







本章节的Python代码是在上一章深度学习(一)autoencoder的Python实现(2)的基础上修改实现的,所以要先阅读上一章节。
sparse autoencoder的思想大家可以参考文献sparse autoencoder。这里我简单说明一下,我们可以把sparse理解成一个特征稀疏的过程。我们在看一段话在讲什么的时候,并不需要每一句话或者每一个词,因为只有几句关键的话,关键的词才真正地反映该段话的主题,因而我们可以过滤掉那些废话,无用的词。我们的深度学习其实就相当于模拟我们的大脑,他也需要过滤掉一些无用的信息,这个时候引入sparse autoencoder对特征进行稀疏。
sparse autoencoder的损失函数为
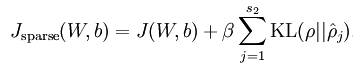
其中
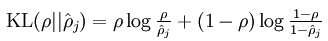
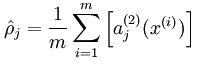
式子
a2j
表示第二层的第j个节点
原来非最后一层的权值更新函数从
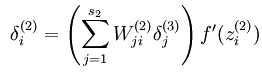
变成
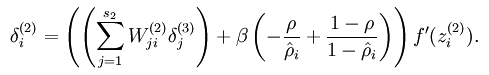
简单介绍后,我们写入Python代码,主要贴出的是修改的代码,并对修改进行必要的说明
bean.py文件中的nn类
class nn():
def __init__(self,nodes):
self.layers = len(nodes)
self.nodes = nodes;
# 学习率
self.u = 1.0;
# 权值
self.W = list();
# 偏差值
self.B = list()
# 设置P(增加)
self.P = list()
# 层值
self.values = list();
# 误差
self.error = 0;
# 损失
self.loss = 0;
# 设置sparse参数(增加)
self.sparse = 0.2
# 设置beta(增加)
self.beta = 2.0
for i in range(self.layers-1):
# 权值初始化,权重范围-0.5~0.5
self.W.append(np.random.random((self.nodes[i],self.nodes[i+1])) - 0.5)
# B值初始化
self.B.append(0)
# P值初始化(增加)
self.P.append(0)
for j in range(self.layers):
# values值初始化
self.values.append(0)util.py文件中的nnff和nnbp函数
#前馈函数
def nnff(nn,x,y):
layers = nn.layers
numbers = x.shape[0]
# 赋予初值
nn.values[0] = x
for i in range(1,layers):
nn.values[i] = sigmod(np.dot(nn.values[i-1],nn.W[i-1])+nn.B[i-1])
# 初始化P值(增加)
for j in range(1,layers-1):
nn.P[j] = nn.values[j].sum(axis = 0)/(nn.values[j].shape[0])
# 最后一层与实际的误差
nn.error = y - nn.values[layers-1]
# 计算KL项(增加)
sparsity = nn.sparse*np.log(nn.sparse/nn.P[layers-2])
+(1-nn.sparse)*np.log((1-nn.sparse)/(1-nn.P[layers-2]))
# 修改loss
nn.loss = 1.0/2.0*(nn.error**2).sum()/numbers+nn.B*sparsity.sum()
return nn
#BP函数
def nnbp(nn):
layers = nn.layers;
#初始化delta
deltas = list();
for i in range(layers):
deltas.append(0)
#最后一层的delta为
deltas[layers-1] = -nn.error*nn.values[layers-1]*(1-nn.values[layers-1])
#其他层的delta为
for j in range(1,layers-1)[::-1]:#倒过来
#求deltas的同时,要求spare这个惩罚项,因为在Python中,如果是向量,都默认为N*.的矩阵,所以不能用dot,只能用点乘
#还有我们给他重复了样本的数量次,(增加)
pj = np.ones([nn.values[j].shape[0],1])*nn.P[j]
sparsity = nn.beta*(-nn.sparse/pj+(1-nn.sparse)/(1-pj))
#deltas进行了修改
deltas[j] = (np.dot(deltas[j+1],nn.W[j].T)+sparsity)*nn.values[j]*(1-nn.values[j])
#更新W值
for k in range(layers-1):
nn.W[k] -= nn.u*np.dot(nn.values[k].T,deltas[k+1])/(deltas[k+1].shape[0])
nn.B[k] -= nn.u*deltas[k+1]/(deltas[k+1].shape[0])
return nn与上一篇章一样的输入x输出y

运行结果为

基本符合















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









