









目标:分布式爬取起点小说X类型小说前X页的所有小说
power by:
- Python 3.6
- Scrapy 1.4
- pymysql
- scrapy-redis
- redis 3.6
- macOS 10.12.6
- Ubuntu 16.04.2
Setp 1——相关介绍
我们将上次的Scrapy爬虫升级成分布式,额外需要scrapy-redis和redis
redis的主要作用是存储request,去重,分发。就是说我们的爬虫不再自己管理request,
只管从redis中拿request并且把新的request给它(给redis主要是为了去重)
项目中主要有两种机器:Master,Slaver
Master:安装redis,不运行代码,只管理request,一台
Slaver:跑爬虫的机器,多台,只要机器配置好需要的Python环境复制代码过去就可以工作
Step 2——安装和配置
首先安装scrapy-redis
pip install scrapy-redis
然后我们安装redis,本例安装在服务器上
apt-get update
apt-get install redis-server
redis默认不能远程访问,改一下配置文件
vim /etc/redis/redis.conf
注释掉下面语句
bind 127.0.0.1
注释掉之后已经可以远程访问,不过这样redis是所有人都可以访问的,所以为了安全我们加上密码。
将下面语句的#删除,foobared改成自己的密码
#requirepass foobared
重启redis
service redis restart
Step 3——修改setting.py
添加下列语句
# setting.py
#scrapy-redis的去重组件.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# scrapy-redis的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 允许暂停后,能保存进度
SCHEDULER_PERSIST = True
# 指定排序爬取地址时使用的队列,默认优先队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
ITEM_PIPELINES = {
'QiDian.pipelines.QiDianPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400
}
REDIS_HOST = 'YOUR IP'
REDIS_PORT = 6379
REDIS_PARAMS = {}
REDIS_PARAMS['password'] = 'YOURPASS'
Step 4——修改QiDianNovelSpider.py
# QiDianNovelSpider.py
from QiDian.items import QiDianNovelItem
from scrapy_redis.spiders import RedisSpider
import re
import scrapy
# 由从spider继承改为RedisSpider
class QiDianNovelSpider(RedisSpider):
# 删除start_urls函数,因为爬虫将从redis里获取start_url
# redis_key作为爬虫从redis数据库里获取request的key
redis_key = 'QiDianNovelSpider:start_urls'
name = 'qi_dian_novel_spider'
url = 'https://www.qidian.com/free/all?chanId=21&orderId=&vip=hidden&' \
'style=1&pageSize=20&siteid=1&hiddenField=1&page=%d'
def parse(self, response):
item = QiDianNovelItem()
novels = response.xpath('//ul[@class="all-img-list cf"]/li/div[@class="book-mid-info"]')
# 爬取当前页的下一页,爬虫理论上不会停止
page = int(re.search(r'page=(\d+)', response.url)[1])
yield scrapy.Request(self.url % (page + 1))
for novel in novels:
item['name'] = novel.xpath('.//h4/a/text()').extract()[0]
item['author'] = novel.xpath('.//p[@class="author"]/a[1]/text()').extract()[0]
item['intro'] = novel.xpath('.//p[@class="intro"]/text()').extract()[0]
yield item
Step 5——启动爬虫
进入到项目的spiders文件夹内
scrapy runspider QiDianNovelSpider.py
此时爬虫处于监听状态:
服务器方面:
redis-cli -a YOURPASS
lpush QiDianNovelSpider:start_urls YOUR-URL
# 爬虫运行完后执行,不然影响下次爬虫的运行
flushdb
停止爬虫可使用Ctrl + C
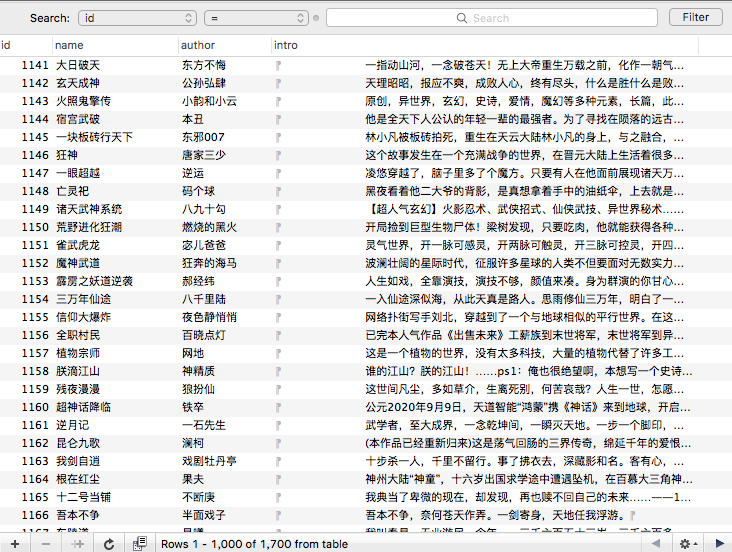
###成果展示:
















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









