







这一节,我们来实现爬取知乎‘美女’话题下的子问题以及相关问题回答的赞同数前两名。
上两节,我们爬取了百度首页的源码,实现了百度LOGO的抓取和下载。这一次我们的目标是知乎。
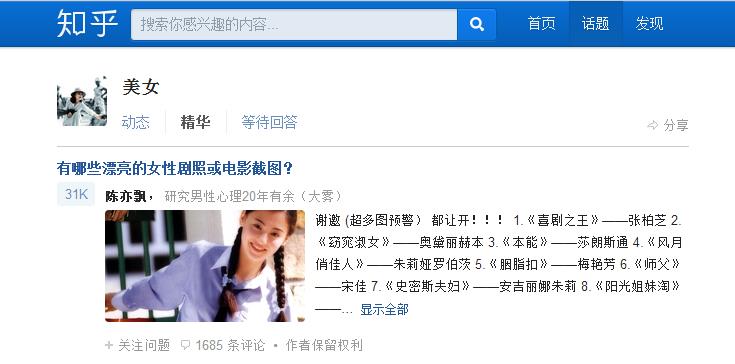
先来看下程序运行效果

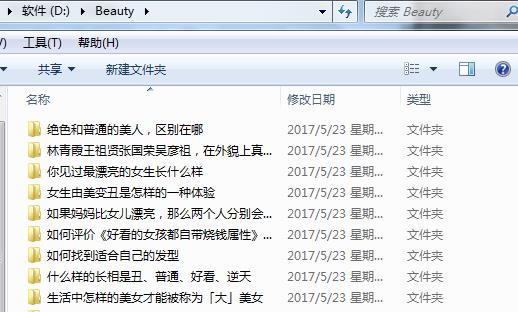
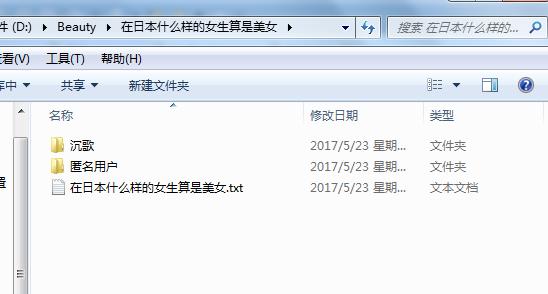
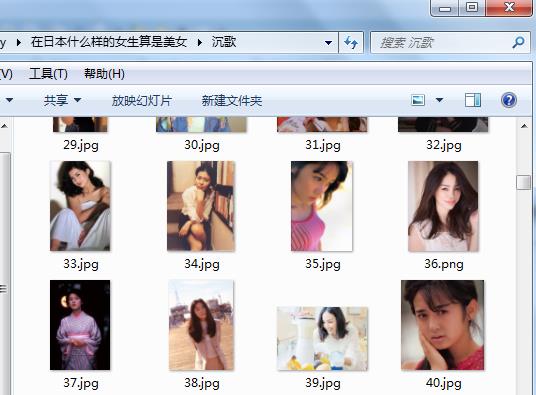
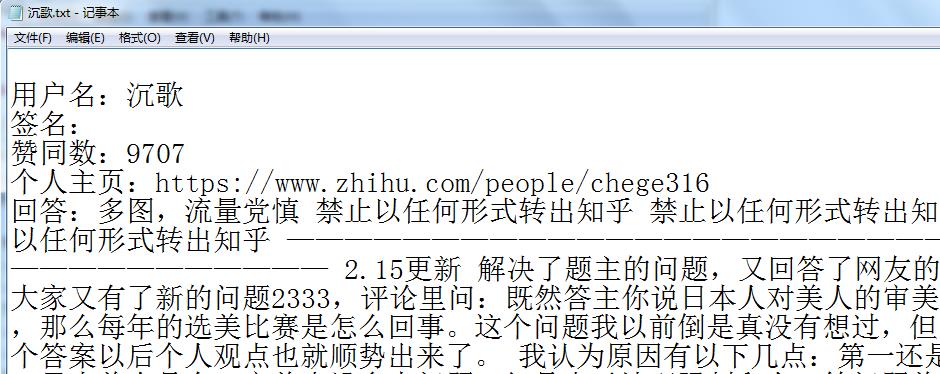
可以看到,美女话题下一些数据被我们爬取下来了。
下面来简要的讲一下实现,程序数据的分析工作由jsoup实现,用到了IO、net的知识。算是一个比较综合的小程序。
首先确定我们需要爬取的东西。
1.话题链接
2.子问题属性
3.回答者属性
4.回答赞同数
5.回答内容(包括图片)
这里可以分为五个类
1.ZhihuSpider 类,负责抓取话题下每个子问题块
2.Zhihu 类,负责抓取存储相应子问题
3.Author 类,负责储存回答者的信息
4.WriteIntiFile 类,负责把数据写入文件
5.ZhihuMain 类,负责调用
如图所示,调用关系
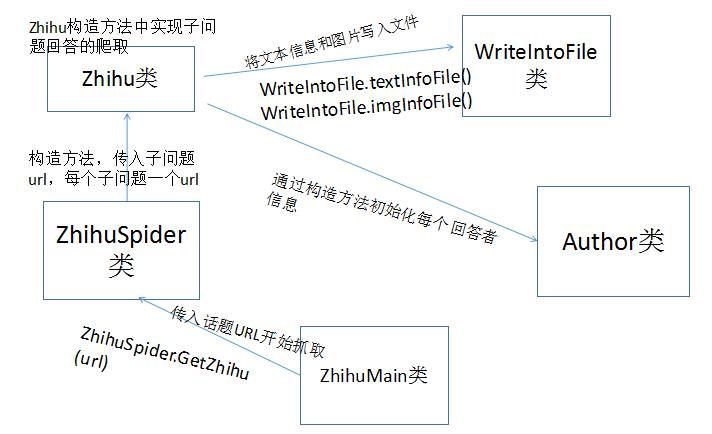
通俗点说,就是ZhihuMain调用ZhihuSpider中的getZhihu静态方法,通过jsoup分析话题首页,获得每个子问题的url,每个url通过构造方法新建一个Zhihu对象,在Zhihu的构造方法中,使用jsoup抓取问题回答的的信息,得到的数据构造初始化一个Author对象,同时调用getImgUrls静态方法,获得每个图片的url地址,最后,利用WriteIntoFile的两个静态方法,把文本和图片写入到对应的文件夹中。
后面是具体实现,大部分都有注释
public class ZhihuMain {
//定义静态文件路径名
static String grandFilePath; //第一层
static String parentFilePath; //第二层
static String childFilePath; //第三层
public static void main(String[] args) {
//话题URL
String url = "https://www.zhihu.com/topic/19552207/top-answers";
//静态调用GetZhihu
ZhihuSpider.GetZhihu(url);
}
}import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ZhihuSpider {
static ArrayList<Zhihu> GetZhihu(String url) {
ArrayList<Zhihu> results = new ArrayList<Zhihu>();
Document doc;
// 创建父文件夹
ZhihuMain.grandFilePath = "d:/Beauty";
File file = new File(ZhihuMain.grandFilePath);
file.mkdir();
//打印提示信息
System.out.println("开始抓取知乎-美女-话题\n");
try {
doc = Jsoup.connect(url).get();
//通过审查元素得到子问题块所在的标签
Elements ListDiv = doc.select("h2");
for (Element element : ListDiv) {
//href属性在a标签中
element = element.select("a").first();
//获得子问题链接
String linkHref = element.attr("href");
//获得子问题文本名
String line = element.text().trim();
ZhihuMain.parentFilePath = line.substring(0, line.length() - 1);
//打印提示信息
System.out.println("抓取问题 :" + ZhihuMain.parentFilePath);
// 创建子问题文件夹
file = new File(ZhihuMain.grandFilePath + "/" + ZhihuMain.parentFilePath);
file.mkdir();
//构造方法初始化Zhihu对象,这时候跳到Zhihu的构造方法中
Zhihu zhihu = new Zhihu(linkHref);
results.add(zhihu);
}
} catch (IOException e) {
e.printStackTrace();
}
return results;
}
}
import java.io.File;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Set;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Zhihu {
public String questionHeader;
public String questionDescription;
public String zhihuURL;
public Author author;
public ArrayList<Author> authorList;
// 构造方法初始化数据
public Zhihu(String url) {
questionHeader = "";
questionDescription = "";
zhihuURL = "https://www.zhihu.com" + url; // 构造完整的问题链接
int count = 0;// 计数,仅抓取前2个回答
Document doc;
Set<String> set = null;// 图片集合
try {
//连接子问题
doc = Jsoup.connect(zhihuURL).get();
// 问题标题
Elements head = doc.getElementsByAttributeValue("class", "QuestionHeader-title");
questionHeader = head.text().trim();
// 问题描述
Elements description = doc.getElementsByAttributeValue("class", "RichText");
questionDescription = description.text().trim();
// 问题及描述写入子问题文件夹
String filePath = ZhihuMain.grandFilePath + "/" + ZhihuMain.parentFilePath;
WriteIntoFile.textInfoFile(filePath, WritingZhihu());
// 抓取每个回答块
Elements ListItem = doc.getElementsByAttributeValue("class", "List-item");
int size = ListItem.size();
authorList = new ArrayList<Author>(size);
for (Element list : ListItem) {
if (count == 2) // 仅抓取前2个回答
return;
count++;
// 初始化author属性
String name = list.getElementsByAttributeValue("class", "UserLink-link").text().trim();
//如果是匿名用户没有姓名
if ("".equals(name))
name = "匿名用户";
String personalDetail = list.getElementsByAttributeValue("class", "AuthorInfo-detail").text().trim();
String agreement = list.getElementsByAttributeValue("class", "Button VoteButton VoteButton--up").text()
.trim();
String personURL = "https://www.zhihu.com"+list.getElementsByAttributeValue("class", "UserLink-link").attr("href");
String answer = doc.getElementsByAttributeValue("class", "RichContent-inner").text().trim();
System.out.println("抓取回答者 :" + name);
// 新建author对象
author = new Author(name, personalDetail, agreement, personURL, answer);
// 放入author集合中
authorList.add(author);
// 创建回答者子文件夹
ZhihuMain.childFilePath = name;
filePath = ZhihuMain.grandFilePath + "/" + ZhihuMain.parentFilePath + "/" + ZhihuMain.childFilePath;
File file = new File(filePath);
file.mkdir();
// Author文本信息写入文件
WriteIntoFile.textInfoFile(filePath, author.writingAuthor());
// 把图片地址放进集合
Elements imgs = list.select("img[src]");
set = getImgUrls(imgs);
// 图片写入文件夹
WriteIntoFile.imgIntoFile(filePath, set);
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static Set<String> getImgUrls(Elements imgs) {
Set<String> set = new HashSet<String>();
for (Element e : imgs) {
String imgUrl = e.attr("src");
if(imgUrl.endsWith("whitedot.jpg") || imgUrl.endsWith(".com"))
continue;
if(imgUrl.length()-imgUrl.lastIndexOf(".")>4)
continue;
set.add(imgUrl);
}
return set;
}
// 格式化
public String WritingZhihu() {
String result = "";
result += "\r\n问题:" + questionHeader + "\r\n\r\n问题描述:" + questionDescription + "\r\n\r\n问题链接:" + zhihuURL
+ "\r\n\r\n";
return result;
}
}/*
* 回答者信息类
*/
public class Author {
private String name; //名字
private String personalDetail; //个人签名
private String agreement; //点赞数
private String personURL; //个人主页
private String answer; //回答内容
public Author(){};
public Author(String name,String personalDetail, String agreement, String personURL,String answer) {
this.name = name;
this.personalDetail = personalDetail;
this.agreement = agreement;
this.personURL = personURL;
this.answer = answer;
}
public String writingAuthor(){
String result = "";
result +="\r\n用户名:"+name+"\r\n签名:"+personalDetail+"\r\n赞同数:"+agreement
+ "\r\n个人主页:"+personURL+"\r\n回答:"+answer+"\r\n";
return result;
}
}
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.Set;
public class WriteIntoFile {
//这里用的是jdk的net中自带的类
//写入图片
public static void imgIntoFile(String filePath,Set<String> set){
InputStream input = null;
OutputStream output = null;
File file = new File(filePath);
int count = 1;
try{
if(set.size()!=0){
Iterator<String> it = set.iterator();
while(it.hasNext()){
//1.获取网址
String url = it.next();
URL u = new URL(url);//记得要完整的URL,https://不能少
//2.打开连接
URLConnection connection = u.openConnection();
//3.获得输入流
input = connection.getInputStream();
//4.判断文件夹是否存在
if(!file.exists()){
file.mkdir();
}
//5.写入操作
byte[]b = new byte[2048];
int len = 0;
output = new FileOutputStream(new File(filePath+"/"+count+url.substring(url.lastIndexOf("."))));
while((len = input.read(b))!=-1){
output.write(b, 0, len);
}
count++;
}
}
}catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭I/o
try {
if (output != null)
output.close();
if (input != null)
input.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//写入author数据的
public static void textInfoFile(String filePath,String content){
BufferedWriter bufr = null;
File file = new File(filePath);
try {
if(!file.exists()){
file.mkdir();
}
bufr = new BufferedWriter(new FileWriter(new File(filePath+"/"+file.getName()+".txt")));
bufr.write(content);
} catch (IOException e) {
e.printStackTrace();
}finally{
if(bufr!=null){
try {
bufr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









