









 Kademlia是一种分布式存储和路由算法,用于IPFS星际文件系统中身份生成和文件的存储查找。节点ID由SHA1哈希计算得出,通过异或距离计算节点间的距离,实现高效查找。文件的存储基于节点ID与文件哈希的对应,查找过程通过逐级缩小搜索范围的策略,最多只需log2N次查询。Kademlia协议还提升了物联网设备通讯的安全性。
Kademlia是一种分布式存储和路由算法,用于IPFS星际文件系统中身份生成和文件的存储查找。节点ID由SHA1哈希计算得出,通过异或距离计算节点间的距离,实现高效查找。文件的存储基于节点ID与文件哈希的对应,查找过程通过逐级缩小搜索范围的策略,最多只需log2N次查询。Kademlia协议还提升了物联网设备通讯的安全性。
IPFS星际文件系统之身份的生成——>S/Kademlia协议
Kademlia是一种分布式存储及路由算法。什么是分布式存储?
- 试想一下,一所1000人的学校,现在学校突然决定拆掉图书馆(不设立中心化的服务器),将图书馆里所有的书都分发到每位学生手上(所有的文件分散存储在各个节点上)。即是所有的学生,共同组成了一个分布式的图书馆。
那么,有两个问题:
- 如何将需要存储的内容分配到各个节点?<存储>
- 一个节点如果想获取某个文件,如何找到存储文件的节点/地址?<查找>
额额额,暂且先简单了解一下节点这个东西~
节点的属性:
- Node ID,2进制,160位;
- 节点的IP地址及端口;
每个节点需要维护的内容:
- 被分配到需要存储的内容(内容以<key,value>对的形式存储,可以理解为文件名和文件内容);
- 一个路由表,称为K-bucket(按Node ID分层,记录有限个数的其他节点的ID和IP地址&端口);
Kademlia 中使用 SHA1 哈希来计算 Node ID,SHA1 是一个 160 bit 的哈希空间,整个 ID 长度是 160
个位, 也就是 20 个字节。
接下来进入正题->
文件的存储和查找
存储
- 选择一个唯一的随机数作为节点ID;
- 节点ID与文件散列直接对应,即一个文件的散列值如果等于某个节点ID,这个文件就会被存储在该节点上;(有点迷,这样的话岂不是一个节点只能存储一个文件的相关信息了吗???)
Wikipedia
- Kademlia基于两个节点之间的距离计算,该距离是两个网络节点ID号的异或( XOR distance ),计算的结果最终作为整型数值返回。关键字和节点ID有同样的格式和长度,因此,可以使用同样的方法计算关键字和节点ID之间的距离。节点ID一般是一个大的随机数,选择该数的时候所追求的一个目标就是它的唯一性(希望在整个网络中该节点ID是唯一的)。异或距离跟实际上的地理位置没有任何关系,只与ID相关。因此很可能来自德国和澳大利亚的节点由于选择了相似的随机ID而成为邻居。
- 选择异或是因为通过它计算的距离享有几何距离公式的一些特征,尤其体现在以下几点:节点和它本身之间的异或距离是0;异或距离是对称的:即从A到B的异或距离与从B到A的异或距离是等同的;异或距离符合三角不等式:三个顶点A B C,AC异或距离小于或等于AB异或距离和BC异或距离之和。由于以上的这些属性,在实际的节点距离的度量过程中计算量将大大降低。
- Kademlia搜索的每一次迭代将距目标至少更近1 bit。一个基本的具有2^n个节点的Kademlia网络在最坏的情况下只需花n步就可找到被搜索的节点或值(复杂度log2n)。
查找
由于一个节点的路由表只有部分路由信息,很可能没有目标节点的IP地址,那么如何联系上目标节点呢?
一个可行的思路:
当知道目标节点D与当前节点之间的距离后,就可以在当前节点的路由表里先找到一个与D最相近的节点B,让B再进一步去查找D的IP地址。
路由表是如何按距离分层的?
------按异或距离分层,基本上可以理解为按bit(位数)分层。如下:
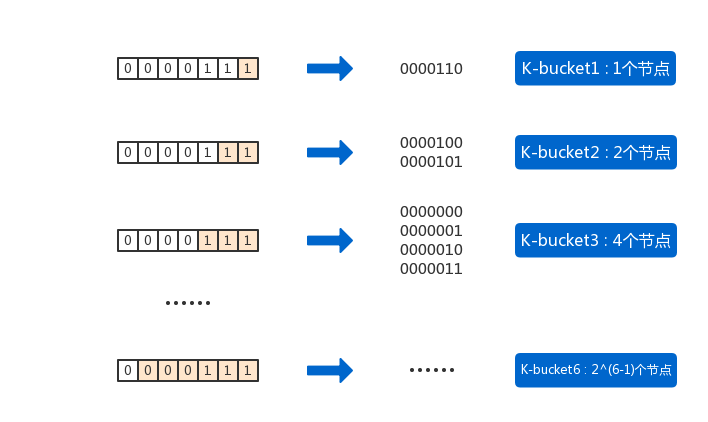
<就7位吧>以0000110为基础节点:
- 如果一个节点,前面所有位都与它相同,只有最后1位不同,这样的节点有1个——0000111,与基础节点的异或距离为1;对于0000110而言,这样的节点归为“ k-bucket 1 ” ;
- 如果一个节点,前面所有位都与它相同,从倒数第2位开始不同,这样的节点有2个——0000100、0000101,与基础节点的异或距离范围为2、3;对于0000110而言,这样的节点归为“ k-bucket 2 ”;
- …
- 如果一个节点,前面所有位都与它相同,从倒数第 i 位开始不同,这样的节点有2i-1个,与基础节点的异或距离范围为[2i-1,2i);对于0000110而言,这样的节点归为“ k-bucket i ” ;
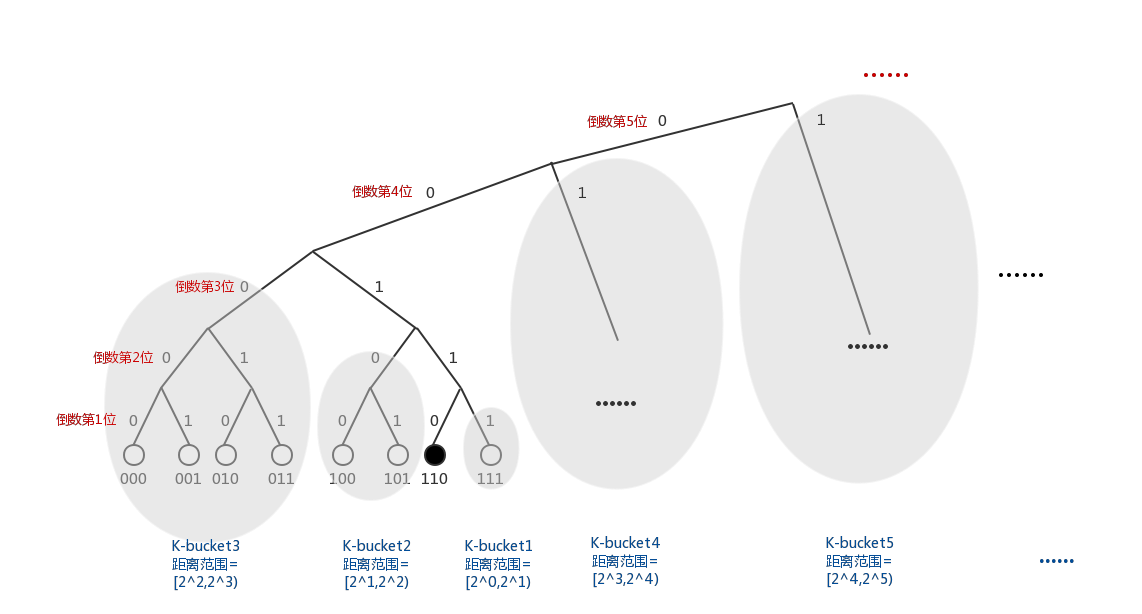
以上描述可用二叉树表示:如果将整个网络的节点梳理为一个按节点ID排列的二叉树,树最末端的叶子便是一个节点。
二叉树表示法也能更直观地展现出节点之间的距离关系,如下图所示(感觉网上的二叉树都是反的,em?):
现在我们来阐述一个完整的查找流程:
节点A 00000110要访问的文件的hash值为00010000,于是向节点B 00010000请求数据。
节点A、B之间的异或距离为00010110,从倒数第5位开始不同,距离范围在[24, 25),所以节点B可能在K-bucket5中。
接下来,节点A就找找自己的K-bucket5中有没有B节点:
- 如果有,那就直接访问B节点;
- 如果没有,就在K-bucket5中任意找一个节点X(注意:任意X节点,它的倒数第五位肯定与B相同,即它与B节点的距离会小于24,相比于A、B之间的距离缩短了至少一半),请求节点X在它自己的路由表里按同样的方式查找B节点:
1)如果X知道B节点,那就把B节点的IP地址告诉节点A;
2)如果X也不知道B节点,那X按同样的搜索方法,在自己的路由表里找到一个离B节点更近的节点Y(Y、B之间的距离小于23),把节点Y推荐给节点A;A请求Y进行下一步查找。
Kademlia的这种查询机制,像是将一张纸不断地对折来收缩搜索范围,对于任意N个节点,最多只需要查询log2N次,即可找到目标节点。
总结
Kademlia是一种通过分布式散列表(DHT)实现的协议算法,它是由Petar和David为非集中式P2P计算机网络而设计的。在这类系统中,每个节点(node)分别维护一部分的存储内容以及其他节点的路由/地址,使得网络中任何参与者(即节点)发生变更(进入/退出)时,对整个网络造成的影响最小。
Kademlia作为一种高效的分布式路由算法,还可以应用在分布式网络中的安全通讯。众享互联的分布式网络安全解决方案,将单点对单点的信息传输方式改为在多节点的分布式网络中多路径传输。采用Kademlia这种DHT算法,使得物联网设备的通讯信息在分布式网络中能够更快更准确地到达目标设备,并并大大提高了网络攻击者彻底阻断通讯路径的难度,令物联网设备通讯的安全性极大地提高。
参见:
https://www.jianshu.com/p/f2c31e632f1d
https://zh.wikipedia.org/wiki/Kademlia

















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









