







 本文详细介绍了MySQL中的锁机制,包括表级锁、行级锁和页级锁,重点讲解了InnoDB存储引擎的行级锁和事务隔离性。此外,还探讨了死锁的产生原因和处理策略,以及乐观锁和悲观锁的概念。文章最后讨论了MVCC(多版本并发控制)如何实现乐观锁,并分析了行锁升级为表锁的场景。
本文详细介绍了MySQL中的锁机制,包括表级锁、行级锁和页级锁,重点讲解了InnoDB存储引擎的行级锁和事务隔离性。此外,还探讨了死锁的产生原因和处理策略,以及乐观锁和悲观锁的概念。文章最后讨论了MVCC(多版本并发控制)如何实现乐观锁,并分析了行锁升级为表锁的场景。
1. 锁的基础与行锁的特点
1.1 概念
- 在开发多用户、数据库驱动的应用时,相当大的一个难点就是解决并发性的问题,目前比较常用的解决方案就是锁机制。
- 锁机制也是数据库系统区别于文件系统的一个关键特性。
- InnoDB 存储引擎和 MyISAM 存储引擎使用的是完全不同的策略。
1.2 锁的类型
- 相比其他数据库而言,MySQL 的锁机制比较简单,而且不同的存储引擎支持不同的锁机制。
- MyISAM 和 Memory 存储引擎使用的是表级锁,BDB 引擎使用的是页级锁,也支持表级锁。由于 BDB
引擎基本已经成为历史,因此就不再介绍了。- InnoDB 存储引擎既支持行级锁,也支持表级锁,默认情况下使用行级锁。
- 表级锁,它直接锁住的是一个表,开销小,加锁快,不会出现死锁的情况,锁定粒度大,发生锁冲突的概率更高,并发度最低。
- 行级锁,它直接锁住的是一条记录,开销大,加锁慢,发生锁冲突的概率较低,并发度很高。行级锁更适合大量按照索引条件并发更新少量不同的数据,同时还有并发查询的应用,比如一些在线事务处理系统,即OLTP(事务处理)。
- 页级锁,它是锁住的一个页面,在 InnoDB 中一个页面为16KB,它的开销介于表级锁和行级锁中间,也可能会出现死锁,锁定粒度也介于表级锁和行级锁中间,并发度也介于表级锁和行级锁中间。仅仅从锁的角度来说,表级锁更加适合于以查询为主的应用,只有少量按照索引条件更新数据的应用,比如大多数的 web 应用。
1.3 innodb锁
InnoDB 与 MyISAM 的相当大的两点不同在于: (1) 支持事务 (2) 采用行级锁
- 行级锁本身与表级锁的实现差别就很大,而事务的引入也带来了很多新问题,尤其是事务的隔离性,与锁机制息息相关。
- 数据库实现事务隔离的方式,基本可以分为两种:
(1) 在操纵数据之前,先对其加锁,防止其他事务对数据进行修改。这就需要各个事务串行操作才可以实现。
(2) 不加任何锁,通过生成一系列特定请求时间点的一致性数据快照,并通过这个快照来提供一致性读取。
上面的第二种方式就是数据多版本并发控制,也就是多版本数据库,一般简称为 MVCC 或者 MCC,它是 Multi Version Concurrency Control 的简写。 - 数据库的事务隔离越严格,并发的副作用就越小,当然付出的代价也就越大,因为事务隔离机制实质上是使得事务在一定程度上”串行化”,这与并行是矛盾的。
1.4 innodb锁类型
- InnoDB 实现了下面两种类型的锁:
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务获得相同数据集的共享读锁和排他写锁。
- 这里有个锁兼容和冲突的概念,如果在加一个锁的时候,另一个锁可以加上去,那么就是锁兼容。如果加上一个锁之后,拒绝其他的锁加上,那么就是锁冲突。
- 意向共享锁(IS锁):事务在请求S锁前,要先获得IS锁
- 意向排他锁(IX锁):事务在请求X锁前,要先获得IX锁
- 各种锁的兼容冲突情况如下:
- X 和所有锁都冲突
- IX 兼容 IX 和 IS
- S 兼容 S 和 IS
- IS 兼容 IS、IX 和 S
- 如果一个事务请求的锁模式与当前的锁兼容,InnoDB 就将请求的锁授予该事务,如果两者是冲突的,那么该事务就要等待锁释放。
- 对于 update、delete、insert 语句,InnoDB 会自动给设计到的数据集加排他锁即 X。
- 对于 select 语句,InnoDB 不会加任何锁。
- 可以使用如下语句来显式的给数据集加锁:
- 共享锁(S):select * from t1 where … lock in share mode;
- 排他锁(X):select * from t1 where … for update;
- 我们可以用 select …in share mode 来获得共享锁,主要用在数据依存关系时来确认某行记录是否存在,并确认没有人对这个记录进行 update 或者 delete 操 作。
- 我们可以使用 select… for update 来获得排他锁,它会拒绝其他事务在其上加其他锁。
1.5 锁对于语句的加锁
- 排它锁
- 当前事务给一行数据加锁,那么其他事务将不能在对数据做任何操作,即:不能读不能写,也不能与其他锁一起使用
- 语法格式如下:
--给`user`表id为1的数据加排它锁
start transaction--开启事务
select * from `user` where id=1 for update;--给id为1的数据加排它锁
commit;--提交事务
rollback;--回滚事务
- 共享锁
- 当前事务给一行数据加共享锁,那么其他事务可以加共享锁,但不能加排它锁。即:能读不能写,可以与共享锁一起使用,但不能与排它锁一起使用;
- 语法格式如下:
--给`user`表id为1的数据加共享锁
start transaction--开启事务
select * from `user` where id=1 lock in share mode;--给id为1的数据加共享锁
commit;--提交事务
rollback;--回滚事务
2. 死锁的产生于处理
- 死锁产生的原因
死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。
- 死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
- 那么对应的解决死锁问题的关键就是:让不同的session加锁有次序
-
死锁的现象
事务1事务2分别对id为1与id为2的数据进行排它锁加锁,随后进行交叉的数据修改。

-
尽可能的避免事务死锁
- 以固定的顺序访问表和行。比如对第2节两个job批量更新的情形,简单方法是对id列表先排序,后执行,这样就避免了交叉等待锁的情形;又比如对于3.1节的情形,将两个事务的sql顺序调整为一致,也能避免死锁。
- 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
- 降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
- 为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
3. 乐观锁与悲观锁的解释
- 悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
- 乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
- MVCC-多版本并发控制实现乐观锁
多版本并发控制 (Multiversion concurrency control, MCC 或 MVCC),是数据库管理系统常用的一种并发控制,也用于程序设计语言实现事务内存。
- 总的来说,MVCC 的出现就是数据库不满用悲观锁去解决读 - 写冲突问题,因性能不高而提出的解决方案。
- 当前读和快照读
- 当前读
像 select lock in share mode (共享锁), select for update ; update, insert ,delete (排他锁)
这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。- 快照读
像不加锁的 select 操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是未提交读和串行化级别,因为未提交读总是读取最新的数据行,而不是符合当前事务版本的数据行。而串行化则会对所有读取的行都加锁- 优缺点
MVCC 使大多数读操作都可以不用加锁,这样设计使得读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行。不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作。
4. 间隙锁与行锁升级为表锁
- 间隙锁
- 当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(NEXT-KEY)锁。
- 危害:
因为Query执行过程中通过范围查找的话,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定值范围内的任何数据,在某些场景下这可能会针对性造成很大的危害。
- 行锁升级为表锁
众所周知,MySQL 的 InnoDB 存储引擎支持事务,支持行级锁(innodb的行锁是通过给索引项加锁实现的)。得益于这些特性,数据库支持高并发。如果 InnoDB 更新数据使用的不是行锁,而是表锁呢?是的,InnoDB 其实很容易就升级为表锁,届时并发性将大打折扣了。
- 常用的索引有三类:主键、唯一索引、普通索引。主键 不由分说,自带最高效的索引属性;唯一索引指的是该属性值重复率为0,一般可作为业务主键,例如学号;普通索引 与前者不同的是,属性值的重复率大于0,不能作为唯一指定条件,例如学生姓名。
- 在不使用索引的情况下进行加锁

运行结果如下:
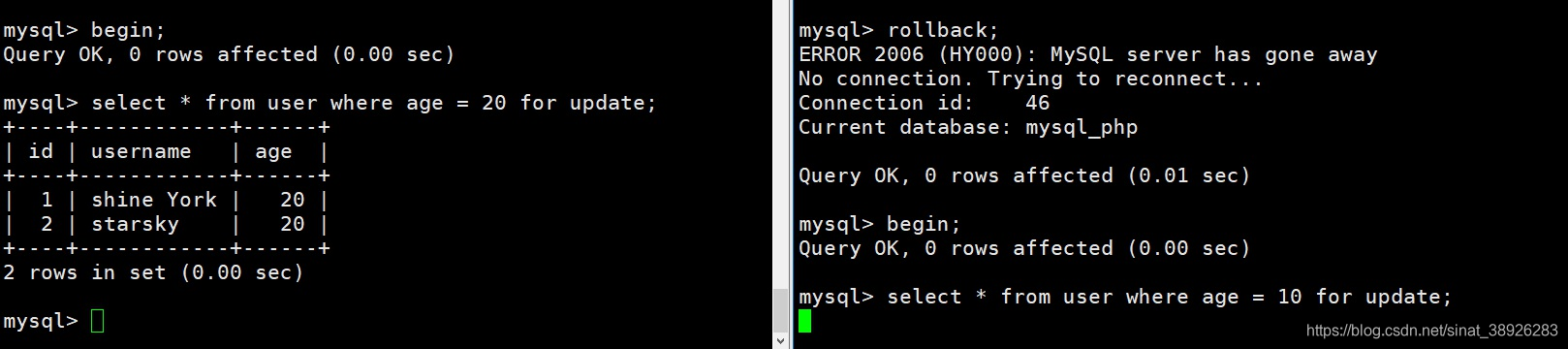
在不给age字段加索引的情况下进行排它锁的加锁操作,可以看到尽管加锁的数据是不同的,但是事务2在加锁时出现了所等待现象。说明此时事务1从行锁升级为表锁,导致事务2在给age=10的数据加锁时出现了所等待现象。
- 在使用普通索引的情况进行加锁
alter table user add index idx_age(age); --给age字段加个索引

运行结果:
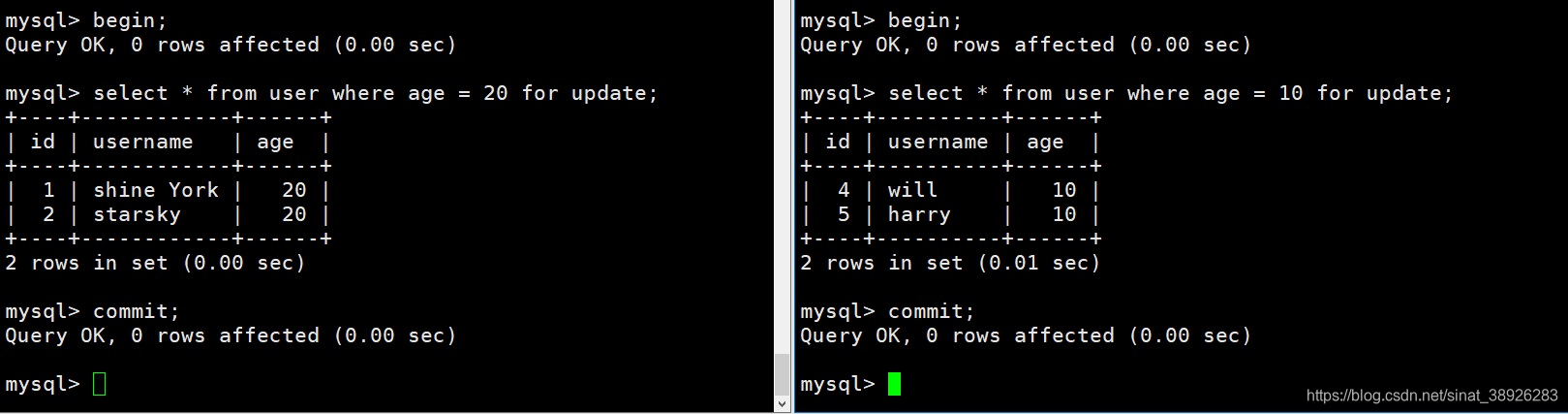
在加了索引之后,再一次进行以上操作,可以看到,user表不在进行表锁,那是因为行锁是建立在索引字段的基础上,如果行锁定的列不是索引列则会升级为表锁
- 范围性查询测试

运行结果:
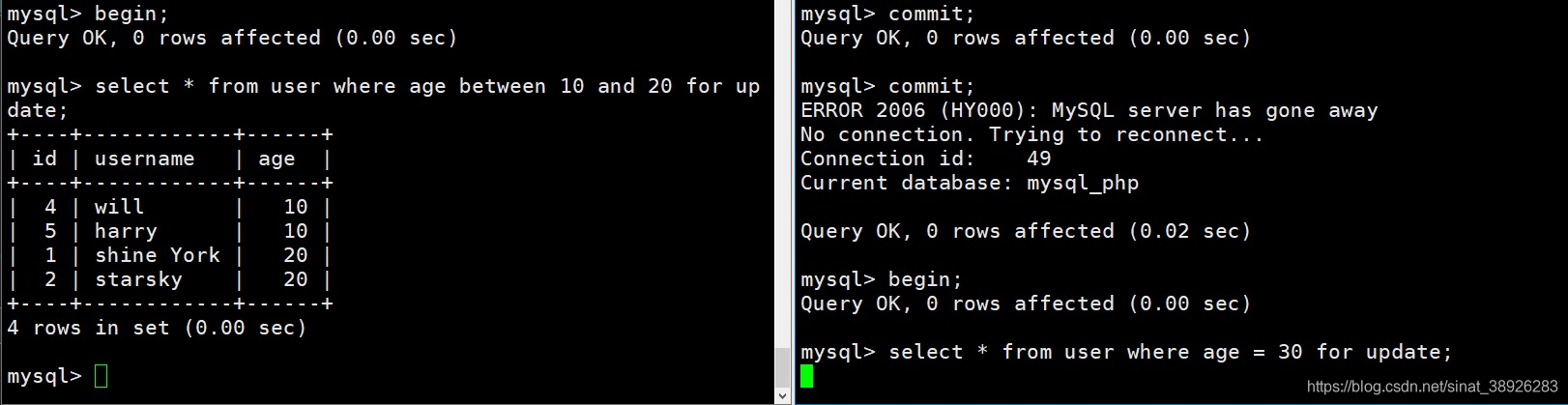
当要进行加锁的数据不确定时,也一样会是表锁。
总结:
- 行锁是建立在索引的基础上。
- 普通索引的数据重复率过高导致索引失效,行锁升级为表所


















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









