可以使用GET发送_analyze命令,指定分析器和需要分析的文本内容 标准分析器,按照最小粒度 GET _analyze
{
"analyzer" : "standard" ,
"text" : [ "中国人ABC" ]
}
{
"tokens" : [
{
"token" : "中" ,
"start_offset" : 0 ,
"end_offset" : 1 ,
"type" : "<IDEOGRAPHIC>" ,
"position" : 0
} ,
{
"token" : "国" ,
"start_offset" : 1 ,
"end_offset" : 2 ,
"type" : "<IDEOGRAPHIC>" ,
"position" : 1
} ,
{
"token" : "人" ,
"start_offset" : 2 ,
"end_offset" : 3 ,
"type" : "<IDEOGRAPHIC>" ,
"position" : 2
} ,
{
"token" : "abc" ,
"start_offset" : 3 ,
"end_offset" : 6 ,
"type" : "<ALPHANUM>" ,
"position" : 3
}
]
}
作为关键词,关键词不会拆分 GET _analyze
{
"analyzer" : "keyword" ,
"text" : [ "中国人ABC" ]
}
{
"tokens" : [
{
"token" : "中国人ABC" ,
"start_offset" : 0 ,
"end_offset" : 6 ,
"type" : "word" ,
"position" : 0
}
]
}
IK分词器提供两个分词算法:ik_smart、ik_max_word
ik_smart:最少拆分 ik_max_word:最为细粒度切分 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases 注意事项:版本一定要和ES版本一致 解压ik分词器到es/plugins 中,文件夹名称用ik
重启Elasticsearch,安装完成,在界面启动时将会有插件加载信息
可以通过_analyze来测试分词器的使用 GET _analyze
{
"analyzer" : "分词器类型" ,
"text" : "我是中国人码坐标"
}
GET _analyze
{
"analyzer" : "ik_max_word" ,
"text" : "我是中国人码坐标"
}
{
"tokens" : [
{
"token" : "我" ,
"start_offset" : 0 ,
"end_offset" : 1 ,
"type" : "CN_CHAR" ,
"position" : 0
} ,
{
"token" : "是" ,
"start_offset" : 1 ,
"end_offset" : 2 ,
"type" : "CN_CHAR" ,
"position" : 1
} ,
{
"token" : "中国人" ,
"start_offset" : 2 ,
"end_offset" : 5 ,
"type" : "CN_WORD" ,
"position" : 2
} ,
{
"token" : "码" ,
"start_offset" : 5 ,
"end_offset" : 6 ,
"type" : "CN_CHAR" ,
"position" : 3
} ,
{
"token" : "坐标" ,
"start_offset" : 6 ,
"end_offset" : 8 ,
"type" : "CN_WORD" ,
"position" : 4
}
]
}
GET _analyze
{
"analyzer" : "ik_max_word" ,
"text" : "我是中国人码坐标"
}
{
"tokens" : [
{
"token" : "我" ,
"start_offset" : 0 ,
"end_offset" : 1 ,
"type" : "CN_CHAR" ,
"position" : 0
} ,
{
"token" : "是" ,
"start_offset" : 1 ,
"end_offset" : 2 ,
"type" : "CN_CHAR" ,
"position" : 1
} ,
{
"token" : "中国人" ,
"start_offset" : 2 ,
"end_offset" : 5 ,
"type" : "CN_WORD" ,
"position" : 2
} ,
{
"token" : "中国" ,
"start_offset" : 2 ,
"end_offset" : 4 ,
"type" : "CN_WORD" ,
"position" : 3
} ,
{
"token" : "国人" ,
"start_offset" : 3 ,
"end_offset" : 5 ,
"type" : "CN_WORD" ,
"position" : 4
} ,
{
"token" : "码" ,
"start_offset" : 5 ,
"end_offset" : 6 ,
"type" : "CN_CHAR" ,
"position" : 5
} ,
{
"token" : "坐标" ,
"start_offset" : 6 ,
"end_offset" : 8 ,
"type" : "CN_WORD" ,
"position" : 6
}
]
}
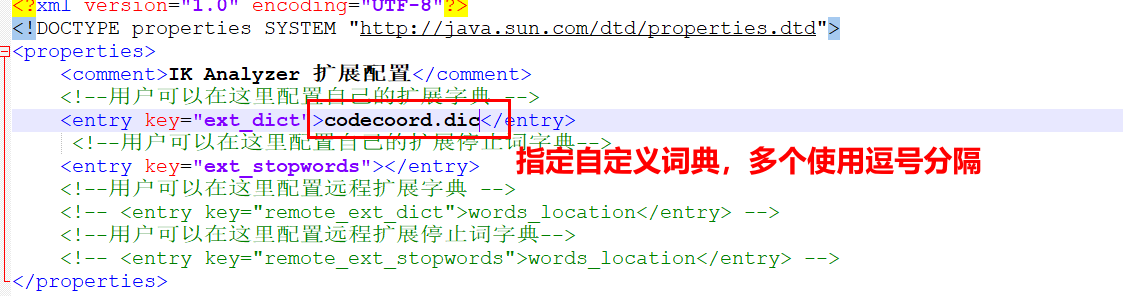
在elasticsearch/plugins/ik/config 下新建.dic文件,例如此处为codecoord.dic 编辑codecoord.dic文件,在其中加入词典,加入的信息在分词器中将会作为一个词语使用,不会进行拆分
编辑ik/config/IKAnalyzer.cfg.xml文件,在ext_dict中加入刚刚创建的codecoord.dic词典,多个使用逗号分开
此时进行分词器的使用,将会作为一个词语显示 {
"tokens" : [
{
"token" : "我" ,
"start_offset" : 0 ,
"end_offset" : 1 ,
"type" : "CN_CHAR" ,
"position" : 0
} ,
{
"token" : "是" ,
"start_offset" : 1 ,
"end_offset" : 2 ,
"type" : "CN_CHAR" ,
"position" : 1
} ,
{
"token" : "中国人" ,
"start_offset" : 2 ,
"end_offset" : 5 ,
"type" : "CN_WORD" ,
"position" : 2
} ,
{
"token" : "码坐标" ,
"start_offset" : 5 ,
"end_offset" : 8 ,
"type" : "CN_CHAR" ,
"position" : 3
} ,
{
"token" : "坐标" ,
"start_offset" : 6 ,
"end_offset" : 8 ,
"type" : "CN_WORD" ,
"position" : 4
}
]
}
创建索引并指定分析器 PUT index
{
"mappings" : {
"properties" : {
"content" : {
"type" : "text" ,
"analyzer" : "ik_max_word" ,
"search_analyzer" : "ik_smart"
}
}
}
}
创建文档 POST index/ _doc/ 1
{
"content" : "美国留给伊拉克的是个烂摊子吗"
}
POST index/ _doc/ 2
{
"content" : "公安部:各地校车将享最高路权"
}
POST index/ _doc/ 3
{
"content" : "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
}
POST index/ _doc/ 4
{
"content" : "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
搜索时指定高亮信息 GET index/ _search
{
"query" : {
"match" : {
"content" : "中国"
}
} ,
"highlight" : {
"pre_tags" : [ "<tag1>" , "<tag2>" ] ,
"post_tags" : [ "</tag1>" , "</tag2>" ] ,
"fields" : {
"content" : { }
}
}
}
将会在高亮highlight 中返回高亮信息 {
"took" : 50 ,
"timed_out" : false ,
"_shards" : {
"total" : 1 ,
"successful" : 1 ,
"skipped" : 0 ,
"failed" : 0
} ,
"hits" : {
"total" : {
"value" : 2 ,
"relation" : "eq"
} ,
"max_score" : 0.642793 ,
"hits" : [
{
"_index" : "index" ,
"_type" : "_doc" ,
"_id" : "3" ,
"_score" : 0.642793 ,
"_source" : {
"content" : "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
} ,
"highlight" : {
"content" : [
"中韩渔警冲突调查:韩警平均每天扣1艘<tag1>中国</tag1>渔船"
]
}
} ,
{
"_index" : "index" ,
"_type" : "_doc" ,
"_id" : "4" ,
"_score" : 0.642793 ,
"_source" : {
"content" : "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
} ,
"highlight" : {
"content" : [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
]
}
}
]
}
}
























 9493
9493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









