







一、DDL操作
1、修改表
1、1增加分区
--一次添加一个分区
alter table tablename add partition (dt='20000202') location '要填在的表在hafs上的实际路径';
--一次添加多个分区
alter table tabelname add
partition (year='2019',month='09',day='18') location '表的路径/year=2019/month=09/day=18'
partition (yaer='2018',month='09',day='17') location '标的路径/yaer=2018/month=09/day=17';
1、2删除分区
alter table tablename drop if exists partition (guojia='china');2、显示命令
-- 查看分区
show partition tablename;
-- 查看表信息
desc extended tablename;
-- 查看表信息(格式化美观)
desc formatted tablename;
-- 查看数据库相关信息
describe database databasename;
二、DML操作
1、数据加载的三种方式
1)hdfs dfs -put
2) load data local inpath 'filepath'
3) insert + select
Load
-- 语法格式
load data [local] inpath 'filepath' [overwrite] into table tablename [partition(formatted )];
1、local
如果指定了local 那么文件的路径就是在本地的文件路径
如果没有指定local 那么filepath将会是hdfs中的路径
2、overwrite
如果添加 那么将会把目标表中的数据删除
如果不添加 那么数据将会在目标表的后面追加数据
insert
-- hive中国insert主要是和select一起使用的
insert overwrite table tablename select * from tablename;
-- 可以将查询出来的数据添加到原表中 这就相当于自我复制了一分数据
from tablename
insert overwrite table tablename1 [partition (...)]
select语句
insert overwrite table tablename2 [partition (....)]
select语句
-- 动态分区插入
select
-- 基本的select操作
-- 语法结构
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
JOIN table_other ON expr
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]
1、order by会对全局的数据进行排序
2、sort by 其在数据进入reduce前完成排序
3、distribute by(字段) 根据指定的字段将数据分发到不同的分区,分发算法是hash散列
4、cluster(字段) = 2 + 3
-- 如果distribute 和sort的字段相同 此时就相当于cluster by = distribute by + sort by
2、hive join
-- inner join 内连接 两张表都满足的数据
-- left join 左连接 以左表为主表 主表的数据都显示
-- left semi join 显示左表的数据部分
-- join 发生在where句子之前
三、hive的参数配置
1、hive shell 命令行
因为在hive中输入很多命令的时候是很不方便的 这时就要针对这一方面进行一个补充
输入$HIVE_HOME/bin/hive -H 或者-help来查看命令
1、 -i 初始化HQL文件
2、 -e 从命令行来执行指定的HQL
3、 -f 执行HQL脚本 把相应的脚本程序上传到本地
4、 -v 输出执行的HQL语句到控制台
eg:
$HIVE_HOME/bin/hive -e 'select * from tab1 a'
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
$HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql
$HIVE_HOME/bin/hive -i /home/my/hive-init.sql
四、函数入门
1、条件函数
-- if函数
语法:if(bolean testcondition, T valuetrue, T value);
当条件testCondition为true时 返回valuetrue,否则返回value
-- 非空查找函数 coalesce
说明:返回参数中的第一个非空值
eg:hive> select COALESCE(null,'100','50′) from dual;
-- 条件判断函数
语法:case a when b then c [when d then e]* [else f] end;
2、字符串函数
-- 字符串长度函数:length
-- 反转函数:reverse
-- 连接函数:concat
-- 带分隔符连接函数:concat——ws
-- 字符串截取函数: substr
-- 转大写函数:upper
-- 转小写函数:lower
-- 去空格函数:trim
-- 左边去空格函数:ltrim
-- 右边去空格函数:rtrim
-- 正则表达式替换函数:regexp replace
-- 正则表达式解析函数:regexp extract
-- URL解析函数:parse url
-- json解析函数:get json object
3、Hive自定义函数
当hive提供的内置函数无法满足业务需求的时候就要使用自定义函数
3.1自定函数的分类
1)UDF( User-Defined-Function) 普通函数 一进一出
2)UDAF( User-Defined Aggregation Function) 聚合函数,多进一出
3)UDTF( User-Defined Table-Generating Functions) 表生成函数 一进多出
3.2 UDF开发实例
1)新建maven项目
2)添加 hive-exec-1.2.1.jar 和 hadoop-common-2.7.4.jar 依赖
3)写一个java类 继承UDF 并重载 evaluate 方法
4)打成 jar 包上传到服务器
5)将jar包添加到hive的classpath hive>add JAR /home/hadoop/udf.jar;
6)创建临时函数与开发好的java class 关联
| create temporary function 函数名 as 'cn.itcast.bigdata.udf.类名'; |
7)在hql中使用自定义的函数 select 上面定义的函数名(name),age from 表名;
4、Hive特殊分隔符处理
hive 读取数据的机制
首先用 InputFormat<默认是: org.apache.hadoop.mapred.TextInputFormat >的一
个具体实现类读入文件数据,返回一条一条的记录(可以是行,或者是你逻辑中的“行”)
然后利用 SerDe<默认: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe>
的一个具体实现类,对上面返回的一条一条的记录进行字段切割
eg:
01||zhangsan
02||lisi
可用使用 RegexSerDe 通过正则表达式来抽取字段
drop table t_bi_reg;
create table t_bi_reg(id string,name string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
'input.regex'='(.*)\\|\\|(.*)',
'output.format.string'='%1$s %2$s'
)
stored as textfile;
hive>load data local inpath '/root/hivedata/bi.dat' into table t_bi_reg;
hive>select * from t_bi_reg;
其中:
input.regex:输入的正则表达式
表示 || 左右两边任意字符被抽取为一个字段
output.format.string:输出的正则表达式
%1$s %2$s 则分别表示表中的第一个字段、第二个地段
注意事项:
a、使用 RegexSerDe 类时,所有的字段必须为 string
b、 input.regex 里面,以一个匹配组,表示一个字段5、函数高阶特性
5.1UDTF函数- explode
UDTF 函数,用户自定义表生成函数。可以将一行转成一行多列,也可以将一行转成多行多列,使用频率较高。 除了用户可以自定义这样的函数之外, hive也自带了很多 UDTF 函数, 便于在各种场合针对数据进行解析分析。
explode 函数就是 hive 内置的一个 UDTF 函数。 其可以将一个 array 或者 map类型的字段展开,其中 explode(array)使得结果中将 array 列表里的每个元素生成一行; explode(map)使得结果中将 map 里的每一对元素作为一行, key 为一列,value 为一列。
一般情况下,直接使用 explode 即可,也可以根据需要结合 lateral view。
使用:
-- 准备数据:
001,allen,usa|china|japan,1|3|7
002,kobe,usa|england|japan,2|3|5
-- 创建表和导入数据
create table test_message (id int,name string,location array<string>,city array<string>) row format delimited fields terminated by "," collection items terminated by "|";
load data local inpath "数据文件的路径" into table test_message;
-- 查看元素
select explode(location) from test_message;
注意:
select name,explode(location) from test_message; 报错
当使用UDTF函数的时候,hive只允许对拆分字段进行访问的。
结果:

5.2 lateral view函数(列转行)
lateral view为侧视图 ,意义是为了配合UDTF来使用,把莫一行数据拆分成多行数据,不加lateral view的UDTF只能提取单个字段拆分,并不能塞回原来数据表中,加上lateral view就可以将拆分的单个字段数据与原始表数据关联上。
注意:在使用lateral view的时候需要制定视图别名和生成的新列别名
-- 如果不加lateral view 就会只是提取单个字段的数据对其进行拆分
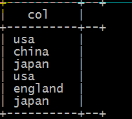
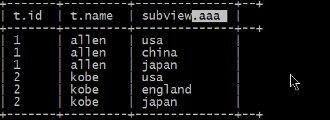
-- 如果加入lateral view的时候就可以将拆分的单个字段的数据和源数据进行关联
eg:
select * from 真实表名 lateral view explode(loction) 虚拟表的别名;
select t.id,t.name,subview.aaa from test_message t lateral view explode(location) subview as aaa;结果:
5.3 行转列 多行转单列
需要使用的hive内置函数
concat_ws(参数1,参数2,参数3.。。。。)用于进行字符创的拼接 拼接的时候每个参数的中间使用参数1的内容进行分割
collect_set(col3)
他的主要作用就是将某字段的值进行去重汇总,产生array类型的字段,如果不想去重可用 collect_list()
数据:
a,b,1
a,b,2
a,b,3
c,d,4
c,d,5
c,d,6
创建表:
create table row2col_1(col1 string,col2 string,col3 int) row format delimited fileds terminated by ',';
加载数据:
load data local inpath '文件路径' into table row2col_1;
select collect_set(col3) from row2col_1;
--将col3的所有数据放到一个集合中(去重)
[1,2,3,4,5,6]
select collect_set(col3) from row2col_1 group by col1,col2;
--根据col1,col2进行分组,只有第一列和第二列都相同,认为是同一组
[1,2,3]
[4,5,6]
select col1,col2, collect_set(col3) from row2col_1 group by col1,col2;
--行转列
a b [1,2,3]
c d [4,5,6]
select col1,col2, concat_ws(',',collect_set(cast(col3 as string))) as col3 from row2col_1 group by col1,col2;
a b 1,2,3
c d 4,5,6
cast(col3 as string)
collect_set(字符串类型的col3)
concat_ws(',',['col3'])5.4 reflect函数
reflect函数可以支持在sql中调用java中的自带函数,秒杀一切udf函数
5.4.1 使用java.lang.math当中的max求两列中最大值
-- 创建表
create table test_udf(col1 int,col2 int) row format delimited fields terminated by ',';
-- 准备数据
test——udf.txt
1,2
4,3
6,4
7,5
5,6
--加载数据
load data local inpath 'test——udf.txt在本地的路径' into table test_udf;
-- 求最大值
select reflect("java.lang.Math","max",col1,col2) from test_udf;
--1.使用java中的哪个类
--2.类中的方法
--3.方法中的参数5.4.2 不同记录执行不同的 java 内置函数
-- 创建表
create table test_udf2(class_name string,method_name string,col1 int,col2 int) row format delimited fields terminted by ',';
--准备数据 test_udf2.txt
java.lang.Math,min,1,2
java.lang.Math,max,2,3
--加载数据
load data local inpath 'test_udf2.txt文件所在的路径' into table test_ud2;
-- 执行查询
select reflect(class_name,method_name,col1,col2) from test_udf2;
6 、json 数据解析 (原声的js对象)
json数据解析总的来说有两方式来做;
1、将json数据已字符串的方式整个入hive表 ,然后通过使用udf 函数解析已经导入到hive中的数据,比如使用 LATERAL VIEW json_tuple 的方法,获取所需要的列名。
get_json_object(string json_string,string path)
json_tuple(string json_string,'属性1','属性2')
-- 数据
{
"id":1701439105,
"ids":[2154137571,3889177061,1496915057,1663973284],
"total_number":493
}
-- 创建表
create table if not exists tmp_json_test(json string) stored as testfile;
--加载数据
load data local inpath '数据文件所在的路径' overwrite into table tmp_json_test;
-- 查询数据
select get_json_object(t.json.'$.id'),get_json_object(t.json,'$.total_number') from tmp_json_test t;
或者
select json_tuple(json,'id','ids','total_number') from tmp_json_test; // 方便使用2、在导入之前将json拆成各个字段,导入hive表的数据已经解析过的,这将需要第三方的serde;
http:www.congiu.net/hive-json-serde/
add jar /root/hivedata/json-serde-1.3.7-jar-with-dependencies.jar;
create table tmp_json_array(id string,ids array<string>,total_number int)
row format SERDE 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile;
load data local inpath '/root/hivedata/json_test.txt' overwrite into table tmp_json_array;
注意:json表的创建依赖jar需要调整设置
<https://blog.csdn.net/xingyue0422/article/details/86479990>
使用explode函数解析json数组
SELECT explode(split(regexp_replace(regexp_replace('[{"website":"www.baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;'));
'[{"website":"www.baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]'
1.将字符串变成数组
regexp_replace('[{"website":"www.baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}]', '\\]','')
regexp_replace('字符串','字符串中包含的内容','替换的内容')
'[{"website":"www.baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}'
regexp_replace('{"website":"www.baidu.com","name":"百度"},{"website":"google.com","name":"谷歌"}','\\}\\,\\{','\\}\\;\\{')
{"website":"www.baidu.com","name":"百度"};{"website":"google.com","name":"谷歌"}
split('{"website":"www.baidu.com","name":"百度"};{"website":"google.com","name":"谷歌"}',';');
'[{"website":"www.baidu.com","name":"百度"}','{"website":"www.baidu.com","name":"百度"}'















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









