









对于熟悉Scala开发的人来说,对于spark-sql的使用,直接jar包中写入代码处理就能轻松实现动态语句的执行。
但是对于我,不打算学习Scala和Java语言,但是又想定时执行时间推延的周期、定时任务,该肿么办?
一 Spark-SQL 是什么
1: Spark-SQL参见参数
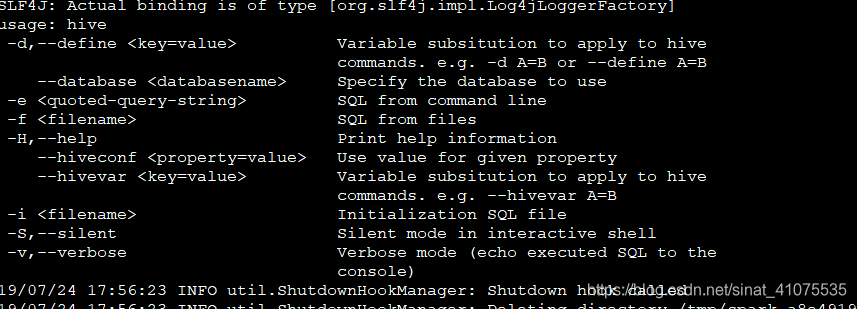
\
- -d
:–define <key=value> 定义键值对
:–database 定义使用的数据库 - -e : 是运行sql语句,适用于简单的sql
- -f :是运行sql文件,适用于复杂的sql语句
-
-
-H
- –hiveconf <property=value> 可以替换hive sql中的变量,实现动态参数
- – hivevar <key=value> 用户自定义变量
- -i : 初始化的SQL文件
- -S :Silent mode 模式 (静音交付模式)
- -v :Verbose mode 模式(输出详细的信息)
二 Spark-SQL 调试的各种方式
1. local 模式
spark-sql -e "
use src;
select * from src_acadsoc_com_acc_coupon limit 10; "
2. hiveconf 用法,用于传递参数
备注:2个的不可以
spark-sql --hiveconf table=src_acadsoc_com_acc_coupon -e "
use src;
select id from ${table} limit 10; "
##3. hivevar用法
备注:2个的不可以
spark-sql --hivevar table=src_acadsoc_com_acc_coupon -e "
use src;
select * from ${table} limit 10;"
##4. Spark-SQL ON YARN clinet 模式
- 例子一
spark-sql --master yarn --executor-memory 1G -e "
use src;
select * from src_acadsoc_com_acc_coupon limit 10; "
- 例子二
spark-sql --master yarn \
--deploy-mode client \
--driver-memory 1G \
--executor-memory 1G \
--num-executors 2 \
--executor-cores 2 \
-e "
use src;
select * from src_acadsoc_com_acc_coupon limit 10; "
- 例子三 define 定义配置信息
spark-sql --master yarn \
--deploy-mode client \
--driver-memory 4G \
--executor-memory 1G \
--num-executors 4 \
--executor-cores 2 \
--define spark.sql.shuffle.partitions=100 \
-e "
use spark_ods;
select count(*) from (
select a.uid from spark_ods_base_acadsoc_com_cn_uc_user_day a
join
spark_ods_base_acadsoc_com_cn_uc_user_day b
join
spark_ods_base_acadsoc_com_cn_uc_user_day c
where a.uid=b.uid and a.uid=c.uid)
c
; "














 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









