






参考资料:
某师傅的滴水逆向学习笔记:https://gh0st.cn/Binary-Learning/
序言:为什么先讲汇编?
汇编是面向机器的程序设计语言,是二进制指令的文本形式,与指令是一一对应的关系。比如,加法指令00000011写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行,是最底层的低级语言。所以学习汇编语言能更好的帮助我们了解程序的底层运行逻辑,当一开始就从汇编的角度去理解程序一切都会变得不同。
根据网络上的材料,笔者决定从x86指令集开始。
先来点基础概念
寄存器
CPU 本身只负责运算,不负责储存数据。数据一般都放在内存里,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。
但是,CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。
寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
寄存器的种类
这里我们先讲通用寄存器,其他寄存器会在后面讲到。通用寄存器表示其通用性,可以往里面存储任意数据和值。
| 通用寄存器 | ||
| 32位 | 16位 | 8位 |
| EAX | AX | AL、AH |
| ECX | CX | CL、CH |
| EDX | DX | DL、DH |
| EBX | BX | BL、BH |
| ESP | SP | |
| EBP | BP | |
| ESI | SI | |
| EDI | DI | |
上面这8个寄存器除了ESP 必须用于堆栈操作,其他的都是通用的,当然也有一些习惯上的用法我们后面会讲。
我们常常看到 32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是4个字节。
由于8086前的寄存器都是8位的,为了兼容前代CPU,8086的4个通用寄存器都可分为两个独立使用的8位寄存器:AH、AL;BH、BL...
数据宽度
我们熟知的数字,也就是数学上的数字,理论来说只要你能写、纸张足够多,那么你是可以写任意大小数字的;
但在计算机中,因为受到硬件的制约,数据是有长度限制的,我们一般称之为「数据宽度」,超出最多宽度的数据会被丢弃掉。
数据宽度也有自己的单位:
| 名称 | 大小 |
| 位(BIT) | █(1位) |
| 字节(Byte) | █|█|█|█|█|█|█|█(8位) |
| 字(Word) | █|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█(16位、2个字节) |
| 双字(Doubleword) | █|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█|█(32位、2个字、4个字节) |
当我们存储数据的时候,需要知道自己存储的数据的数据宽度是什么,假设你要存储一个1,要存入字节中,那么以二进制的表示即为:0000 0001
字节(Byte)的存储范围使用十六进制表示则为:0 - 0xFF,以此类推,字(Word)的存储范围:0 - 0xFFFF,双字(Doubleword)的存储范围:0 - 0xFFFFFFFF。
内存
内存和寄存器都是存储数据的,但由于CPU中的寄存器有限(造价比较昂贵),所以我们可以给每一个寄存器取名,但内存不一样,内存太大了无法取名字,所以我们只能使用编号。当我们想向内存中读取数据时,就需要使用到这个编号,这个编号我们称之为内存地址(32位),每一个内存地址(编号)都能存储一个字节(8位)。内存地址是32位的(32位表示32个0和 1,但我们一般使用16进制去表示,例如:0x00000000),程序独立存储的内存空间范围为:0 - 0xFFFFFFFF,能存储的位数就是(0xFFFFFFFF+1)*8,加一是因为0也算一位,乘八是因为每块内存可以存储一个字节(8位),转为十进制就是:34359738368 / 8 / 1024 / 1024 / 1024 = 4G(换算:1Byte = 8Bit, 1KB = 1024Byte, 1MB = 1024KB, 1GB = 1024MB),这也就是「每个应用程序都会有自己的独立4GB内存空间」的原因。
存储模式(大、小端)
要在计算机中存储数据,需要遵循其的存储模式,存储模式分为两种:大、小端。
大端模式:数据高位在低位地址中,数据低位在高位地址中;
小端模式:数据低位在低位地址中,数据高位在高位地址中。
如下图中所示,内存地址从小到大;我们知道每一个内存地址可以存储8位,也就是一个字节,当我们使用MOV指令写入数据到内存中时指定宽度为BYTE存储数据会存储在一个内存地址中。下一节我们将带大家一起操作今天我们学到的寄存器和内存。
工欲善其事必先利其器
OllyDebug基本操作
因为我们学习汇编的目的不是为了开发,所以不需要搞一套DOSBOX或者VisualStudio的环境那么麻烦(如果有需求可以抽时间写一下VisualStudio的汇编环境配置)。我们直接请上今天的主角——OllyDebug(下文简称OD)。目前比较流行的版本是吾爱破解加强过的版本,同类的工具还有ImmunityDebug和DTDebug,使用上也差不多。

OD 中各个窗口的功能如上图。简单解释一下各个窗口的功能:
反汇编窗口:显示被调试程序的反汇编代码,标题栏上的地址、HEX 数据、反汇编、注释可以通过在窗口中右击出现的菜单 界面选项->隐藏标题 或 显示标题 来进行切换是否显示。用鼠标左键点击注释标签可以切换注释显示的方式。
寄存器窗口:显示当前所选线程的 CPU 寄存器内容。同样点击标签 寄存器 (FPU) 可以切换显示寄存器的方式。
信息窗口:显示反汇编窗口中选中的第一个命令的参数及一些跳转目标地址、字串等。
数据窗口:显示内存或文件的内容。右键菜单可用于切换显示方式。
堆栈窗口:显示当前线程的堆栈。
载入程序
点击菜单 文件->打开 (快捷键是 F3)来打开一个可执行文件进行调试
调试中我们经常要用到的快捷键有这些:

F2:设置断点,只要在光标定位的位置(上图中灰色条)按F2键即可,再按一次F2键则会删除断点。(相当于 SoftICE 中的 F9)
F8:单步步过。每按一次这个键执行一条反汇编窗口中的一条指令,遇到 CALL 等子程序不进入其代码。(相当于 SoftICE 中的 F10)
F7:单步步入。功能同单步步过(F8)类似,区别是遇到 CALL 等子程序时会进入其中,进入后首先会停留在子程序的第一条指令上。(相当于 SoftICE 中的 F8)
F4:运行到选定位置。作用就是直接运行到光标所在位置处暂停。(相当于 SoftICE 中的 F7)
F9:运行。按下这个键如果没有设置相应断点的话,被调试的程序将直接开始运行。(相当于 SoftICE 中的 F5)
CTR+F9:执行到返回。此命令在执行到一个 ret (返回指令)指令时暂停,常用于从系统领空返回到我们调试的程序领空。(相当于 SoftICE 中的 F12)
ALT+F9:执行到用户代码。可用于从系统领空快速返回到我们调试的程序领空。(相当于 SoftICE 中的 F11)
第一次操作
了解基本操作以后我们就可以开始尝试自己对CPU下指令了。
开始之前我们先了解下汇编语言的基本格式:
指令 目标操作数,源操作数
这里关于操作数有三种:通用寄存器、内存和立即数r 代表通用寄存器,m 代表内存,imm 代表立即数,r8 代表8位通用寄存器,m8 代表8位内存,imm8 代表8位立即数,以此类推。
现在让我们从MOV开始:
任意加载一个程序后,双击第一行汇编代码,输入 “MOV EAX,11”

我们可以看到这里的汇编代码已经变成了我们输入的代码,此时我们观察右边的寄存器窗口中,EAX的值是一个程序执行过程中产生的值。

在我们按下F8后可以看到EAX变成了11(十六进制),并且汇编窗口的灰色高亮部分下移了一格,这代表上一条命令已经执行,下一条命令的内存地址是009E0921,同时我们可以看到寄存器窗口的EIP的值也是009E0921,因为EIP正是指令存储器,用来存储CPU要读取指令的地址。

MOV指令表示数据传送,其格式为:
MOV r/m8,r8
MOV r/m16,r16
MOV r/m32,r32
MOV r8,r/m
MOV r16,r/m16
MOV r32,r/m32
MOV r8, imm8
MOV r16,imm16
MOV r32,imm32
这里我们可以看到MOV指令要求源操作数和目的操作数的长度一致。并且我们不能通过MOV指令直接将内存中的值传递到内存。
寄存器是有固定大小的,当我们需要操作内存时该如何表示内存的宽度尼?
BYTE字节(8bit)、WORD字(16bit)、DWORD双字(32bit)
例如:
读取目标内存的数到EAX
mov eax, dword ptr ds:[0x009E3000]

我们还可以通过寄存器来表示内存地址:
move ecx, 0x009E3000
mov eax, dword ptr ds:[ecx]
甚至可以对寄存器中的值进行计算后操作:
mov eax, dword ptr ds:[ecx+16]
基础指令
了解了汇编语言的基本语法,接下来把常用的汇编指令简单介绍一下
运算类指令
ADD指令
表示数据相加,其格式为:
// ADD 目标操作数,源操作数
// 含义:将源操作数与目标操作数相加,最后结果给到目标操作数
ADD r/m8, imm8
ADD r/m16,imm16
ADD r/m32,imm32
ADD r/m16, imm8
ADD r/m32, imm8
ADD r/m8, r8
ADD r/m16, r16
ADD r/m32, r32
ADD r8, r/m8
ADD r16, r/m16
ADD r32, r/m32
SUB指令
表示数据相减,其格式为:
// SUB 目标操作数,源操作数
// 含义:将源操作数与目标操作数相减,最后结果给到目标操作数
SUB r/m8, imm8
SUB r/m16,imm16
SUB r/m32,imm32
SUB r/m16, imm8
SUB r/m32, imm8
SUB r/m8, r8
SUB r/m16, r16
SUB r/m32, r32
SUB r8, r/m8
SUB r16, r/m16
SUB r32, r/m32
AND指令
表示数据相与(位运算知识),其格式为:
// AND 目标操作数,源操作数
// 含义:将源操作数与目标操作数进行与运算,最后结果给到目标操作数
AND r/m8, imm8
AND r/m16,imm16
AND r/m32,imm32
AND r/m16, imm8
AND r/m32, imm8
AND r/m8, r8
AND r/m16, r16
AND r/m32, r32
AND r8, r/m8
AND r16, r/m16
AND r32, r/m32
OR指令
表示数据相或(位运算知识),其格式为:
// AND 目标操作数,源操作数
// 含义:将源操作数与目标操作数进行或运算,最后结果给到目标操作数
OR r/m8, imm8
OR r/m16,imm16
OR r/m32,imm32
OR r/m16, imm8
OR r/m32, imm8
OR r/m8, r8
OR r/m16, r16
OR r/m32, r32
OR r8, r/m8
OR r16, r/m16
OR r32, r/m32
XOR指令
表示数据相异或(位运算知识),其格式为:
// XOR 目标操作数,源操作数
// 含义:将源操作数与目标操作数进行异或运算,最后结果给到目标操作数
XOR r/m8, imm8
XOR r/m16,imm16
XOR r/m32,imm32
XOR r/m16, imm8
XOR r/m32, imm8
XOR r/m8, r8
XOR r/m16, r16
XOR r/m32, r32
XOR r8, r/m8
XOR r16, r/m16
XOR r32, r/m32
NOT指令
表示非(位运算知识),其格式为:
// NOT 目标操作数
// 含义:将目标操作数进行非运算,最后结果给到目标操作数
NOT r/m8
NOT r/m16
NOT r/m32
变址寄存器操作指令
MOVS指令
表示数据传送,它与MOV的不同处在于,它可以直接将内存的数据传送到内存,但也仅仅能如此,其格式为:
// MOVS EDI指定的内存地址,ESI指定的内存地址
// 含义:将ESI指定的内存地址的数据传送到EDI指定的内存地址(使用MOVS指令时,默认使用的就是ESI和EDI寄存器),MOVS指令执行完成后ESI、EDI寄存器的值会自增或自减,自增或自减多少取决于传送数据的数据宽度.
**注意:MOVS指令操作必须通过ESI EDI两个寄存器来指明内存地址,否则OD无法下发指令
MOVS BYTE PTR ES:[EDI], BYTE PTR DS:[ESI] //简写为:MOVSB
MOVS WORD PTR ES:[EDI], WORD PTR DS:[ESI] //简写为:MOVSW
MOVS DWORD PTR ES:[EDI], DWORD PTR DS:[ESI] //简写为:MOVSD
这里做个小实验,我们在OD中输入如下代码:
MOV EAX,1
NOT EAX
MOV EBA,1
mov dword ptr es:[009e3000],eax
mov dword ptr es:[009e3010],ebx//随便做俩值存到内存
mov esi,0x9e3000
mov edi,0x9e3010//把这俩值的内存地址存进esi edi
movs dword ptr es:[edi],dword ptr ds:[esi]//将esi的值复制到edi
mov dword ptr es:[009e3010],1234//将edi的值重置为0x1234
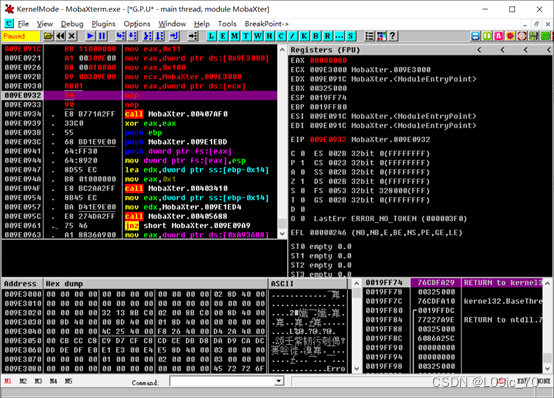
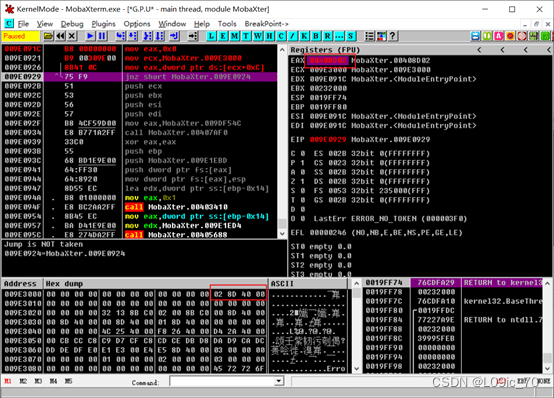
movsd//输入后OD会自动生成完整的指令
我们执行观察一下:

EAX EBX的值成功通过MOV指令传递到目标内存地址

成功通过MOVS指令将9e3000的值复制到9e3010

置9E3010的值并再次把ESI 的值复制到EDI,发现并没有成功
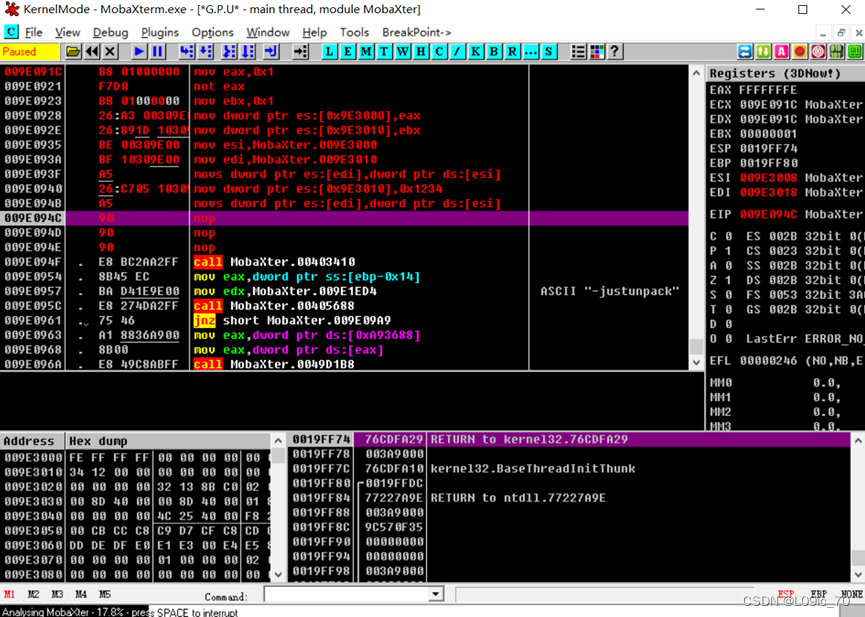
原来是因为ESI和EDI发生了变化,因为MOVS后的操作数是DWORD,所以ESI和EDI自增了8(2个字=8个字节) 这是ESI和EDI非常重要的特性,我们会在后续的内容中详细说明它的一些应用(并且在某些情况下操作ESI EDI后他们的值是自减的)。
STOS指令
表示将AL/AX/EAX的值储存到EDI指定的内存地址,其格式为:
// STOS EDI指定的内存地址
// 含义:将AL/AX/EAX的值储存到EDI指定的内存地址,STOS指令执行完成后EDI寄存器的值会自增或自减,自增或自减多少取决于传送数据的数据宽度,与MOVS指令一样自增或自减取决于DF位
STOS BYTE PTR ES:[EDI] //简写为:STOSB
STOS WORD PTR ES:[EDI] //简写为:STOSW
STOS DWORD PTR ES:[EDI] //简写为:STOSD
REP指令
表示循环,其格式为:
// REP MOVS指令/STOS指令
// 含义:循环执行MOVS指令或STOS指令,循环次数取决于ECX寄存器中的值,每执行一次,ECX寄存器中的值就会减一,直至为零,REP指令执行完成
REP MOVSB
REP MOVSW
REP MOVSD
REP STOSB
REP STOSW
REP STOSD
堆栈操作指令
Stack
我们这里讲的不是数据结构里的栈,而是一种叫 运行时堆栈 的东西。
- 栈(stack)又名堆栈是操作系统在建立某个进程时或者线程,为这个线程建立的存储区域,在编译的时候可以指定需要的栈的大小
- 栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
- 栈好比一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来(先进后出)。
上面是百度百科的定义,看了可能有点似懂非懂,我们拿出点东西来瞅瞅
首先,在OD右侧的寄存器窗口可以看到 EBP 和 ESP这两个寄存器。分别用来存放堆栈的栈底地址和栈顶地址

这里我们可以看到栈顶的内存地址要小于栈底。 在命令框输入 DD 0019FF74看下内存
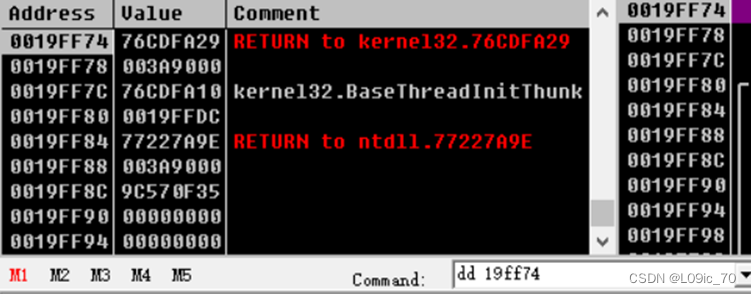
从上面的描述我们知道栈是一种只能对栈顶做操作的内存结构,我们就来看看如何对堆栈进行操作
能对栈顶做操作的内存结构,我们就来看看如何对堆栈进行操作
PUSH指令
表示压入数据,其格式为:
// PUSH 通用寄存器/内存地址/立即数
// 含义:向堆栈中压入数据,压入数据后会提升(sub)栈顶指针(ESP),提升多少取决于压入数据的数据宽度
PUSH r16/r32
PUSH m16/m32
PUSH imm8/imm16/imm32
我们执行 push EAX后可以看到首先ESP从0019FF74变为0019FF70,减少了4字节。然后看内存中EAX的值被存放到了0019ff70
由此我们可以知道,PUSH EAX的运行可以拆解为
SUB ESP , 0x4
MOV DOWRD PTR ES:[ESP],EAX

POP指令
表示释放数据,其格式为:
// POP 通用寄存器/内存地址
// 含义:释放压入堆栈中的数据,释放数据后会下降(add)栈顶指针(ESP),下降多少取决于释放数据的数据宽度
POP r16/r32
POP m16/m32
我们执行了POP EBX后观察寄存器和内存的变化:首先原先ESP从ESP从0019FF70变回了0019FF74,位于0019FF70的值被复制到了EBX.并且0019FF70的值并没有发生改变
由此我们可以把 POP EBX拆解为
MOV EBX,DWORD PTR DS:[ESP]
ADD ESP ,0x4

修改EIP的指令
EIP也是寄存器,但它不叫通用寄存器,它里面存放的值是CPU下次要执行的指令地址;当我们想去修改它的值就不能使用修改通用寄存器那些指令了,修改EIP有其特有的指令,接下来让我们来了解一下吧。
JMP指令
表示跳转,其格式为:
// JMP 寄存器/内存/立即数
// 含义:JMP指令会修改EIP的值为指定的指令地址,也就修改了程序下一次执行的指令地址,我们也可以称之为跳转到某条指令地址。
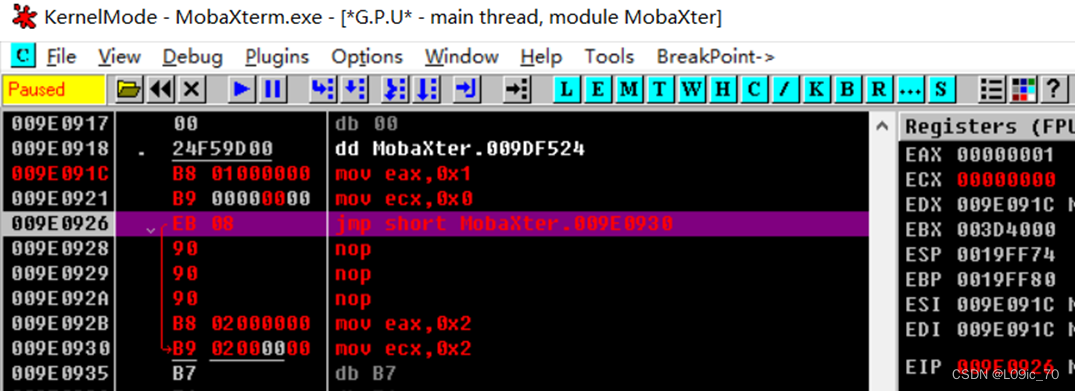
如图,输入汇编指令如下:
MOV EAX,1
MOV ECX,0
JMP 009E0930
MOV EAX,2
MOV ECX,2
JMP指令执行后,我们发现寄存器仅EIP发生了改变:直接变成我们输入的地址

执行下一步果然跳过了MOV EAX,2直接执行了MOV ECX,2
CALL指令
也可以修改EIP,跟JMP指令的功能是一样的,其格式为:
// CALL 寄存器/内存/立即数
// 含义:跟JMP指令的功能是一样的,同样也可以修改EIP的值,不同的点是,CALL指令执行后会将其下一条指令地址压入堆栈,ESP栈顶指针的值减4
// 注意:在我们使用OD调试的时候,要跟进CALL指令不能使用F8要是用F7
RET指令
表示返回,其格式为:
RET
// 含义:将当前栈顶指针的值赋给EIP,然后让栈顶指针加4,等价于POP EIP
再来个基础概念——标志寄存器
在OD中标志寄存器就是这一部分:

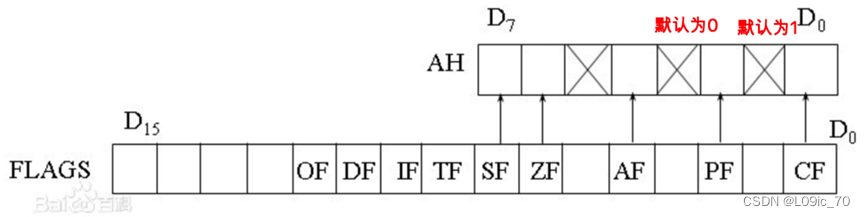
16位标志寄存器是:FLAGS
- 条件标志位:SF、ZF、OF、CF、AF、PF
CPU在执行完一条指令之后进行自动设置,反映了算数、逻辑运算等指令执行完毕之后,运算结果的特征。
- 控制标志位:DF、IF、TF
控制CPU的运行方式和工作状态。
条件标志位
- 进位标志:【CF】—运算结果的最高有效位有进位(加法)或者借位(减法)。用于表示两个无符号数高低。
- 零标志:【ZF】—如果运算结果位0,则ZF=1,否则ZF=0
- 溢出标志位:【OF】—当将操作数作为有符号数的时候,使用该标志位判断运算结果是否溢出。加法:若相同符号数相加,结果的符号与之相反则OF=1,否则OF=0。
减法:若被减数与减数符号不相同,而结果的符号与减数相同则OF=1,否则OF=0发生溢出,说明运算的结果已经不可信
- 标志符号:【SF】—运算结果最高位为1,SF=1,否则SF=0。有符号数用最高有效位表示数据的符号,最高有效位是标志符号的状态。
- 奇偶标志位:【PF】—当运算结果(指的是低8位)中1的个数为偶数时,PF=1,否则PF=0。该标志位主要用于检测数据在传输过程中是否出错
- 辅助进位标志位:【AF】—一个字节运算的时候低4位向高4位的进位和错位。
注意
1. 进位针对的是无符号数运算,溢出针对的是有符号数运算
2. 进位了,可以根据CF标志位得到正确的结果,溢出了,结果已经不正确了。
3. 汇编中的数据类型由程序员决定,也就是没有类型,程序员说是什么类型就是什么类型。所以当看到无符号数,则关注CF标志,看成有符号数,关注OF标志。
如下汇编代码:

我们往下走两步完成赋值
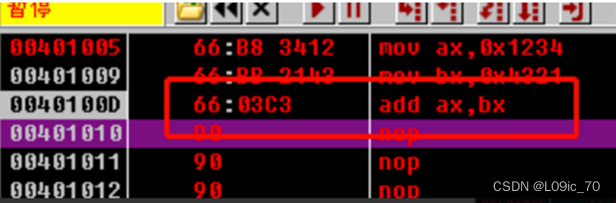
现在去跑ADD指令:

因为此处ADD指令是进行了运算结果不是0,固ZF位=0,在汇编中没有像C语言这样高级语言中有if语句、while语句,那它是怎么实现这些功能呢?
- 标志寄存器
- JCC指令
如何操作标志寄存器
LAHF(Load AH with flags)指令:用于将标志寄存器的低八位送入AH,即将标志寄存器FLAGS中的SF、ZF、AF、PF、CF五个标志位分别传送到AH的对应位(八位中有三位是无效的)
SAHF(store AH into flags)指令:用于将AH寄存器送入标志寄存器
PUSHF(push the flags)指令:用于将标志寄存器送入栈 → push eflags
POPF(pop the flags)指令:用于将标志寄存器送出栈 → pop eflags

我们来做一个实验,首先将EAX置为0,然后CF、PF位为1,这时候我们调用LAHF将标志寄存器送入AH会得到怎样的数据呢?

这时候我们F8运行这一条指令,我们就会发现AH=0x700,这里我们来算一下
 那么转换过来就是011100000000 → 0x700,CF和PF位之间的下标为1的空,默认为1。
那么转换过来就是011100000000 → 0x700,CF和PF位之间的下标为1的空,默认为1。
汇编眼中的函数
什么是函数?函数就是一系列指令的集合,为了完成某个会重复使用的特定功能。
那么在汇编中如何定义、使用函数呢?既然我们知道函数就是一系列指令的集合,那么只要我们随便写一段汇编代码即可:
mov eax, 0x1
我们将其写在了执行地址0x00460A32中,想要调用这个函数,需要使用JMP、CALL指令来调用。
但是我们一般不会使用JMP来调用函数,因为它执行完后没办法返回到原来要执行的地址,所以我们选择CALL指令,CALL指令需要搭配RET指令一起使用。
一般我们在函数指令集合的最后写入RET指令,以此来实现函数执行完后返回原来要执行的地址继续执行。

那假设我们需要做一个任意两个数的加法函数该怎么办?这时候就需要想办法将我们的任意两个数传入函数中,这也就是参数;加法函数计算结果就称之为返回值。
返回值在汇编中一般使用EAX存储,我们可以使用ECX、EDX作为传递参数,接下来我们编写加法函数:
add eax,ecx
add eax,edx
ret
实际场景:

在这里我们使用的是寄存器传递参数,但实际上还可以使用堆栈传参数,下一章节我们会介绍。
堆栈传参
当函数有很多参数的时候,不止8个,那我们使用通用寄存器去传参,明显不够用,所以我们需要使用堆栈帮助我们传递参数。
还是以加法举例,实际场景:

如上图所示实现算术1+2,首先将1、2依次压入堆栈,CALL指令也会将其下一行指令地址压入堆栈,所以堆栈地址[ESP+8]为第一个压入的数据,堆栈地址[ESP+4]为第二个压入的数据。
堆栈平衡
我们知道当执行函数调用CALL指令的时候,会把CALL指令下一条指令的内存地址压入堆栈(ESP值减4);在函数内我们可以随意使用堆栈,比如PUSH指令压入堆栈,使用堆栈传参等等...
我们需要保证,在函数调用结束的时候(即执行RET指令之前,要把ESP栈顶指针的值修改为执行CALL指令压入堆栈或堆栈传参压入堆栈前的那个ESP栈顶指针的值),保证函数运行前与运行后ESP栈顶指针的值不变,这个我们称之为堆栈平衡。
第一种情况导致堆栈不平衡(函数内压栈):

函数内压栈会导致执行RET指令后,ESP-4,程序会到00000002这个执行地址继续执行,而不再是CALL指令下一行地址继续执行。
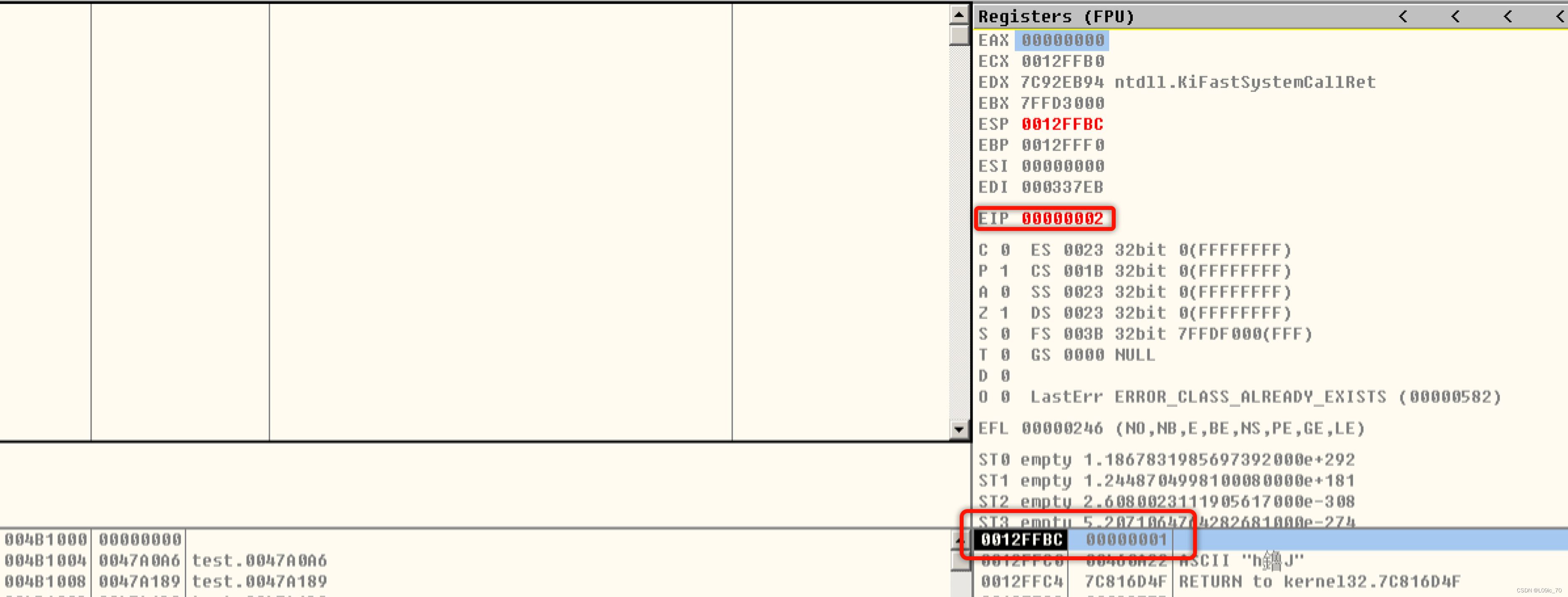
第二种情况导致堆栈不平衡(堆栈传参):

当RET指令之后,栈顶指针无法回到传参前的值。
平衡堆栈有两个方法:
1.外平栈:使用ADD指令。

2.内平栈:使用RET指令,例如压入了2个32位(4字节)数据就可以写为RET 8。
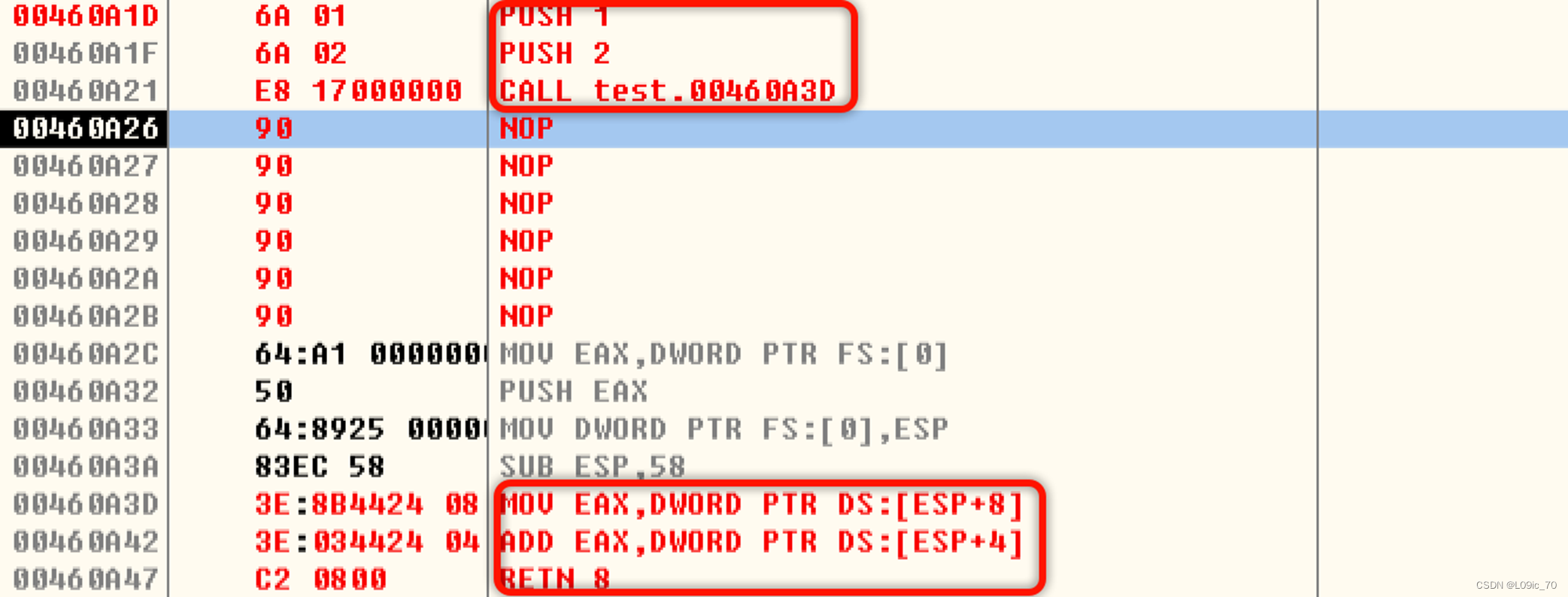
对于第一种情况我们可以在函数内使用完堆栈后,POP释放数据;对于第二种堆栈传参导致的堆栈不平衡,我们可以使用外平栈、内平栈的方法。
ESP寻址
之前我们了解了函数,以及堆栈传参,那其实我们获取参数就是借助的ESP去获取对应参数的地址,这种行为我们称之为ESP寻址。
需要注意的是我们获取参数的值,指令应为:
mov eax, dword ptr ss:[esp+4]
你会发现原来指令中的ds变为了ss,这是因为当你的内存地址是esp或ebp组成的需要使用ss,暂时先不用管原因。
ESP寻址弊端:当函数比较复杂时,使用的时候要使用很多寄存器,需要把寄存器的值保存在堆栈中备份,寻址计算会复杂一些。
EBP寻址
之前都是借用ESP去寻址确定一些参数 ,但如果存到堆栈里面的值过多,那么就得不断地调整ESP的指向,这是ESP寻址的缺点。
那么EBP寻址的思路是什么呢?先把EBP的值保存起来,然后将EBP指向ESP的位置,接着在原来的堆栈基础上将ESP上移,重新变成一块新的堆栈;之后新的程序再使用堆栈的时候,只影响ESP但不会影响EBP,那我们寻址的时候使用EBP去寻址,EBP的位置相对固定,程序不管如何操作ESP都会不停浮动,但是EBP相对稳定。
寻找Main函数
在以往的学习中,我们一直被告知每个程序都是从main函数开始的,但真的是这样吗?我们随便写个Hello World举个例子
#include <stdio.h>
int main(){
printf("YouFoundMain!");
}把使用VC++6.0编译链接后生成EXE文件丢进OD中看看,完全不是我们认识的东西
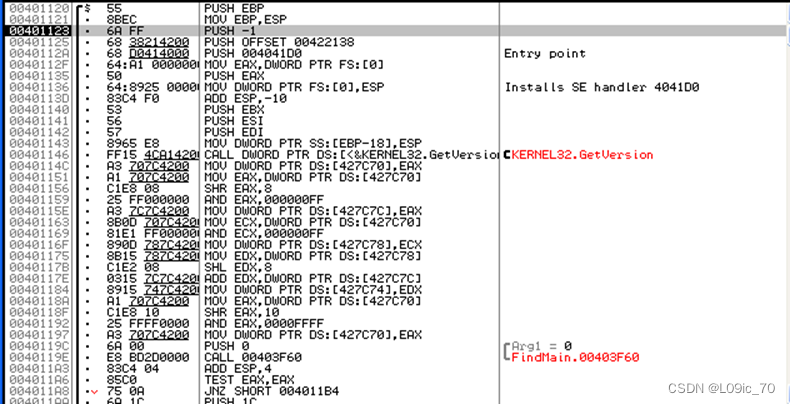
我们在VC++6.0中调试该程序,在call stack窗口可以看到main函数是被mainCRTStartup调用的。

由于我们手里的VC++6.0不是完整版,并不能通过双击获取到mainCRTSartup的源码,这里百度了一下。

我们可以根据源码看到mainCRTStartup中的函数调用关系:
- GetVersion函数:获取当前运行平台的版本号。控制台下则为MS-DOS的版本信息。
- fast_erro_exit函数
- _mtinit函数:线程初始化
- _heap_init函数:用于初始化堆空间。在函数实现中使用HeapCreate申请堆空间
- GetCommandLineA函数:获取命令行参数信息的首地址
- _crtGetEnvironmentStringA函数:获取环境变量信息的首地址
- _setargv函数:此函数根据GetCommandLineA获取命令行参数信息的首地址并进行参数分析 注意主函数的参数就在这里获得!
- _setenvp函数:此函数根据_crtGetEnvironmentStringA函数获取环境变量信息的首地址进行分析。
- _cinit函数:用于全局变量数据和浮点数寄存器的初始化。
- main函数
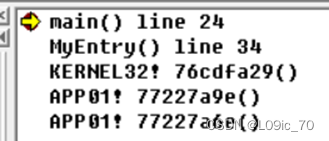
我们按照这个逻辑在OD中一路F8执行,第一个CALL是GetVersion,第五个是GetCommandLineA,所以第十个应该是main函数(且第十个函数调用前明显完成了3次传参)
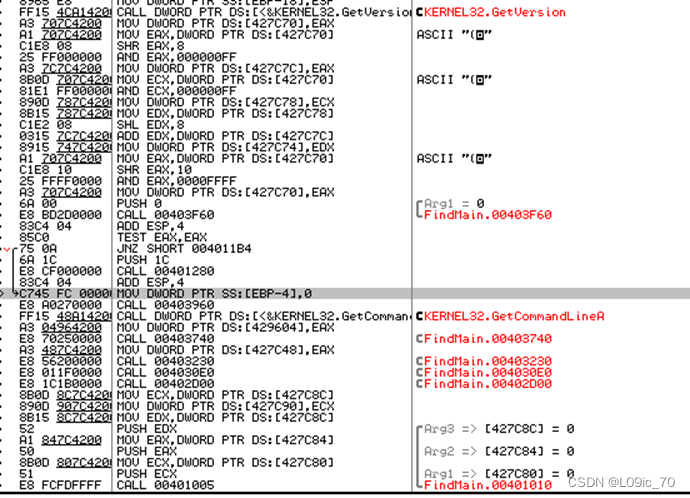
在 这里步入发现确实是main函数
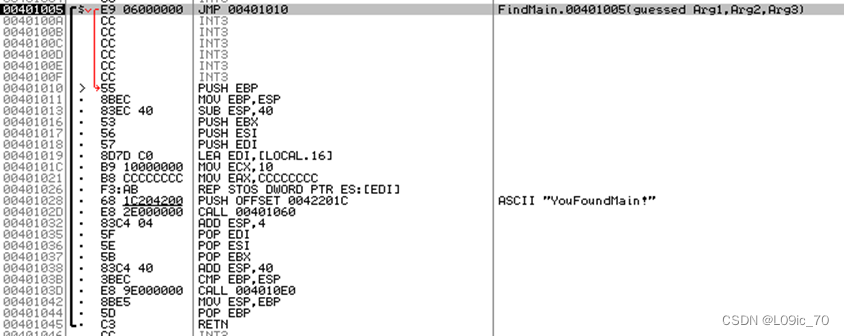
使用OD判断main函数还是比较复杂的,因为编译器不同的情况下调用main函数的函数(VC6.0是mainCRTStartup,其他版本或其他编译器和本次的分析多少有些出入)内容是不确定的,比较依赖分析人员对不同编译器的熟悉程度。目前来看,应该除了main函数,其他初始化函数的参数是没有3个的,这也可以作为main函数识别的依据。
小实验:
VC++6.0中,编译器工具栏 Project – Setting – Link – Output ,在Entry-point symbol中可以改变入口函数,可以替代mainCRTStartup

#include "stdafx.h"
#include <stdio.h>
#include <malloc.h>
class COne
{
public:
COne()
{
printf("COne \r\n");
}
~COne()
{
printf("~COne \r\n");
}
};
COne g_One;
int main()
{
printf("main函数识别 \r\n");
return 0;
}
void MyEntry()
{
// 产生错误代码
// int *p = (int*)malloc(16);
main();
}上述代码正常运行时,我们会在main函数执行前执行Cone的构造函数,在main函数结束后执行Cone的析构函数。我们更改配置后调试可以发现CallStack中mainCRTSartup已经变为MyEntry
执行过程中由于MyEntry函数中并没有对进程和堆做初始化处理,所以编译器在处理全局变量时会报错

函数初始化
书接上回,我们找到了main函数。那么我们的程序在汇编层面具体是怎么执行的呢?
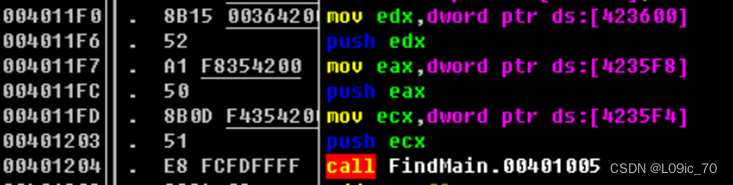
首先我们看到在main函数调用前,完成了3次参数的压栈。这时堆栈视图如下所示

为了看的更直观,这里用VC++6.0的反汇编调试功能:在VC++6.0 F9下好断点后,F5运行调试,再使用快捷键ALT+8切换到反汇编窗口(或者右键选择Go To Disassembly),如下图所示,我们能看到每句C代码对应的汇编指令。

这里主函数中只有一行printf函数的调用,那在执行这个函数调用前,程序都做了什么尼?
这里的分析我们推荐大家通过画堆栈图的方式学习,并牢记于心
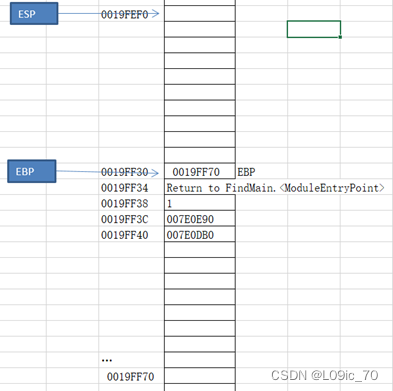
- 记录下ESP EBP 的初始位置ESP = 0019FF34 EBP = 0019FF70 ,在Excel中随便找一处作为ESP起始位置的标记

- 在VC++6.0执行PUSH EBP后,当前EBP内存储的数据(也就是栈底内存地址)被压入了栈顶
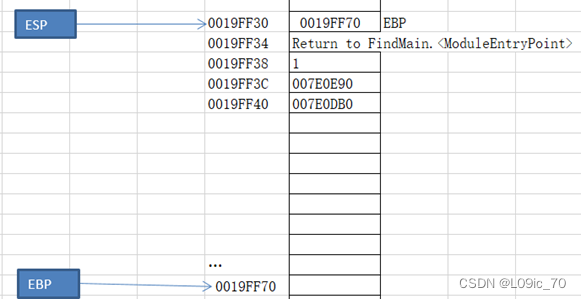
- MOV EBP,ESP 上一步保存好EBP的值后,我们把EBP指向ESP当前的位置

- sub esp,40h ESP向上移动4*16字节,这96个字节就是main函数初始的堆栈大小

- push ebx;push esi;push edi 将EBX ESI EDI压栈保存

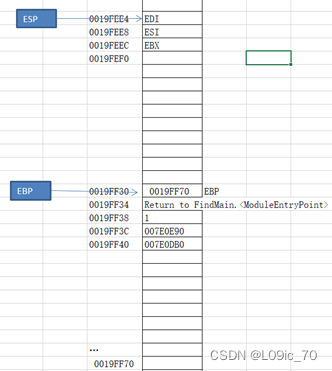
- lea edi,[ebp-40h]
mov ecx,10h
mov eax,0CCCCCCCCh
rep stos dword ptr [edi] 通过将EBP-40传入EDI,设置循环次数为16次,设置填充内容为0CCCCCCCC,从而在新的堆栈中填充断点.

到这里我们一个函数的堆栈初始化过程就分析完了,经过初始化操作一个函数的堆栈空间可以分为如图所示的不同区域,绿色是函数内的局部变量所需的空间,橙色是存放函数入参的空间,红色是函数调用完成后下一步指令的内存地址
















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









