







docker-compose搭建集群
Kafka集群
以下environment中配置不解,可以查看Kafka官方配置详解
docker-compose.yml配置文件
version: '2'
# 以下192.168.0.103为docker所在宿主机,临时ip
services:
zoo1:
image: wurstmeister/zookeeper
restart: unless-stopped
hostname: zoo1
ports:
- "2181:2181"
container_name: zookeeper
# kafka version: 1.1.0
# scala version: 2.12
kafka1:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.0.103 # 这里为宿主机host name
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 0 #broker的全局唯一编号,不能重复
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.0.103:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zoo1
container_name: kafka1
kafka2:
image: wurstmeister/kafka
ports:
- "9093:9093"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.0.103 # 这里为宿主机host name
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_BROKER_ID: 1
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.0.103:9093
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zoo1
container_name: kafka2
kafka3:
image: wurstmeister/kafka
ports:
- "9094:9094"
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.0.103 # 这里为宿主机host name
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.0.103:9094
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9094
KAFKA_BROKER_ID: 2
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zoo1
container_name: kafka3
kafka-manager:
image: hlebalbau/kafka-manager
restart: unless-stopped
ports:
- "10085:9000"
environment:
ZK_HOSTS: "zoo1:2181"
APPLICATION_SECRET: "random-secret"
KAFKA_MANAGER_AUTH_ENABLED: "true"
KAFKA_MANAGER_USERNAME: "root"
KAFKA_MANAGER_PASSWORD: "testpass"
depends_on:
- zoo1
container_name: kafka-manager
command: -Dpidfile.path=/dev/null
然后在配置文件所在目录运行:
docker-compose up -d
创建完如下:

创建topic并配置分区、副本
进入Kafka1容器
docker exec -it kafka1 bash
进入目录/opt/kafka_2.12-2.4.1/bin,创建topic
kafka-topics.sh --create --zookeeper 192.168.0.103:2181 --replication-factor 3 --partitions 3 --topic threePartionTopic
查看topic信息
kafka-topics.sh --describe --zookeeper 192.168.0.103:2181 --topic threePartionTopic
topic如下:

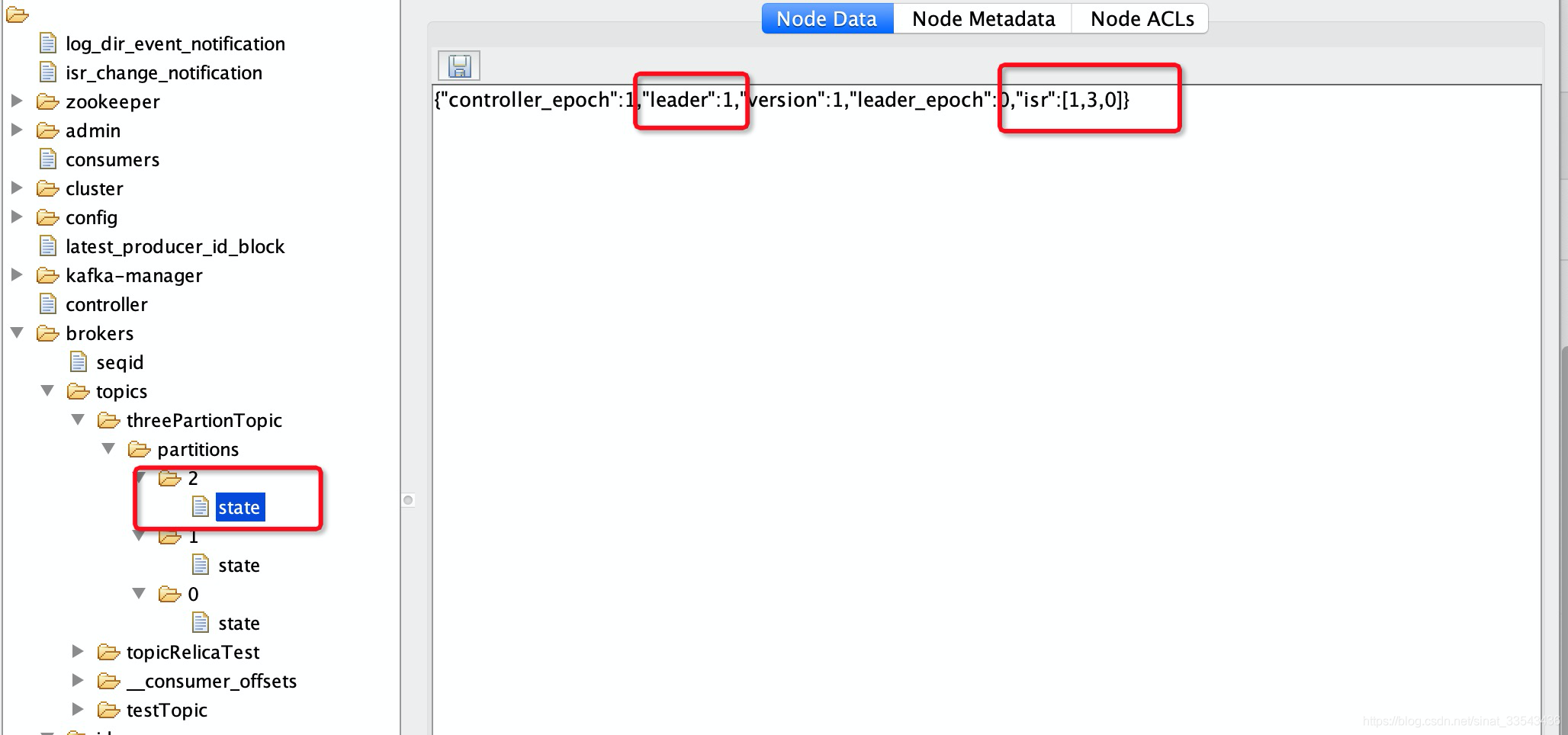
(注:至于ISR为什么是013 不是012 是因为我一开始本地配置文件写错了,写这篇文章还是按012<指的是配置文件中KAFKA_BROKER_ID配置>)
顺便看下zookeeper中topic文件目录信息(用的ZooInspector.jar,网上搜下吧):
代码应用
Kafka官方使用API,里面有Producer API和Consumer API,引入pom
生产者代码如下:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.Random;
public class KafkaProducing {
public static String server = "127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094";
public static String topic = "threePartionTopic";//定义主题
public static void main(String[] args) throws InterruptedException {
Properties p = new Properties();
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);//kafka地址,多个地址用逗号分割
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(p);
try {
while (true) {
String msg = "Hello," + new Random().nextInt(100) + "; tomorrow will be better";
//ProducerRecord的构造参数有:String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers
// 当partition有效指定,按照它来;没有指定,但是指定了key,对key进行hash运算,按运算结果来;没有partition也没有key,则轮训发给所有partition
//这里没有指定key
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg);
kafkaProducer.send(record);
System.out.println("消息发送成功:" + msg);
Thread.sleep(2000);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaProducer.close();
}
}
}
针对上面说的partition,在ProducerRecord的代码注释
If a valid partition number is specified that partition will be used when sending the record. If no partition is specified but a key is present a partition will be chosen using a hash of the key. If neither key nor partition is present a partition will be assigned in a round-robin fashion.
消费者代码如下:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsuming {
public static void main(String[] args) {
Properties p = new Properties();
p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProducing.server);
p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
p.put(ConsumerConfig.GROUP_ID_CONFIG, "terrible_virus");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(p);
kafkaConsumer.subscribe(Collections.singletonList(KafkaProducing.topic));// 订阅消息
while (true) {
try {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("topic:%s,offset:%d,消息:%s, key:%s, partition:%s", //
record.topic(), record.offset(), record.value(), record.key(), record.partition()));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
生产者运行效果图:

消费者端消费图:

参考
https://blog.csdn.net/lblblblblzdx/article/details/80548294
https://juejin.im/post/5c52aaef6fb9a049a7123e1b














 5306
5306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









