







 本文详细介绍使用Scrapy框架创建爬虫的过程,包括环境搭建、关键文件配置等步骤,并通过实例演示如何抓取虎扑NBA网站上的特定数据。
本文详细介绍使用Scrapy框架创建爬虫的过程,包括环境搭建、关键文件配置等步骤,并通过实例演示如何抓取虎扑NBA网站上的特定数据。
下图是2018年5月25日火箭和勇士西决G5时,火箭赢下天王山之战,虎扑NBA的首页。
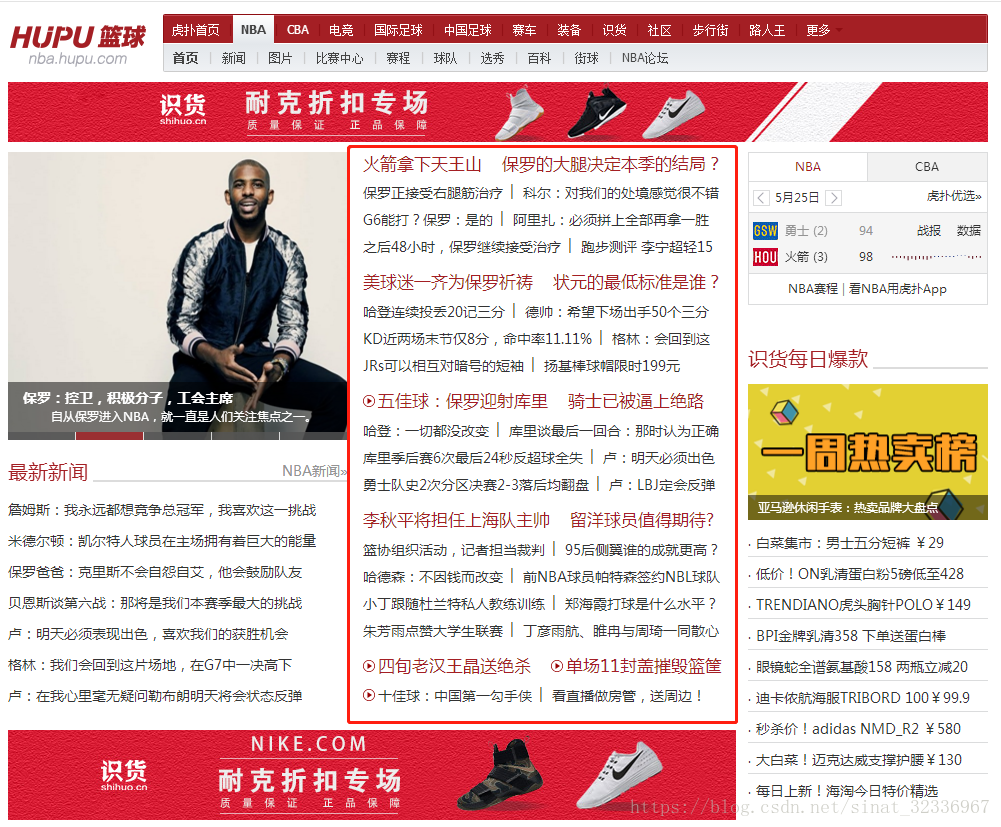
我这次做的爬虫项目的目的就是:爬取图片中红色边框里的文字,然后txt文本的方式保存到本地。
接下来我介绍一下我完成这个工作的全过程。
1.介绍怎么完成这个工作之前,我必须得介绍一下Scrapy框架的构成。
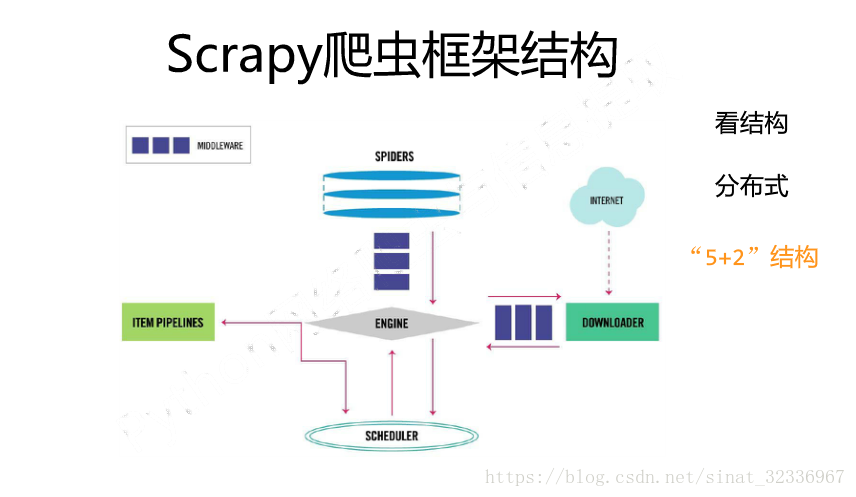
Scrapy框架总的来说是由7个部分组成,即5+2的结构。
其中5是指:SPIDERS、ENGINE、SCHEDULER、DOWNLOADER、ITEM_PIPELINES.
2是指:Downloader Middlewares和Spider Middlewares.
其结构图如下:
2.其实我们并不要了解它是怎么构成的。我们只需要掌握创建爬虫最主要的方法是什么就行了。
不同于一般的框架,比如Java中的SSM,SSH框架。它们都是在IDE中配置和使用的。Scrapy框架的使用一般是在CMD中,一般是在.py文件的编辑器中使用的。我用的文本编辑器是Sublime Text。
3.现在正式开始讲怎么利用scrapy的命令,创建一个爬虫程序的框架。
首先,我们创建一个工程,我的工程名叫LOLMovie,在一个工程里可以有很多个爬虫程序。
创建一个工程的命令为:scrapy startproject LOLMovie(请在一个自己熟悉的文件夹下创建,防止找不到)
其次,我们cd LOLMovie,进入工程,创建一个爬虫程序,我的名字叫heifei01MovieSpider.
创建一个爬虫的命令为:scrapy genspider heifei01MovieSpider nba.hupu.com.
然后你就能看见在文件夹下的结构如下:(我是在D:\pycode下创建工程 的)
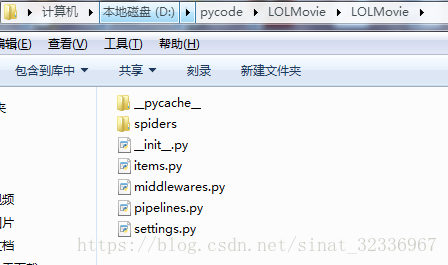
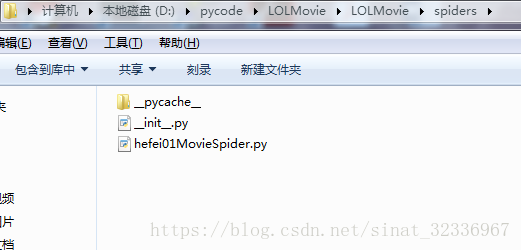
可能比较乱,大家将就着看一下。简单说一下这些文件的关系。我们需要关系的文件只有四个。就是items.py、settings.py、pipelines.py、hefei01MovieSpider.py文件。
其中items.py决定爬取哪些项目,settings.py决定由谁去爬,hefei01MovieSpider.py决定怎么爬,pipelines.py决定爬取后的内容怎么处理。
我们先配置items.py文件,如下图所示。
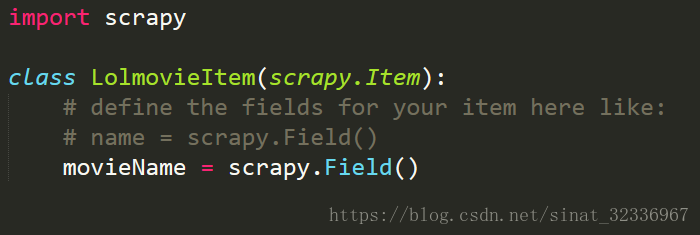
我们需要爬取名字,则命名一个变量movieName。如果需要爬取url连接,则可再命名一个urlName = scrapy.Field().这是配置文件给出的格式(在上面的注释部分)。
再配置hefei01MovieSpider.py文件,如下图所示。
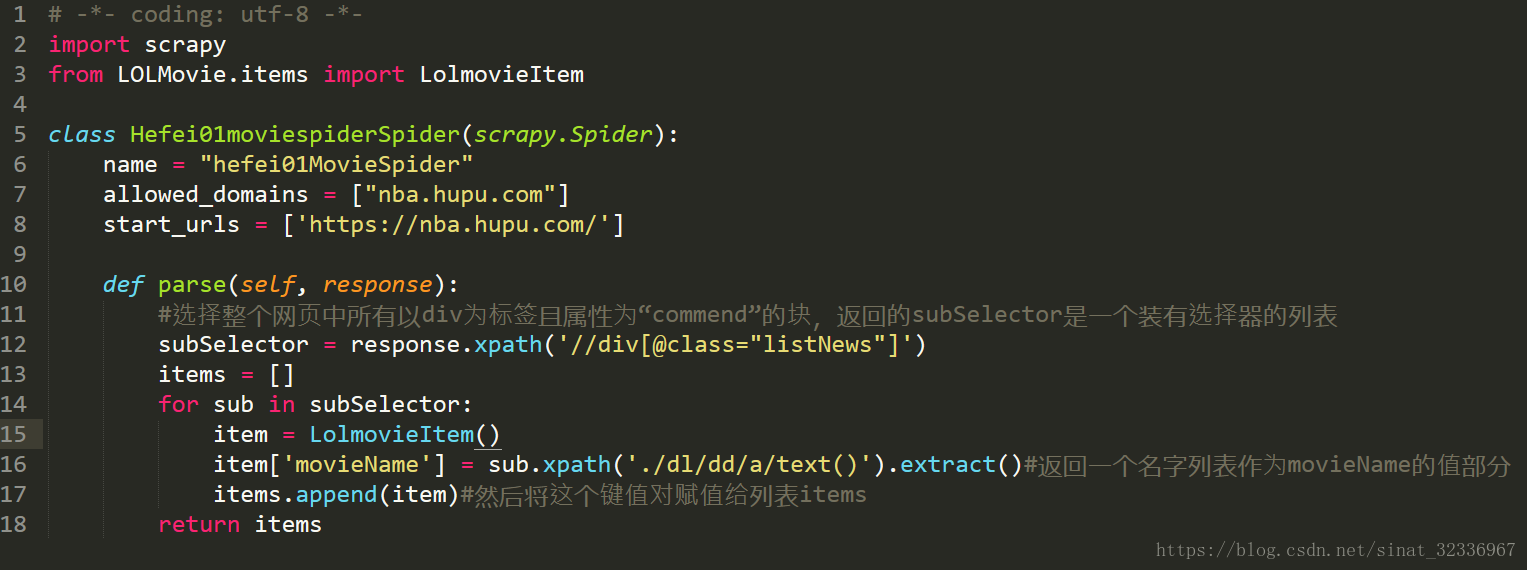
我这里用的是xpath选择器,也可以用其他的选择器。
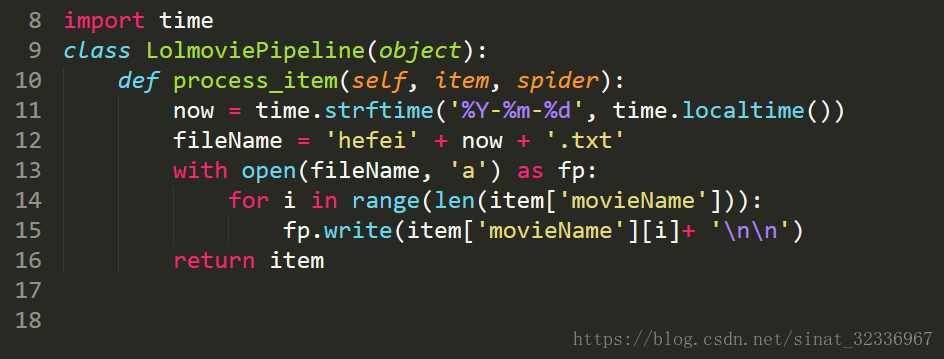
接下来配置pipelines.py文件,如下图所示。
最后我们配置settings.py文件。只用在原来的文件中找到一行如下所示的注释。去掉注释即可。

当有多个项目时,后面的数字越小,优先级越高。我们因为只有这一个项目,所以数字设成多少都可以。
最后我们回到命令行,在工程目录下输入,scrapy crawl hefei01MovieSpider,运行即可出结果。如下图所示。
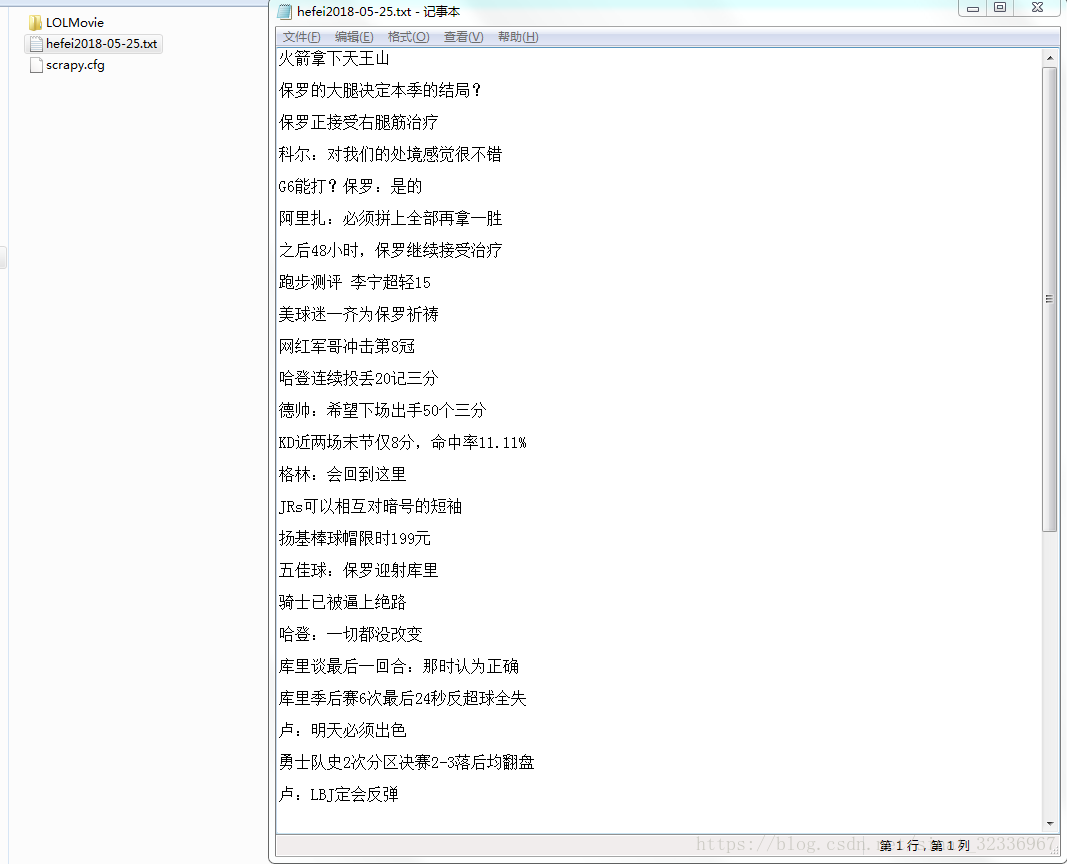
至此,我们的爬虫项目结束。
其实也可以在命令行中对中间的结果进行调试,我们输入scrapy shell http://nba.hupu.com
然后输入:subSelector = response.xpath('//div[@class="listNews"]')
再输入:print(subSelector)(此处是python3的输出格式),看看subSelector是什么
在输入:print(subSelector[0].xpath('./dl/dd/a/text()').extract()),看看爬出来的东西是什么。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









