







用Python爬取B站弹幕并做成词云
一、获取视频的cid号
1.进入想爬的视频,打开浏览器设置里的“开发者工具”:
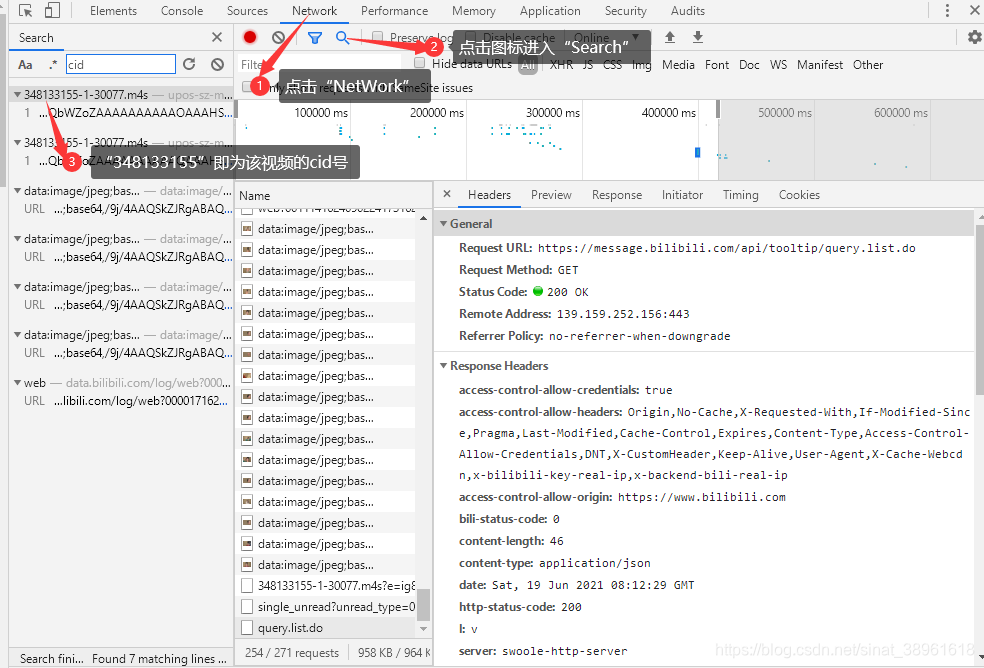
进入NetWork后等待requests刷出,数据够了后可随意点击一个数据查看其preview和其URL,
然后进入Search后输入cid获得视频的cid号。
2.爬视频的弹幕
#爬数据正文
def get_data(cid):
# 分析网页,并获取网页文件
url = 'https://comment.bilibili.com/{}.xml'.format(cid) #B站弹幕数据存放在https://comment.bilibili.com/cid.xml中,其中cid是视频的cid号
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
}
response = requests.get(url,headers = headers).content.decode('utf-8')
return response
def parse_html(response):
# 解读网页文件,获取关键信息
# soup = bs4.BeautifulSoup(response)
# lst = [soup.find_all(name='d')]
# danmuku = [i.text for i in lst]
pattern = re.compile(r'<d p=".*?">(.*?)</d>')
danmuku = re.findall(pattern,response)
#print(danmuku) #打印弹幕数据
return danmuku
def save_data(danmuku,cid):
# 保存数据
Dict = {
'danmuku' : danmuku
}
pd_data = pd.DataFrame(Dict)
cid = str(cid)
name = cid + '弹幕文件.txt'
path = 'C:/Users/priesty/Desktop/弹幕数据/{}'.format(name)
pd_data.to_csv(path,index = False,header=False,mode='w',encoding='utf-8-sig')
def data_preprocess(danmuku,cid):
cid = str(cid)
name = cid + '弹幕文件.txt'
path = 'C:/Users/priesty/Desktop/弹幕数据/{}'.format(name)
with open(path ,mode='r',encoding='utf-8') as f:
# 加载用户自定义字典
jieba.load_userdict (r'C:/Users/priesty/Desktop/弹幕数据/自定义词表.txt')
reader = f.read().replace('\n','')
# 加载停用词词表
stopwords = [line.strip() for line in open(r'C:/Users/priesty/Desktop/弹幕数据/停用词表.txt',encoding ='utf8').readlines()] #原代码为gbk,改为了utf8
# 去标点,去数字,去空白
pun_num = string.punctuation + string.digits
table = str.maketrans('','',pun_num)
reader = reader.translate(table)
seg_list = jieba.cut(reader,cut_all=False)
sentence = ''
for word in seg_list:
if word not in stopwords and word.isspace() == False:
sentence += word
sentence += ','
sentence = sentence[:-1]
return sentence
def count_words(txt,cid):
cid = str(cid)
name = cid + '弹幕词汇数统计.txt'
path = 'C:/Users/priesty/Desktop/弹幕数据/{}'.format(name)
aDict = {}
words = txt.split(',')
for word in words:
aDict[word] = aDict.get(word,0) + 1
pd_count = pd.DataFrame(aDict,index=['times']).T.sort_values('times',ascending=False)
pd_count.to_csv(path)
if __name__ == "__main__":
cid = int(input('请输入你想查询的视频CID号:'))
response = get_data(cid) #这两句可改为一句response = get_data(348133155)
danmuku = parse_html(response)
save_data(danmuku,cid)
sentence = data_preprocess(danmuku,cid)
count_words(sentence,cid)
原代码来自:https://blog.csdn.net/paxiaochong001/article/details/116937710
ps:1.“自定义词表”和“停用词表”内容可以随便添加
2.B站弹幕数据存放在https://comment.bilibili.com/cid.xml中,其中cid是视频的cid号
3.路径的斜杠别用反了
3.制作词云
安装jieba、wordcloud、request库(后两个基本上新版自带)
#词云正文
#背景图
bg=np.array(Image.open("C:/Users/priesty/Desktop/弹幕数据/1.png"))
#获取当前的项目文件加的路径
d=path.dirname('__file__') #file要加引号
#d=os.path.abspath('')
#读取停用词表
stopwords_path='C:/Users/priesty/Desktop/弹幕数据/停用词表.txt'
#添加需要自定以的分词
jieba.add_word("晚唐")
jieba.add_word("武周")
#读取要分析的文本
text_path="C:/Users/priesty/Desktop/弹幕数据/348133155弹幕文件.txt" #文本太大读取不出来
#读取要分析的文本,读取格式
text=open(path.join(d,text_path),encoding="utf8").read()
#定义个函数式用于分词
def jiebaclearText(text):
#定义一个空的列表,将去除的停用词的分词保存
mywordList=[]
#进行分词
seg_list=jieba.cut(text,cut_all=False)
#将一个generator的内容用/连接
listStr='/'.join(seg_list)
#打开停用词表
f_stop=open(stopwords_path,encoding="utf8")
#读取
try:
f_stop_text=f_stop.read()
finally:
f_stop.close()#关闭资源
#将停用词格式化,用\n分开,返回一个列表
f_stop_seg_list=f_stop_text.split("\n")
#对默认模式分词的进行遍历,去除停用词
for myword in listStr.split('/'):
#去除停用词
if not(myword.split()) in f_stop_seg_list and len(myword.strip())>1:
mywordList.append(myword)
return ' '.join(mywordList)
text1=jiebaclearText(text)
#生成
wc=WordCloud(
background_color="white",
max_words=200,
mask=bg, #设置图片的背景
max_font_size=60,
random_state=42,
font_path='C:/Windows/Fonts/simkai.ttf' #中文处理,用系统自带的字体
).generate(text1)
#为图片设置字体
my_font=fm.FontProperties(fname='C:/Windows/Fonts/simkai.ttf')
#产生背景图片,基于彩色图像的颜色生成器
image_colors=ImageColorGenerator(bg)
#开始画图
plt.imshow(wc.recolor(color_func=image_colors))
#为云图去掉坐标轴
plt.axis("off")
#画云图,显示
plt.figure()
#为背景图去掉坐标轴
plt.axis("off")
plt.imshow(bg,cmap=plt.cm.gray)
#保存云图
wc.to_file("C:/Users/priesty/Desktop/弹幕数据/2.png")
原代码来自:https://piqiandong.blog.csdn.net/article/details/79558589
则词云图片为:

4.整个原代码
#爬数据前缀
import requests
import re
import pandas as pd
import string
import jieba
#词云前缀
from os import path #用来获取文档的路径
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
#词云生成工具
from wordcloud import WordCloud,ImageColorGenerator
#需要对中文进行处理
import matplotlib.font_manager as fm
#爬数据正文
def get_data(cid):
# 分析网页,并获取网页文件
url = 'https://comment.bilibili.com/{}.xml'.format(cid) #B站弹幕数据存放在https://comment.bilibili.com/cid.xml中,其中cid是视频的cid号
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
}
response = requests.get(url,headers = headers).content.decode('utf-8')
return response
def parse_html(response):
# 解读网页文件,获取关键信息
# soup = bs4.BeautifulSoup(response)
# lst = [soup.find_all(name='d')]
# danmuku = [i.text for i in lst]
pattern = re.compile(r'<d p=".*?">(.*?)</d>')
danmuku = re.findall(pattern,response)
#print(danmuku) #打印弹幕数据
return danmuku
def save_data(danmuku,cid):
# 保存数据
Dict = {
'danmuku' : danmuku
}
pd_data = pd.DataFrame(Dict)
cid = str(cid)
name = cid + '弹幕文件.txt'
path = 'C:/Users/priesty/Desktop/弹幕数据/{}'.format(name)
pd_data.to_csv(path,index = False,header=False,mode='w',encoding='utf-8-sig')
def data_preprocess(danmuku,cid):
cid = str(cid)
name = cid + '弹幕文件.txt'
path = 'C:/Users/priesty/Desktop/弹幕数据/{}'.format(name)
with open(path ,mode='r',encoding='utf-8') as f:
# 加载用户自定义字典
jieba.load_userdict (r'C:/Users/priesty/Desktop/弹幕数据/自定义词表.txt')
reader = f.read().replace('\n','')
# 加载停用词词表
stopwords = [line.strip() for line in open(r'C:/Users/priesty/Desktop/弹幕数据/停用词表.txt',encoding ='utf8').readlines()]#原代码为gbk,改为了utf8
# 去标点,去数字,去空白
pun_num = string.punctuation + string.digits
table = str.maketrans('','',pun_num)
reader = reader.translate(table)
seg_list = jieba.cut(reader,cut_all=False)
sentence = ''
for word in seg_list:
if word not in stopwords and word.isspace() == False:
sentence += word
sentence += ','
sentence = sentence[:-1]
return sentence
def count_words(txt,cid):
cid = str(cid)
name = cid + '弹幕词汇数统计.txt'
path = 'C:/Users/priesty/Desktop/弹幕数据/{}'.format(name)
aDict = {}
words = txt.split(',')
for word in words:
aDict[word] = aDict.get(word,0) + 1
pd_count = pd.DataFrame(aDict,index=['times']).T.sort_values('times',ascending=False)
pd_count.to_csv(path)
if __name__ == "__main__":
cid = int(input('请输入你想查询的视频CID号:'))
response = get_data(cid) #这两句可改为一句response = get_data(348133155)
danmuku = parse_html(response)
save_data(danmuku,cid)
sentence = data_preprocess(danmuku,cid)
count_words(sentence,cid)
#词云正文
#背景图
bg=np.array(Image.open("C:/Users/priesty/Desktop/弹幕数据/1.png"))
#获取当前的项目文件加的路径
d=path.dirname('__file__') #file要加引号
#d=os.path.abspath('')
#读取停用词表
stopwords_path='C:/Users/priesty/Desktop/弹幕数据/停用词表.txt'
#添加需要自定以的分词
jieba.add_word("晚唐")
jieba.add_word("武周")
#读取要分析的文本
text_path="C:/Users/priesty/Desktop/弹幕数据/348133155弹幕文件.txt" #文本太大读取不出来
#读取要分析的文本,读取格式
text=open(path.join(d,text_path),encoding="utf8").read()
#定义个函数式用于分词
def jiebaclearText(text):
#定义一个空的列表,将去除的停用词的分词保存
mywordList=[]
#进行分词
seg_list=jieba.cut(text,cut_all=False)
#将一个generator的内容用/连接
listStr='/'.join(seg_list)
#打开停用词表
f_stop=open(stopwords_path,encoding="utf8")
#读取
try:
f_stop_text=f_stop.read()
finally:
f_stop.close()#关闭资源
#将停用词格式化,用\n分开,返回一个列表
f_stop_seg_list=f_stop_text.split("\n")
#对默认模式分词的进行遍历,去除停用词
for myword in listStr.split('/'):
#去除停用词
if not(myword.split()) in f_stop_seg_list and len(myword.strip())>1:
mywordList.append(myword)
return ' '.join(mywordList)
text1=jiebaclearText(text)
#生成
wc=WordCloud(
background_color="white",
max_words=200,
mask=bg, #设置图片的背景
max_font_size=60,
random_state=42,
font_path='C:/Windows/Fonts/simkai.ttf' #中文处理,用系统自带的字体
).generate(text1)
#为图片设置字体
my_font=fm.FontProperties(fname='C:/Windows/Fonts/simkai.ttf')
#产生背景图片,基于彩色图像的颜色生成器
image_colors=ImageColorGenerator(bg)
#开始画图
plt.imshow(wc.recolor(color_func=image_colors))
#为云图去掉坐标轴
plt.axis("off")
#画云图,显示
plt.figure()
#为背景图去掉坐标轴
plt.axis("off")
plt.imshow(bg,cmap=plt.cm.gray)
#保存云图
wc.to_file("C:/Users/priesty/Desktop/弹幕数据/2.png")
结果图:
参考文章:https://blog.csdn.net/paxiaochong001/article/details/116937710
https://piqiandong.blog.csdn.net/article/details/79558589















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









