









概述
布隆过滤器(Bloom Filter)是布隆在1970年提出的,它可以用来检索一个元素是否在一个集合中。实际上布隆过滤器通过一个二进制向量和一系列随机哈希函数完成元素检索,其优点在于比一般的算法具有更高的时间效率和空间效率,但其缺点是有一定的误差以及难以进行删除操作。
原理
布隆过滤器的核心就是哈希函数,可以将其看作是对 bitmap 的拓展,通过将添加的元素经过 k 个哈希函数映射到一个很长的 bit 向量中的 k 个位置,并将它们置为 1。检索时,通过判断这个位置是否都为 1 就能大概知道集合中是否存在查询的元素。具体规则是:
- 如果这些位置中有任何一个位置为 0,那么被检索的元素一定不在;
- 如果这些位置都是 1,那么被检索的元素可能存在。
为什么会有上面两条规则存在不同的确定性呢?这里举一个简单的例子:假设现在有一个 8 bits 的二进制空间作为布隆过滤器,然后我们插入 3 和 5 这两个十进制数,哈希函数就选取简单的十进制转二进制,即插入 011 和 101,此时二进制空间的数据则为 00000111。
如果此时我们在布隆过滤器中检索 3 和 5 两个十进制数,则可以认为他们可能存在。检索十进制数 9,对应二进制为 1001,则判定为不存在,这个结果是必然的。但如果我们检索 7 这个十进制数,由于它的二进制表示为 0111,因此会被误判为存在。所以才会出现上述的规则,而且随着插入元素数量的增加,出现误判的概率也会上升,因此布隆过滤器不适用于对精确度要求高的应用场合。
优点
布隆过滤器的有点体现在多个方面,主要包括:
- 元素插入和查询操作主要都是计算 k 的哈希函数,因此时间复杂度都是常数 O(k),时间效率远高于一般查询算法。
- 哈希函数之间通常没有依赖关系,数据映射的过程可以由硬件并行完成,提高计算效率。
- 不需要存储元素本身,只需要存储映射后的比特位,空间复杂度为 O(m),空间效率极高。
- 不需要存储元素本身,在需要对数据严格保密的场合具有优势。
不足
布隆过滤器的一个明显缺点是,随着插入元素的数量增加,检索出现误差的概率增大。要减少误差,一方面可以考虑减少插入元素的数量,但如果数量太少 ,其实用一般的散列表或者 set 集合就足够了;另一方面可以做一个补救措施,比如创建一个白名单,存储哪些可能被误判的信息,但是如何维护这个表数据的准确性也是一个值得深入研究的问题。
另一个缺点是,一般情况下不能从布隆过滤器中删除元素。通过上面的原理解析可以知道,一个元素不能被准确地被判断确实在布隆过滤器中,而删除该元素对应映射出来的比特位,并不代表删除了这个元素,反而还有可能影响到其他元素映射出来的比特位。所以删除元素这个过程是无法被保证的,在很多布隆过滤器的实现都没有支持删除元素的操作。
总的来说,布隆过滤器通过极少的错误换取了极大的空间效率,但布隆过滤器不适合那些追求“零错误”的场合。
设计思路
过小的布隆过滤器随着插入元素增加,bit 位很快都被置为 1,那么查询任何元素时误判率就是增加。布隆过滤器的长度越大,其误报率就越小。此外,哈希函数个数越多,每个元素插入时置 1 的比特位越多,过滤效率越低;但如果哈希函数太少的话,误报率也会变高。
我们把哈希函数个数记为 k,布隆过滤器长度记为 m,插入元素个数记为 n,误报率为 p。则他们之间满足公式:
m
=
−
n
ln
p
(
ln
2
)
2
k
=
m
n
ln
2
≈
0.7
m
n
m = -\frac{n \ln p}{(\ln 2)^2} \\ k = \frac{m}{n}\ln 2 \approx 0.7\frac{m}{n}
m=−(ln2)2nlnpk=nmln2≈0.7nm
推导过程如下(不感兴趣的可以跳过)
k 次哈希函数计算后某一个 bit 位未被置为 1 的概率为: ( 1 − 1 m ) k (1 - \frac{1}{m})^k (1−m1)k
插入 n 个元素后依旧为 0 的概率: ( 1 − 1 m ) n k (1 - \frac{1}{m})^{nk} (1−m1)nk
插入 n 个元素后为 1 的概率: 1 − ( 1 − 1 m ) n k 1 - (1 - \frac{1}{m})^{nk} 1−(1−m1)nk
插入某个元素将所需的 k 个位置都按照上面的概率置为 1,但这个结果可能会导致某些不在集合中的元素被误判在该集合中,这个事件的概率为:
p
(
k
)
=
[
1
−
(
1
−
1
m
)
n
k
]
k
≈
(
1
−
e
−
k
n
/
m
)
k
p(k) = [1 - (1 - \frac{1}{m})^{nk}]^k \approx (1 - e^{-kn/m})^k
p(k)=[1−(1−m1)nk]k≈(1−e−kn/m)k
给定 m 和 n,通过计算极值可以得到上面的公式
Redis 引入布隆过滤器插件
Redis 自从 4.0 版本后开始支持布隆过滤器的插件,提升了 redis 去重操作的效率。在实际业务中,我们可能需要通过用 redis 来判断某些数据是否存在,过去可以使用 set 集合来做去重。但是如果缓存的数据量非常大,那么就需要遍历所有的缓存数据。而且如果由于缓存内存大小的限制,有些写不下的数据,最终还是要去访问数据库,避免不了这部分 IO 访问,此时就可以考虑使用布隆过滤器进行查询了。
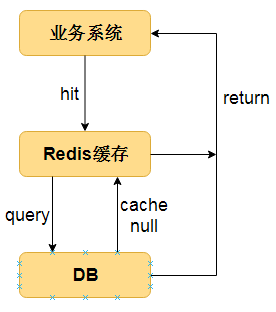
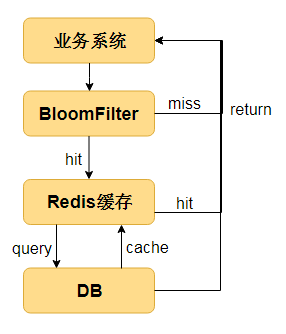
不过正如上面所分析的,布隆过滤器存在一定的误差,如果对精确度要求很高的话,就不建议使用了。布隆过滤器的过滤后的结果表明,判断为存在的数据并不一定存在,但如果判定为不存在的数据,则必然是不存在的了。
相关命令:
bf.add #添加元素
bf.exists #判断元素是否存在
bf.madd #批量添加
bf.mexists #批量判断是否存在
应用场景
- Google著名的分布式数据库 Bigtable 和 Hbase
- 使用布隆过滤器来查找不存在的行或列,以减少磁盘查找的 IO 次数。
- 检查垃圾邮件地址
- Google 浏览器使用布隆过滤器识别恶意链接
- 把每一个 url 映射成一个 bit ,实现小空间存储大数据。
- 文档存储检索系统检测已存储的数据
- 内容推荐
- 网站推荐的内容,可以在历史访问记录中进行检索,可以接受新内容存在很小的概率被认为之前已访问过。
- 爬虫 URL 地址去重
- 爬虫 url 去重通常允许有一定的错误率。
- 解决缓存穿透问题
- 高频访问无法命中缓存的数据或者缓存不存在的数据,会导致数据库被高频的访问,这甚至会成为被黑客攻击的漏洞,导致数据库宕机。














 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









