







爬取网页信息必须清楚网页结构,今天分析网页的两种访问方式get和post
关于两种访问方式,具体参见:—HTTP 方法:GET 对比 POST—
认识get与post
两种 HTTP 请求方法:GET 和 POST
在客户机和服务器之间进行请求-响应时,两种最常被用到的方法是:GET 和 POST。
GET - 从指定的资源请求数据。
POST - 向指定的资源提交要被处理的数据
在浏览器访问网页的时候可以使用F12访问网页源码,便于调试。我们可以再次调试模式下看到网页结构。
我们以有道翻译为例,在有道翻译官网翻译“中华人民共和国”:
get
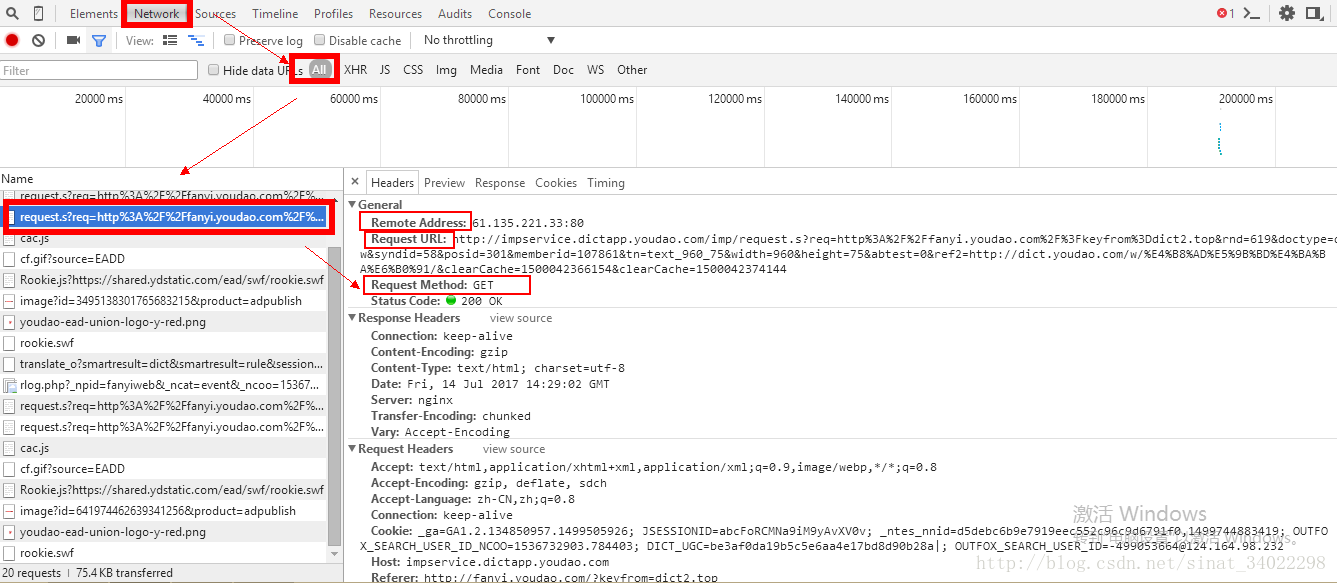
上图中可以看到,服务器给我们传递过来的信息,包括ip地址及访问的网址。
post
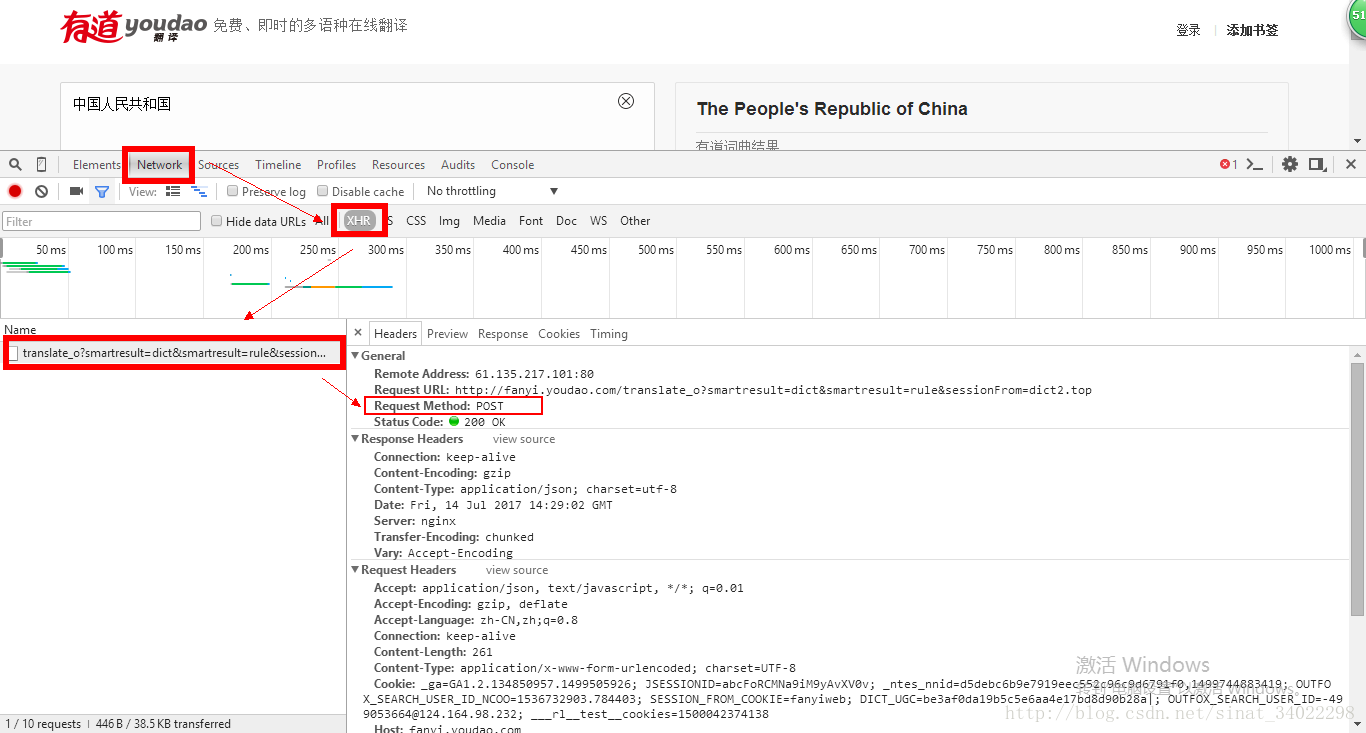
post Form Data
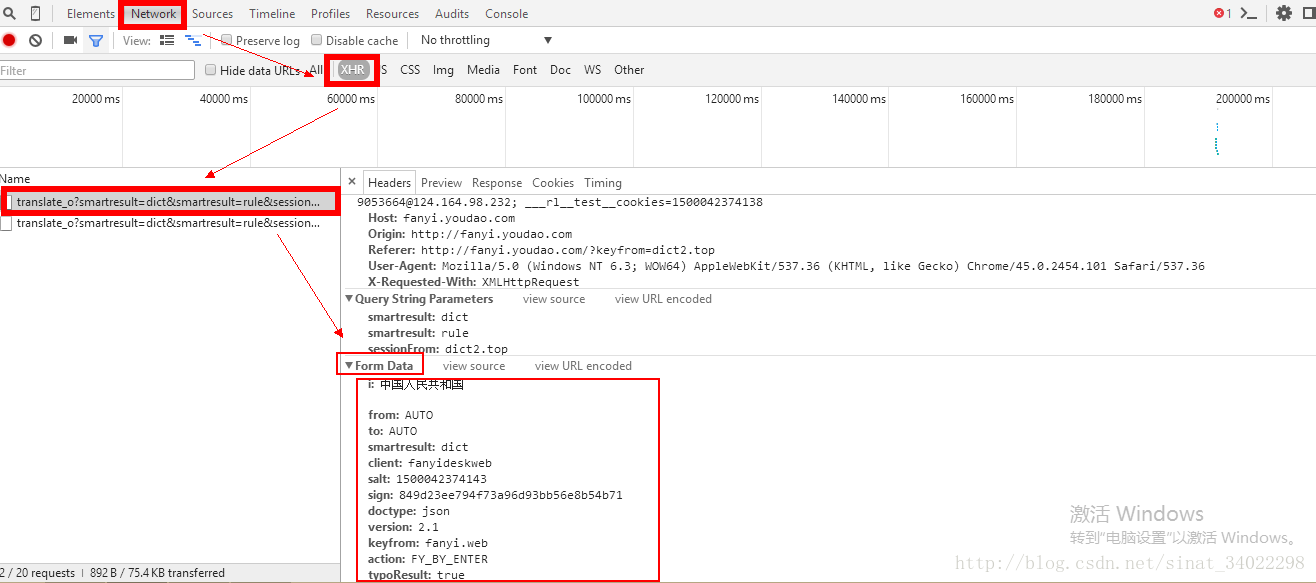
Form Data是用户提交给服务器的数据,从中可以看到我们输入的带翻译内容:中华人民共和国
post User-Agent
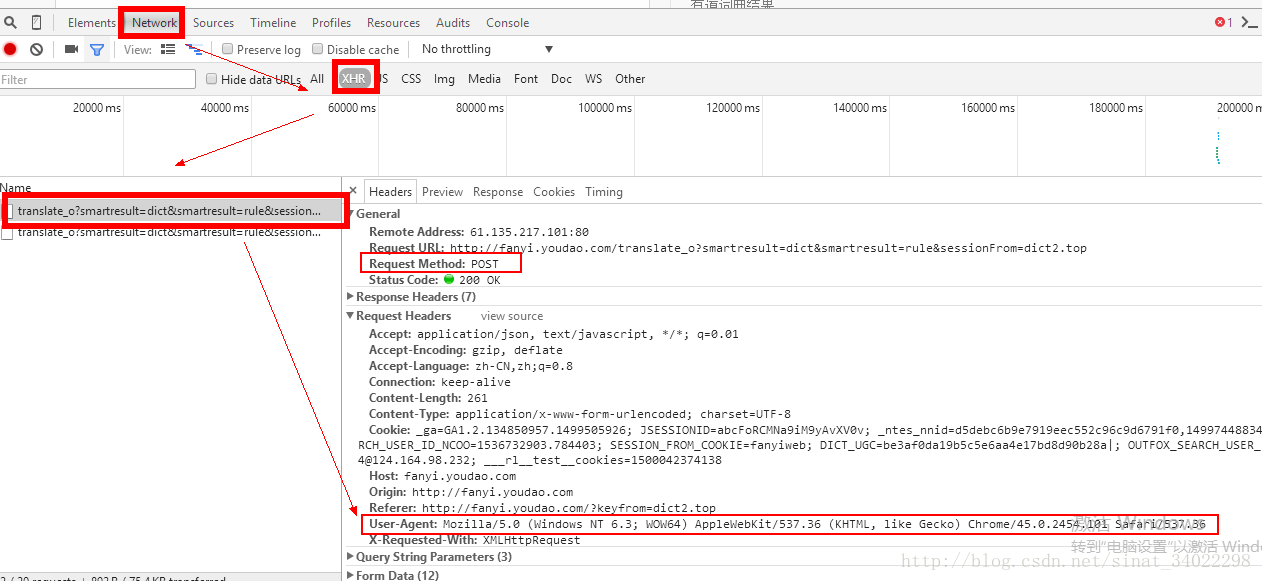
这个是用户身份的验证,这里信息为浏览器信息,如果用python语言编写爬虫,则User-Agent内容为:Python+版本号,所有伪装身份可以改变User-Agent信息。
python 连接有道翻译
import urllib.request
import urllib.parse
import json
content = input('请输入需要翻译的内容:')
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc'
data = {}
# 输入data数据,来自post网页的Form data
data['i'] = content
data['type'] = 'AUTO'
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'utf-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
# 对data内容进行编码(unicode -> utf-8)
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
# html是json格式的str,使用json.loads 转换为dict
html = response.read().decode('utf-8')
target = json.loads(html)
# print(html)
# print(type(target))
# print(target)
# print(target['translateResult'])
# print(target['translateResult'][0][0])
src = target['translateResult'][0][0]['src']
res = target['translateResult'][0][0]['tgt']
print('需要翻译的内容:'+content )
print('翻译结果:%s' %res)
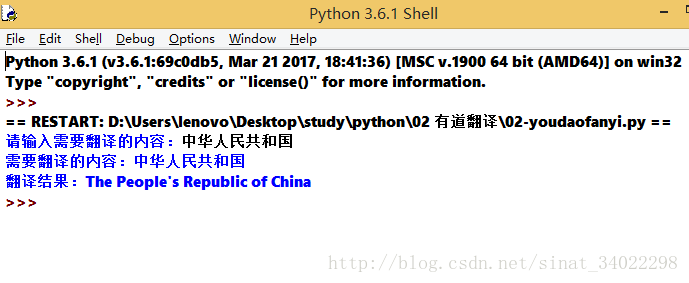
运行结果:














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









