







Authors: Jia-Ren Chang, Yong-Sheng Chen
Link: https://arxiv.org/abs/1803.08669
Years: 2018
Credit

Novelty and Question set up
本文提出之时,基于深度学习的立体匹配主流方式仍是patch-based孪生结构,这种方式缺乏上下文信息的获取能力,为了解决这个问题,作者提出了PSMnet,主要通过SPP和3D CNN模块来进行上下文信息的学习。其中SPP(空间金字塔池化)结构利用全局多尺度信息来捕获上下文,而3DCNN则是利用多个hourglass结构来实现更优化的cost volume正则。
本文主要贡献:
- 提出一个端对端框架直接获得视差图,并且不需要任何后处理
- 提出利用SPP来捕获图像上下文信息
- 提出利用3D Conv的stacked hourglass来进一步获得上下文线索以实现更优的cost volume正则
Solutions and Details
-
总体结构
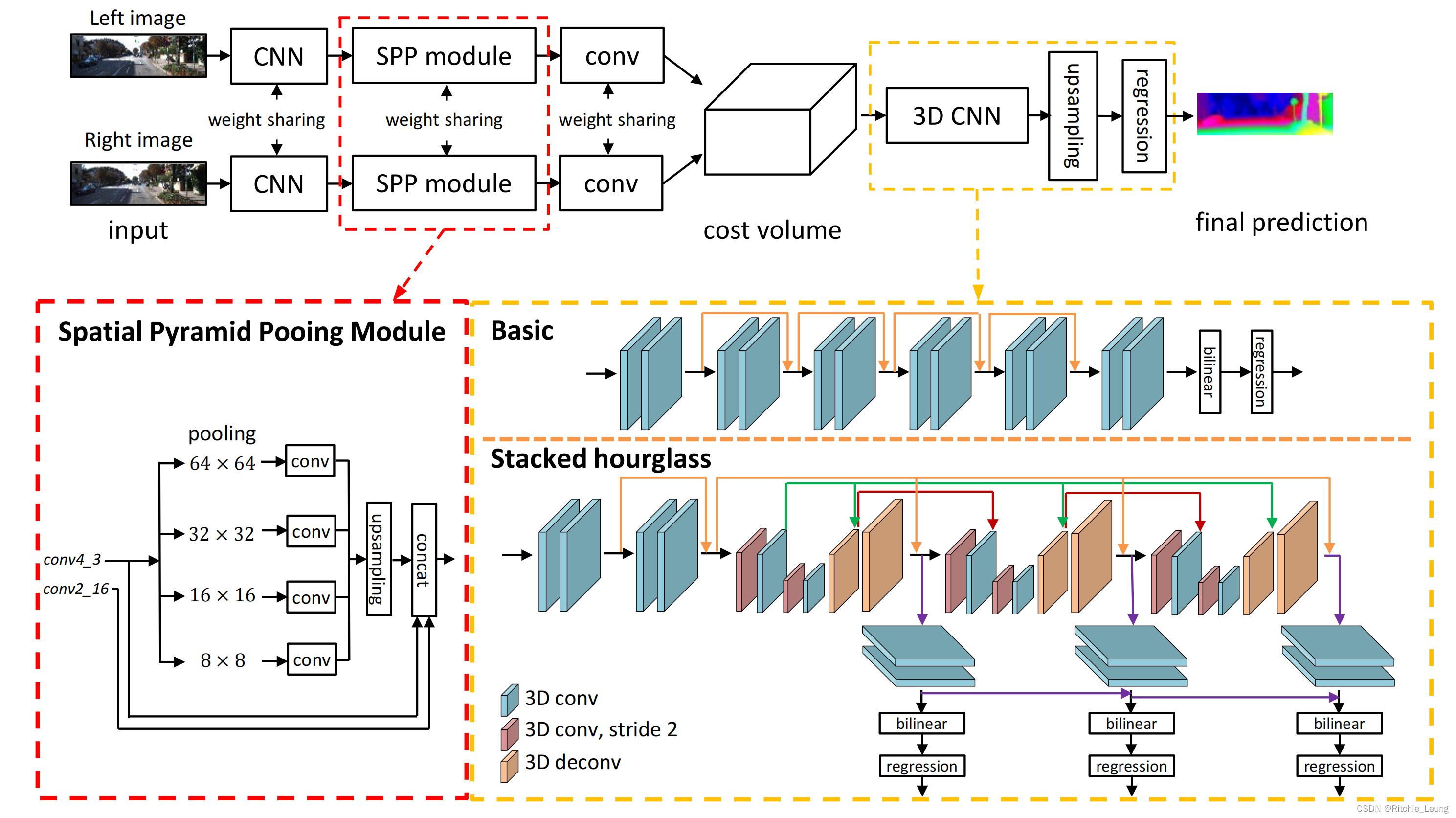
整体网络结构分4个stage:
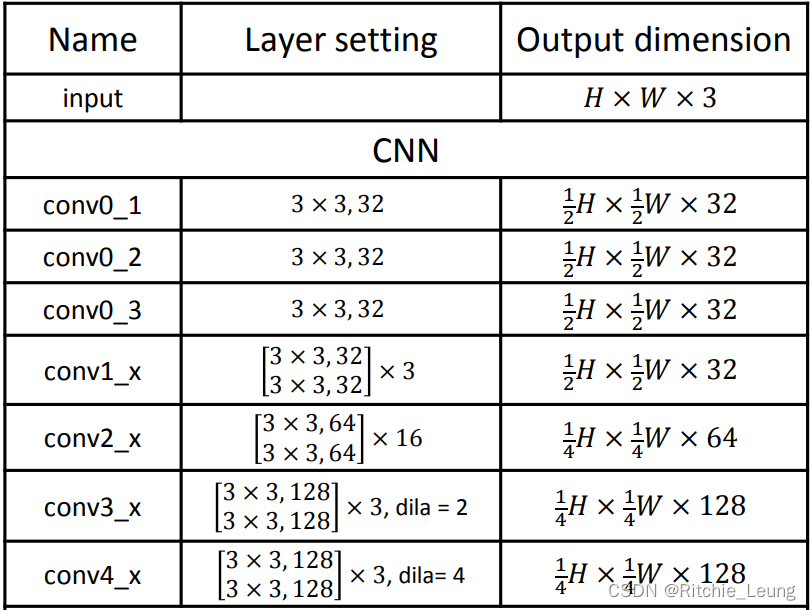
- CNN:用于提取图像特征,PSMNet在最末几个block采用了dilation来扩大感受野
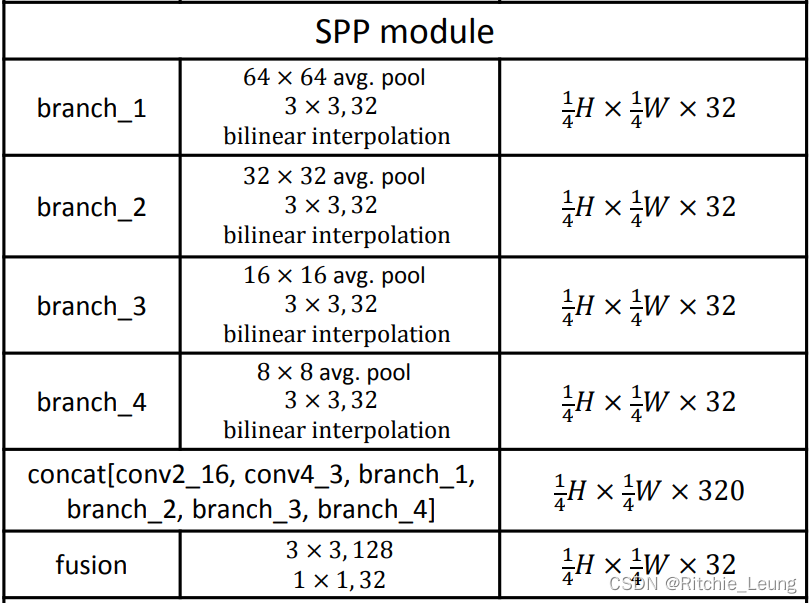
- SPP:用于聚合上下文信息
- Cost Volume:构建左右图特征的匹配代价,采用特征concatenate策略

- Regularization:采用3个hourglass对代价体进行正则化,每个hourglass block都会输出一个预测视差图,训练阶段会对三个视差图进行加权平均,而推理时只采用最后一层输出的视差图

- CNN:用于提取图像特征,PSMNet在最末几个block采用了dilation来扩大感受野
-
视差回归
沿用GC-Net的soft argmin策略,对所有视差level进行一个可差分的回归估计
d ^ = ∑ d = 0 D m a x d × σ ( − c d ) \hat{d} = \sum_{d=0}^{D_{max}}d\times{\sigma{(-c_{d}})}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









