








Each RNA Xi in an RNA sequence X is an observative variable and each label yi in a label sequence y is the hidden variable. First a Bi-LSTM neural network takes as input X and generates emission probability P (Pi,yi is the emission probability that RNA Xi is tagged with label yi) of y. Then we use the hidden state transition matrix A (Ayi,yi+1 is the transition probability from hidden state yi to yi+1), which is the learnable parameter of CRF layer, to get the transition probability. This hidden state transition matrix is initialized randomly and is updated using back propagation. We define the score for the label sequence y of an RNA sequence X as below:
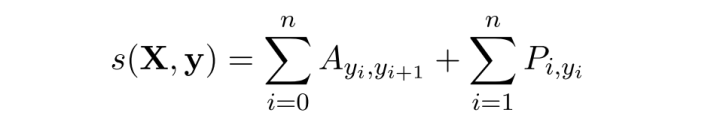
Use Softmax to calculate the probability of all possible label sequences, even some may never
appear and below is the probability of the correct label sequence
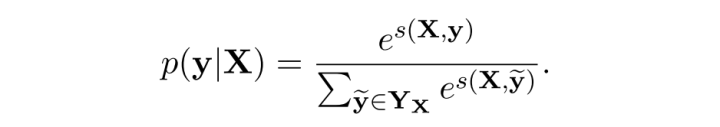
Log it then we can get
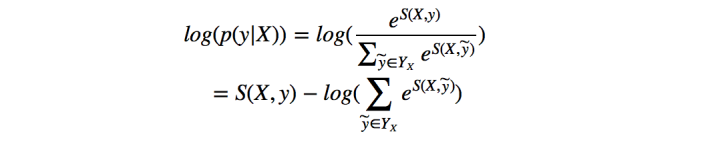
Take the opposite as the loss function so we can use gradient descent to train our model. When training model, instead of giving accurate prediction in each position, we just use the probability distribution generated by Bi-LSTM to calculate the loss. We use a particular function to do this. After we finish training, this function is no more need. To predict the label sequence of a new RNA sequence, we put this RNA sequence into Bi-LSTM and get the probability distribution. Then we use Viterbi algorithm which takes as parameters the probability distribution and learned transition matrix A to calculate the best path and the best path is what we need.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









