







1、什么是注意力机制(Attention Mechanism)
注意力Attention,人类在观察周围环境时,总会优先注意到一些部分来获取自己需要的信息,这些部分就代表了周围环境的某种描述。而注意力机制通过学习不同局部的重要性,再结合起来。对Attention常见的有三种理解:
(1)从数学公式和代码实现上attention可以理解为加权求和;
(2)从形式上attention可以理解为键值查询;
(3)从物理意义上attention可以理解为相似性度量。
2、Sequence to Sequence
Attention Mechanism 的大量使用源于机器翻译。机器翻译本质上是解决一个Sequence to Sequence问题。

如上图所示,Sequence-to-Sequence一般有5中形式,区别在于输入和输出序列的长度,以及是否同步产出。具体到每一个基本的模块,又能用不同的网络结构实现,包括CNN、RNN。但是它们的实现基本上离不开一个固定的结构:Encoder-Decoder结构。
Encoder-Decoder结构作为Sequence-to-Sequence任务的最佳拍档,常见于各种深度学习任务,从简单的***时序预测分类***,到***GAN***里都有它的影子。之所以强调这个结构,就是因为Attention解决了它的“分心问题”。

上图是一个通用的Encoder-Decoder结构,从图上看,Encoder负责从输入序列X中学习某种表达C,然后Decoder参考该表达C生成每一个输出Yi。就是说,如果你想要机器自己生成一张动物的图片,你就给它输入足够多的动物图片让它学习。但这种原始的做法是不太合理的,因为在生成每一个Yi时,Decoder参照的是同一个表征C,它没有抓住重点。在机器翻译中,输出序列的每一个局部,往往只与输入序列的某个或几个局部有关。
这里举一个例子,英译中任务: “Billy eats a banana.”
显然答案是:“比利吃香蕉。”
在Sequence-to-Sequence里我们要解决的是这样一个问题:
(Billy, eats, a, banana)→ (比利, 吃, 香蕉)
按照Encoder-Decoder的原始做法,我们为三个中文单词分别计算C:
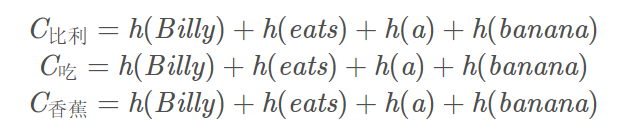
这并不合理,为什么翻译输出“比利”这个词要关注整个原句子呢?只关注或者主要关注“Billy”这个词不是更好吗?同理,输出“吃”这个词时应该更多地关注“eat”,所以下面这种计算C方式要更加合理一些。
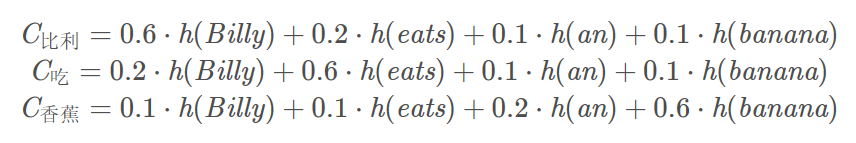
下图是一个简单的Encoder-Decoder,它的Encoder和Decoder都是RNN结构,输入序列表征CC CC有多种计算方法,包括取最后一个时刻的Encoder隐层输出、取所有时刻Encoder隐层输出的均值或加权平均、取最大值等等。它实现了对不同的局部采取不同的权重,然而它对于任意输出都采用同一套权重,本质上没有做出任何改进。

总结一下,我们的要求有两个:
(1)对于输入序列不同局部,赋予不同的权重;
(2)对于不同的输出序列局部,赋予不通的赋权规划方案。
3、Attention Mechanism
注意力机制一定程度上解决了上述问题。对于怎么划分权重,attention给出的答案是:让输出序列决定。


















 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









