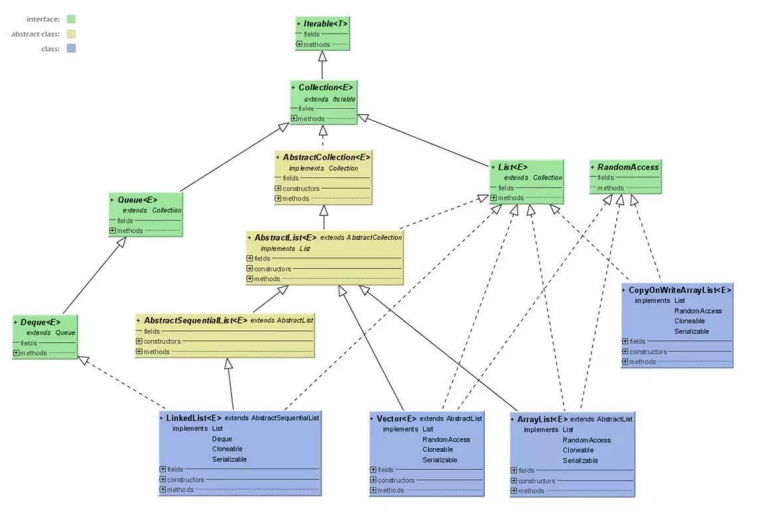
三、ArrayList和linkedList的区别
List—是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式,它继承Collection。
List有两个重要的实现类:ArrayList和LinkedList
ArrayList: 可以看作是能够自动增长容量的数组
ArrayList的toArray方法返回一个数组
ArrayList的asList方法返回一个列表
ArrayList底层的实现是Array, 数组扩容实现
LinkList是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于
ArrayList.当然,这些对比都是指数据量很大或者操作很频繁。
四:list的常用实现
Java 的 List 是非常常用的数据类型。List 是有序的 Collection。Java List 一共三个实现类:
分别是 ArrayList、Vector 和 LinkedList。
五、 HashMap和HashTable的区别
1、两者父类不同
HashMap是继承自AbstractMap类,而Hashtable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
2、对外提供的接口不同
Hashtable比HashMap多提供了elments() 和contains() 两个方法。 elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举。
contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。
3、对null的支持不同
Hashtable:key和value都不能为null。
HashMap:key可以为null,但是这样的key只能有一个,因为必须保证key的唯一性;可以有多个key值对应的value为null。
4、安全性不同
HashMap是线程不安全的,在多线程并发的环境下,可能会产生死锁等问题,因此需要开发人员自己处理多线程的安全问题。
Hashtable是线程安全的,它的每个方法上都有synchronized 关键字,因此可直接用于多线程中。虽然HashMap是线程不安全的,但是它的效率远远高于Hashtable,这样设计是合理的,因为大部分的使用场景都是单线程。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。
六、HashMap 中的 key 我们可以使用任何类作为 key 吗?
平时可能大家使用的最多的就是使用 String 作为 HashMap 的 key,但是现在我们想使用某个自定义类作为 HashMap 的 key,那就需要注意以下几点:
如果类重写了 equals 方法,它也应该重写 hashCode 方法。类的所有实例需要遵循与 equals 和 hashCode 相关的规则。如果一个类没有使用 equals,你不应该在 hashCode 中使用它。咱们自定义 key 类的最佳实践是使之为不可变的,这样,hashCode 值可以被缓存起来,拥有更好的性能。不可变的类也可以确保 hashCode 和 equals 在未来不会改变,这样就会解决与可变相关的问题了。
七、HashMap 的长度为什么是 2 的 N 次方呢? 为了能让 HashMap 存数据和取数据的效率高,尽可能地减少 hash 值的碰撞,也就是说尽量把数 据能均匀的分配,每个链表或者红黑树长度尽量相等。 我们首先可能会想到 % 取模的操作来实现。 下面是回答的重点哟: 取余(%)操作中如果除数是 2 的幂次,则等价于与其除数减一的与(&)操作(也就是说 hash % length == hash &(length - 1) 的前提是 length 是 2 的 n 次方)。并且,采用二进 制位操作 & ,相对于 % 能够提高运算效率。 这就是为什么 HashMap 的长度需要 2 的 N 次方了。
八、HashMap 与 ConcurrentHashMap 的异同 1. 都是 key-value 形式的存储数据; 2. HashMap 是线程不安全的,ConcurrentHashMap 是 JUC 下的线程安全的; 3. HashMap 底层数据结构是数组 + 链表(JDK 1.8 之前)。JDK 1.8 之后是数组 + 链表 + 红黑 树。当链表中元素个数达到 8 的时候,链表的查询速度不如红黑树快,链表会转为红黑树,红 黑树查询速度快; 4. HashMap 初始数组大小为 16(默认),当出现扩容的时候,以 0.75 * 数组大小的方式进行扩 容; 5. ConcurrentHashMap 在 JDK 1.8 之前是采用分段锁来现实的 Segment + HashEntry, Segment 数组大小默认是 16,2 的 n 次方;JDK 1.8 之后,采用 Node + CAS + Synchronized 来保证并发安全进行实现。
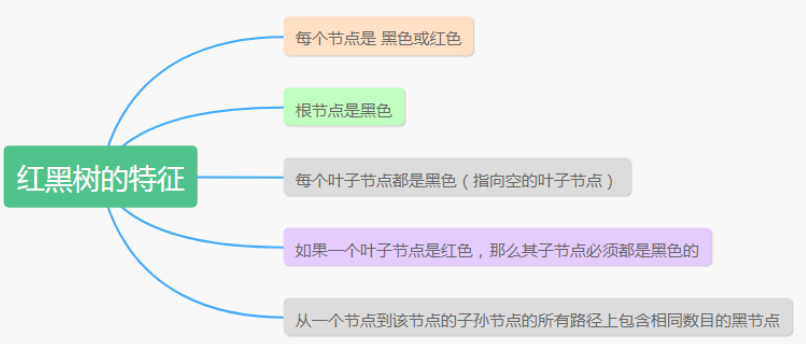
九、红黑树有哪几个特征?
十、hashSet和TreeSet树集
TreeSet 树集
TreeSet在java.util包中可用。
TreeSet是Set接口的实现类。
TreeSet的基础数据结构是Balanced Tree。
在TreeSet中,不保留“元素的插入顺序”,因为元素将按照某种升序排序插入TreeSet中,或者换句话说,“元素的插入顺序”不需要与“检索”相同元素的顺序”。
在TreeSet中,对象仅作为值表示为一组单个元素,作为单个实体。
在TreeSet中,“不允许使用重复的元素”,这意味着无法在TreeSet中插入重复的元素。
在TreeSet中,对于非空集,“不可能插入空”。
在TreeSet中,将空Set设置为第一个元素“可以插入空值”,如果在插入第一个元素后插入null,则不可能或无效。
在TreeSet中,不允许使用“异构对象”,如果强行插入,则会得到异常“ ClassCastException”。
HashSet 哈希集
HashSet在java.util包中可用。
HashSet是Set接口的实现类。
HashSet是LinkedHashSet的父类。
TreeSet的基础数据结构是Hashtable。
在HashSet中,“元素的插入顺序”未保留,或者换句话说,“元素的插入顺序”不需要与“元素的检索顺序”相同。
在HashSet中,对象仅作为值表示为一组单个元素,作为单个实体。
在HashSet中,“不允许使用重复的元素”,这意味着无法在HashSet中插入重复的元素。
在HashSet中,对于非空集和空集,“可以插入null”。
在HashSet中,允许“异构对象”,如果将其强行插入,则不会出现任何异常。
















 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









