




输入:
a = [
{'id': 18, 'user_name': '张三', 'gift_name': '礼物9', 'surplus': 10},
{'id': 19, 'user_name': '李四', 'gift_name': '礼物10', 'surplus': 20},
{'id': 20, 'user_name': '王二', 'gift_name': '礼物11', 'surplus': 18},
{'id': 18, 'user_name': '张三', 'gift_name': '礼物10', 'surplus': 2},
{'id': 18, 'user_name': '张三', 'gift_name': '礼物11', 'surplus': 12},
{'id': 19, 'user_name': '李四', 'gift_name': '礼物11', 'surplus': 2}
]
输出
b = [
{
'id':18,'user_name':'张三',
"gift_info":[{"gift_name":'礼物9','surplus':10},
{"gift_name":'礼物10','surplus':2},
{'gift_name': '礼物11', 'surplus': 12}
]
},
{
'id': 19, 'user_name': '李四',
"gift_info":[{'gift_name': '礼物10', 'surplus': 20},
{'gift_name': '礼物11', 'surplus': 2}]
},
{
'id': 20, 'user_name': '王二',
'gift_info':[{'gift_name': '礼物11', 'surplus': 18},
]
}
]
代码:
b = [] # 用来存放结果
ids_dict = {} # 用来存放列表中某个id 第一次出现于列表b中的下标
for index, value in enumerate(a):
id_n = value.get('id')
if not ids_dict.get(id_n): # 第一次出现该id,为防止index为0 出现get()错误,index一开始从1开始
ids_dict[id_n]=index+1 # 记录当前id的下标
temp = {key: value for key, value in value.items()
if key == 'id' or key == 'user_name'} # 先 生成id 和user_name 的字典,其他字段额外处理(or key in ('id','user_name))
gift_lists = [dict(gift_name=value.get('gift_name'),
surplus=value.get('surplus')
)]
temp['gift_info']=gift_lists
b.append(temp)
else: # 第>=2次出现该id
index=ids_dict.get(id_n)
index-=1 # 还原其原来下标
gift_lists = [dict(gift_name=value.get('gift_name'),
surplus=value.get('surplus')
)]
b[index]['gift_info'].extend(gift_lists)
print(b)
Q&A:
-
ids_dict中的键值对中的 值下标从1开始,从0开始会出错
因为我判断id 是否能够在ids_dict拿到值,如果值是0(下标为0),name就会判断它是第一次出现该id,但实际上已经出现过此id -
append和extend的区别
extend 接受一个参数(list类型),并且把这个 list 中的每个元素添加到原 list 中
append 接受的参数可以是任何数据类型,并且简单地追加到 list 的尾部 -
思路的问题
感觉自己每次在解决一个问题时,刚开始的思路有点儿跑偏(一直在测试自己的想法),后来过分依赖debug功能,而不是自己手写写算法流程.在解决这道题时,我花了一些时间用上一题的解法,但实际上,题目不同,解决的方案肯定也不一样,当然也可以用之前的方法解决,但算法效率就不行了 -
我的测试记录:
- 利用filter()函数过滤,failed
- 利用my_dict.items() 以
列表形式返回的二元组,只能遍历,其他操作无法进行
for i in a:
display(i.items()[1])
# 'dict_items' object does not support indexing
- 字典的zip()函数 —> 将字典的一对键作为二元组
- 通过元组来创建字典,failed —>dict([[],…,[]]) or dict([(),…,()])才成功
- 字典从无序变成有序 —> from collections import OrderedDict,其顺序是字典元素的插入顺序
- 创建杂交水稻(命名为列表字典生成式)
x=[{'gift_name': '礼物9', 'id': 18, 'surplus': 10, 'user_name': '张三'},
{'gift_name': '礼物10', 'id': 18, 'surplus': 2, 'user_name': '张三'},
{'gift_name': '礼物11', 'id': 20, 'surplus': 18, 'user_name': '王二'}]
for i in x:
# 直接将其中的key变成字符串,而不是当成变量!!!!!!!!
result=[ dict(key=value) for key,value in i.items() if key=='gift_name']
print(result)
# [{'key': '礼物11'}]
直接将其中的key变成字符串,而不是当成变量
x=[{'gift_name': '礼物9', 'id': 18, 'surplus': 10, 'user_name': '张三'},
{'gift_name': '礼物10', 'id': 18, 'surplus': 2, 'user_name': '张三'},
{'gift_name': '礼物11', 'id': 20, 'surplus': 18, 'user_name': '王二'}]
for i in x:
result=[ {key:value} for key,value in i.items() if key=='id']
print(result)
# [{'id': 20}]
- 字典的创建 her_dict=dict(b=1)
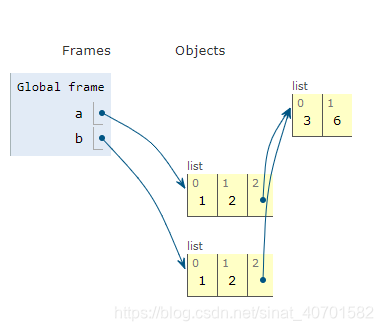
- 列表的浅复制 b=[1,2,[3,6]] a=b[:]
字典的更新
d1={'china':'beijing','russia':'moscow'}
d2={'china':'shanghai','america':'washington'}
d3=dict(d1,**d2)
d3
Out[5]: {'china': 'shanghai', 'russia': 'moscow', 'america': 'washington'}
小测试
d3d=dict(d1)
d3d
Out[9]: {'china': 'beijing', 'russia': 'moscow'}
d3d=dict(**d2)# 涉及到字典的解包,直接将对
解包,然后原地更新
d3d
Out[11]: {'china': 'shanghai', 'america': 'washington'}
安利 python 代码执行可视化网站
http://www.pythontutor.com/visualize.html#mode=edit

















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









