







背景:
5-6月使用ogg+expdp将两套Oracle 11g从AIX7.1迁移到redhat7.9,数据量接近3T,本文主要记录ogg迁移过程中遇到的问题以及优化方法,希望对读者有所帮助
问题一:OGG数据一致性校验
使用OGG数据迁移,需要面对的一个大问题就是如何进行源端和目标端的数据校验,数据校验可以从表的3个方面进行校验
1 表的列数量是否一致
2 表的行数是否一致
3 表的字段存放数据是否一致,主要通过比较数据的hash值,而受制于查询语句对大字段的操作支持以及数据比较时间,LOB字段以及超过2000的varchar2字段暂时无法进行数据校验,要从校验的数据里面排除
如何校验在线实时同步的数据,由于源库通常是24小时在线的业务系统,加上ogg同步存在的一定延时,在不停源库业务的情况下,源端和目标端在同一个时间点基本是无法做到完全的一致,虽然有些OGG商业软件可以做到对源端和目标端的在线数据校验,但在这种单次的OGG迁移项目以及存在大量不规范的表(表无主键以及没有记录最新的行操作时间)的情况下,很难使用OGG商业软件进行数据校验
所以,我在本次的OGG数据迁移校验计划了两种方案进行在线的数据校验
1 通过shell脚本的方式实现自动对表进行列,行数以及字段数据hash值的比较,并将源端,目标端结果按表进行比对,将不一致的表输出到结果文件,减少人为操作带来的比较时间误差,并在业务的空闲时间执行脚本进行比对,只要表的数据差距控制在10行以内,hash值基本一致,按照OGG的迁移经验,基本就可以确定源端和目标端的表数据一致
2 OGG从源端的备库拉起数据进行同步,在进行数据校验时,暂停备库的日志应用,让备库处于数据静止状态,这时源端和目标端就具备数据完全一致的条件,在进行数据比较,这么做最好是重新从主库在拉一个备库出来或者是备库无业务使用
最终根据当前的迁移环境以及现有资源,我们选择了方案一通过shell脚本方式实现源端和目标端的表自动数据校验
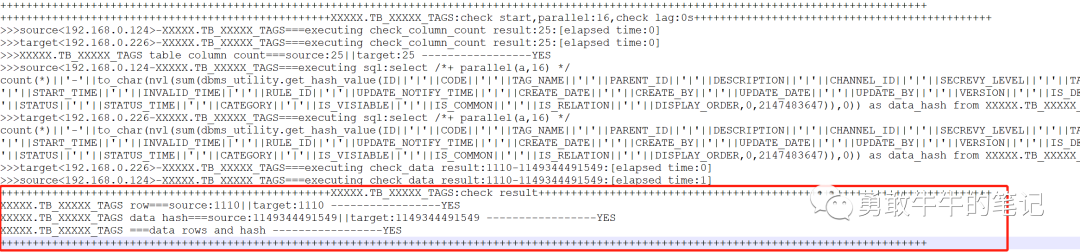
这是脚本实现的输出截图,YES为一致的表,而对于NO不一致的表将会输出到结果文件,通过检查这个结果文件是否有表,就可以确认数据是否一致
问题二:OGG软件版本与操作系统不兼容
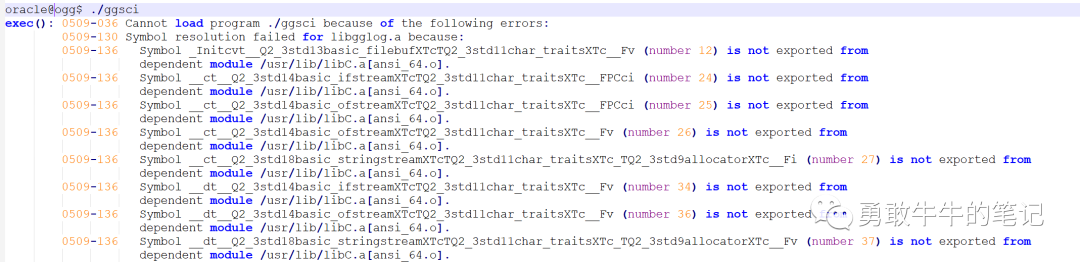
在源端AIX安装ogg191004软件成功后,使用ggsci工具时,出现依赖库包的版本错误,由于操作系统版本与ogg版本不兼容导致,最终使用了ogg 11.2.1.0.32版本才可以
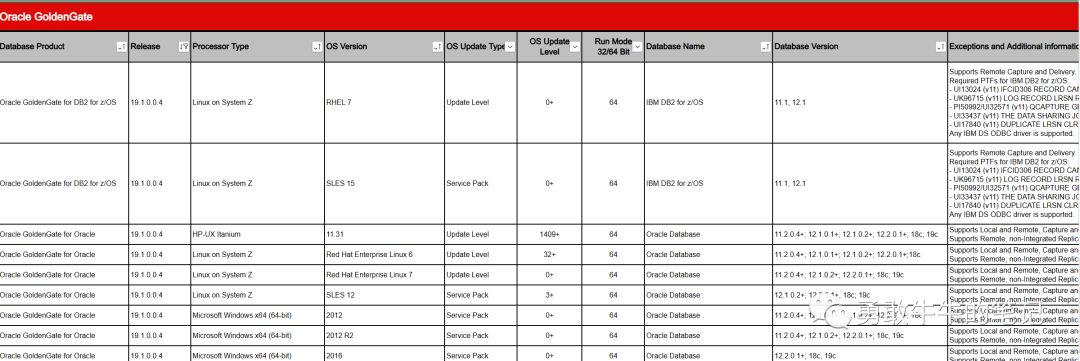
OGG版本的与操作系统的兼容性,可以通过OGG的官方文档查看
https://www.oracle.com/a/ocom/docs/ogg-19c-cert-matrix.xlsx
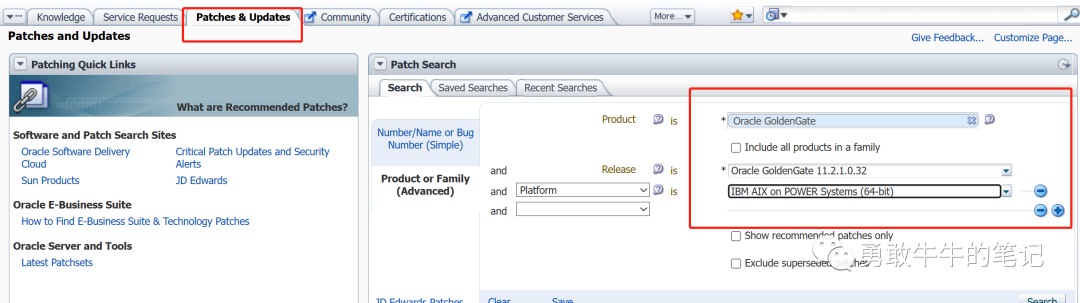
当时下载11G版本的OGG花费了很长时间寻找,最终发现在mos上面可以通过Patches&Updates下载各个OGG版本的安装包补丁,而11.2.1.0.32版本的安装补丁包包含完整的安装软件,直接解压就可以使用,解决了下载问题
问题三:LOB大字段表导出慢
在进行OGG数据初始化的时候,使用expdp导出全量的初始化数据,发现存在大量的LOB大字段表,单个lob字段100G以上,由于expdp无法使用并行对lob字段进行导出,加上lob字段使用的是basicfile的存储导致导出速度缓慢,并且很容易触发lob undo过旧
针对LOB字段导出过慢的问题,采用的优化方式是通过rowid获取行所在的数据块,然后按并行度进行切块多个impdp并行导出,通过这种方式可以大大提升了导出的速度,原来单个lob字段的导出时间从10小时+减少到1小时以内
导出脚本案例
#!/bin/bash
export ORACLE_SID=
#expdp parfile 存放路径
parfile_path=/databackup/source_parfile
#切割的并行度
parallel=16
for_step=$(( ${parallel}-1 ))
#导出表的用户名,表名
table_owner=''
table_name=''
#导出dmp,logfile的日期
current_date=`date "+%Y%m%d"`
#导出的dmp,logfile存放目录
directory='expdpdump'
datapump_path='/databackup/datapump'
nohup_path='/databackup/datapump'
#导出的时间点scn
FLASHBACK_SCN=
i=0
while(($i<${parallel}))
do
parfile="${parfile_path}/e_${table_name}_${current_date}_${i}.par"
dumpfile=${table_name}_${current_date}_${i}.dmp
logfile="e_${table_name}_${current_date}_${i}.log"
if [[ -f ${parfile} ]] || [[ -f ${datapump_path}/${dumpfile} ]] || [[ -f ${datapump_path}/${logfile} ]];then
echo " ${parfile} or ${datapump_path}/${dumpfile} or ${datapump_path}/${logfile} is exist;Please delete and execute again "
exit 0
fi
echo "-----start write parfile:${i}-${parfile}"
echo 'userid="/ as sysdba"'>>${parfile}
echo "directory=${directory}">>${parfile}
echo "dumpfile=${dumpfile}">>${parfile}
echo "FLASHBACK_SCN=${FLASHBACK_SCN}">>${parfile}
echo "TABLES=${table_owner}.${table_name}">>${parfile}
echo "QUERY=${table_owner}.${table_name}:\"where mod(dbms_rowid.rowid_block_number(rowid), ${parallel}) = ${i}\"">>${parfile}
echo "logfile=${logfile} ">>${parfile}
echo "cluster=n">>${parfile}
echo "-----start expdp parallel:${i}"
nohup expdp parfile=${parfile} >${nohup_path}/e_${table_name}_${current_date}_${i}.out &
i=$(($i+1))
sleep 10
done导入脚本案例,注意导入要指定DATA_OPTIONS=DISABLE_APPEND_HINT采用非APPEND导入,采用append导入会出现锁表,导致其他导入进程进行锁等待
#!/bin/bash
export ORACLE_SID=
#impdp parfile 存放路径
parfile_path=/databackup/target_parfile
#导入的并行度,与导出的并行度保持一致
parallel=16
for_step=$(( ${parallel}-1 ))
#导入的用户名,表名
table_owner=''
table_name=''
#导入dmp的日期与导出的dmp日期一致
current_date=''
#导入dmp,logfile的路径
directory='impdpdump'
datapump_path='/databackup/datapump'
nohup_path='/databackup/datapump'
for ((i=0;i<=${for_step};i++));
do
parfile="${parfile_path}/i_${table_name}_${current_date}_${i}.par"
dumpfile=${table_name}_${current_date}_${i}.dmp
logfile="i_${table_name}_${current_date}_${i}.log"
if [[ -f ${parfile} ]] || [[ -f ${datapump_path}/${logfile} ]];then
echo " ${parfile} or ${datapump_path}/${logfile} is exist;Please delete and execute again "
exit 0
fi
if [[ -f ${datapump_path}/${dumpfile} ]];then
echo "-----start write parfile:${i}-${parfile}"
echo 'userid="/ as sysdba"'>>${parfile}
echo "directory=${directory}">>${parfile}
echo "dumpfile=${dumpfile}">>${parfile}
echo "content=data_only">>${parfile}
echo "DATA_OPTIONS=DISABLE_APPEND_HINT">>${parfile}
echo "TABLES=${table_owner}.${table_name}">>${parfile}
echo "logfile=${logfile} ">>${parfile}
echo "cluster=n">>${parfile}
echo "-----start impdp parallel:${i}"
nohup impdp parfile=${parfile} >${nohup_path}/i_${table_name}_${current_date}_${i}.out &
sleep 10
else
echo " ${datapump_path}/${dumpfile} is not exist;"
exit 0
fi
done问题四:非LOB字段表导出慢
同样是在做数据导出的时候,出现一个小于10G的没有LOB的表导出异常慢接近2个小时,后面分析是表是宽表存在大量的行链接触发了Bug 17293498 - BAD EXPDP PERFORMANCE WITH ACCESS_METHOD=DIRECT_PATH + CHAINED ROWS,最后对单表expdp采用access_method=external_table方式,expdp通过映射外部表从SQL层导出的方式规避了该问题,导出时间从2小时缩短至28分钟
问题五:用户统计信息收集过慢
在进行用户统计信息收集时,发现用户统计信息收集的时间过长,即使使用了大量的并行速度依然提升不明显,这是因为统计信息收集的并行度只是对于单个表,如果用户的表数量多,越往后加大并行度其实速度都差不多
这时候可以优化的就是将用户下的表按批并行进行收集,而不是对整个用户进行收集,可以通过shell脚本去实现对同一个用户下的表同时进行批量表统计信息收集,整体统计信息的收集时间可以提高5倍以上

问题六:新环境性能测试
新环境的性能测试,除了使用常规的SPA进行目标端的SQL回放之外,用户还想模拟应用高频语句在新环境的高并发执行,而常见的性能测试工具sysbench,swingbench都是使用样例做的基准测试,没办法定义自己执行的语句
最后选择的方式是,通过写python脚本,模拟应用的连接池执行高频语句,模拟了对新环境的性能压测,
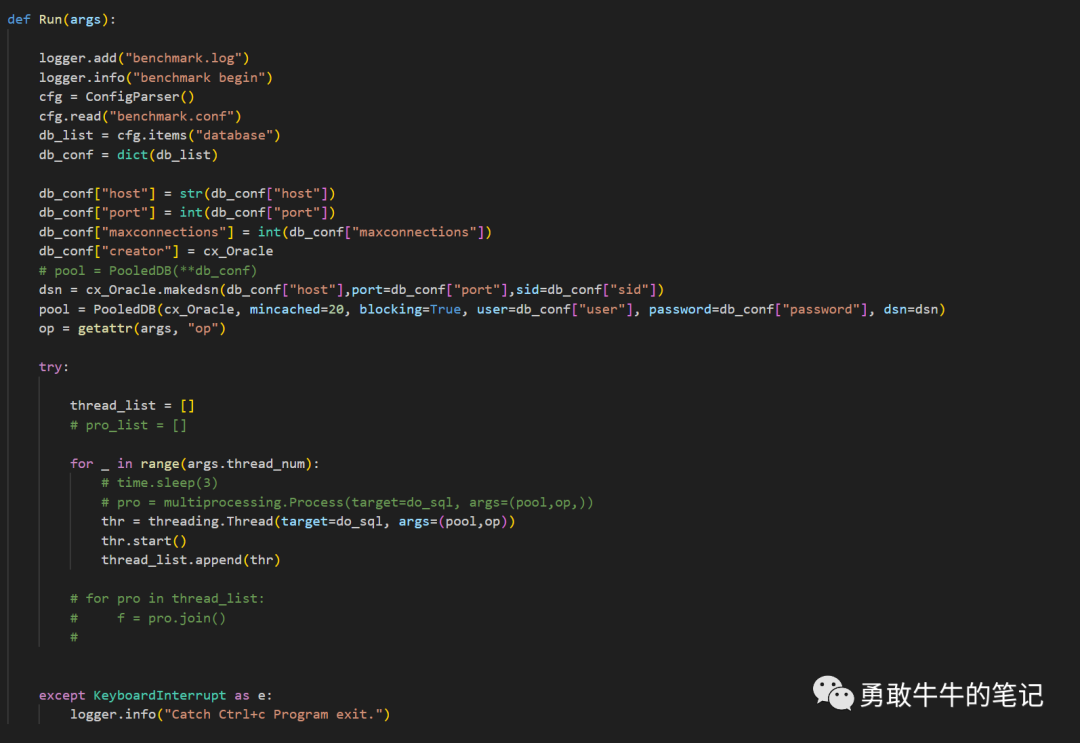
总结:
虽然之前已经做过好几次的OGG迁移项目,但本次由于项目时间紧,1个月内需要完成二轮测试+正式迁移,停机窗口时间少,所以在本次项目里面使用了较多的脚本去提升数据测试和迁移的速度,这也是与以往迁移项目所不同的
希望这些问题以及方法对读者有所帮助,里面部分涉及的脚本由于代码行数偏多,不方便进行展示,后续会单独再更新出现(*^_^*)。














 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









