







分析:第一次看这个算法的时候觉得应该还算简单,真正写的时候才发现,涉及了很多种情况,要完整弄清楚还真不是件简单的事情
引用百度百科:KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。
这个算法的难点在于计算next[],也就是最大前缀后缀,
比如字符串ptr ,ababaca,长度是7,next[0],next[1],next[2],next[3],next[4],next[5],next[6]的值分别对应的是a,ab,aba,abab,ababa,ababac,ababaca的长前缀后缀的长度,
最长前缀后缀是“”,“”,“a","ab","aba","","a",next数组的值为{-1,-1,0,1,2,-1,0}
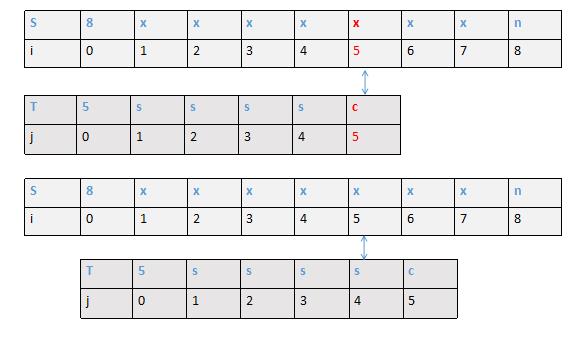
接下来,以图的方式,分别介绍四种情况
第一种
模式串和目标串到第5号位置S[5]='d',T[5] = 'z'不匹配,此时由于模式串5位置前不存在最大前缀后缀,所以j直接回溯到位置1,重新开始遍历
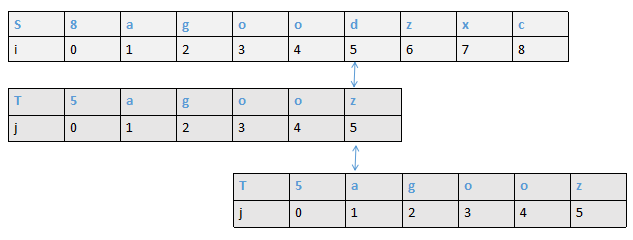
第二种
模式串和目标串到第5号位置S[3]='w',T[3] = '.' 不匹配,此时由于模式串2位置前存在最大前缀后缀 w ,所以j直接回溯到位置2,重新开始遍历
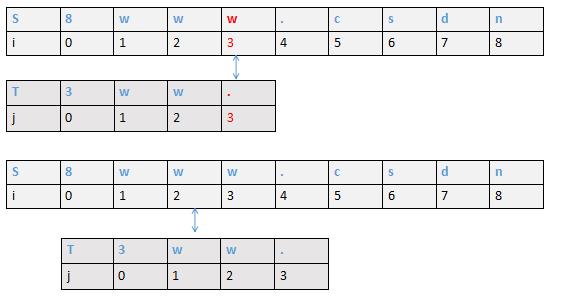
第三种
模式串和目标串到第5号位置S[6]='s',T6] = 'c' 不匹配,此时由于模式串6位置前存在最大前缀后缀 bb ,所以j直接回溯到位置3,重新开始遍历
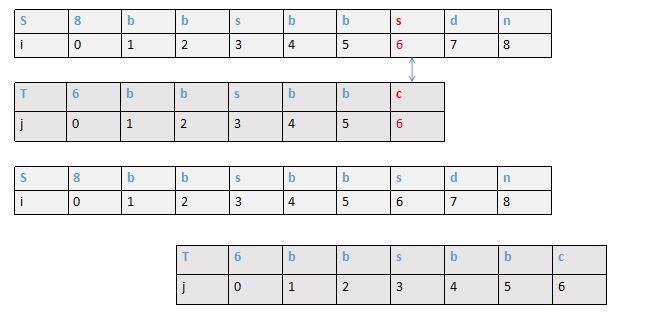
第四种
模式串和目标串到第5号位置S[5]='x',T[5] = 'c' 不匹配,此时由于模式串5位置前存在最大前缀后缀sss ,所以j直接回溯到位置4,重新开始遍历
我们发现,KMP算法的关键在于得出next[],由以上分析我们得出next[]
计算next[]
void nextArr(char *pArr,int pLen,int *next)
{
int k = -1;//k初始化为-1
next[0] = -1;//-1表示没有最大前缀后缀
for(int i=1; i<=pLen-1; i++)
{
while(k>-1 && pArr[k+1]!=pArr[i])//如果下一个元素不同k变为-1,回到模式串头
{
k = -1;
}
if(pArr[k+1]==pArr[i])//如果相同k++
{
k++;
}
next[i] = k;//这里把k即相同最大前缀后缀值的长赋给next[i]
}
}KMP匹配
void KMP(int *next,char *pArr,int pLen,char *arr,int len)
{
int k = -1;//k初始化为-1
for(int i=0; i<len; ++i)//从下标0开始对目标串匹配
{
while(k>-1 && pArr[k+1]!=arr[i])//模式串与目标串比较
{
k = next[k]; //如果k>-1,且元素不相等,则k=next[k]回溯
}
if(pArr[k+1]==arr[i]) //如果元素对应相等,k++
{
k++;
}
if(k==pLen-1) //当k = pLen-1,说明模式串匹配成功
{
k = -1;
printf("i = %d\n",i-pLen+1);//打印匹配成功的位置
}
}
}
main调用测试
int main(void)
{
char parr[10] = "aba";
char arr[20] = "aababcabac";
int next[10];
nextArr(parr,3,next);
KMP(next,parr,3,arr,10);
return 0;
}














 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









