







这是我的第401篇原创文章。
一、引言
时间序列预测任务常见的方法有:(1)统计模型(如 ARIMA);(2)简单的机器学习模型(如 SVM、神经网络);(3)深度学习方法(如 LSTM、Transformer)。本文先利用 Transformer 对原始时间序列进行特征编码,从而捕捉数据中的时序特性、周期性与噪声,然后将提取到的高维特征输入到 SVM 模型中(这里采用支持向量回归 SVR 进行回归预测),利用 SVM 在小样本高维空间中具有良好泛化能力的特点进一步提高预测精度。通过这种“深度特征+传统回归模型”的组合方法,既能利用 Transformer 强大的时序特征提取能力,又可以发挥 SVR 在高维数据上较好的回归性能,从而达到较好的预测效果。
二、实现过程
2.1 数据读取
核心代码:
data = pd.read_csv('data.csv')
# 将日期列转换为日期时间类型
data['Month'] = pd.to_datetime(data['Month'])
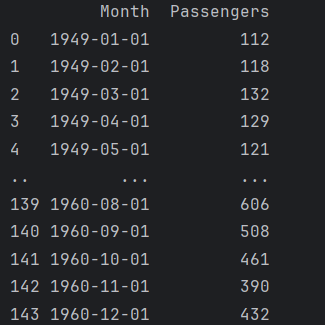
print(data)
load_series = np.array(data['Passengers'])
time_series = np.array(data['Month'])data:
2.2 数据预处理
核心代码:
# 利用滑动窗口生成样本数据,窗口大小为 seq_len,目标为下一个时间步的乘客值
seq_len = 24
X, y = create_sliding_window(load_series, seq_len=seq_len)
# 数据归一化(简单标准化)
mean_val = np.mean(X)
std_val = np.std(X)
X_norm = (X - mean_val) / std_val
y_norm = (y - mean_val) / std_val
# 划分训练集与测试集(70% 训练,30% 测试)
split_idx = int(0.7 * len(X_norm))
X_train, X_test = X_norm[:split_idx], X_norm[split_idx:]
y_train, y_test = y_norm[:split_idx], y_norm[split_idx:]
t_train = np.arange(len(X_train))
t_test = np.arange(len(X_train), len(X_train) + len(X_test))自定义 Dataset:
train_dataset = LoadDataset(X_train, y_train)
test_dataset = LoadDataset(X_test, y_test)
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.3 Transformer模型定义
核心代码:
class TransformerRegressor(nn.Module):
def __init__(self, input_dim=1, d_model=64, nhead=8, num_layers=2, dim_feedforward=128, dropout=0.1):
super(TransformerRegressor, self).__init__()
self.input_dim = input_dim
self.d_model = d_model
# 将输入特征扩展到 d_model 维度
self.input_fc = nn.Linear(input_dim, d_model)
self.pos_encoder = PositionalEncoding(d_model)
# 定义 Transformer Encoder 层
encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)
# 输出层,预测下一个时刻的负荷值(回归任务)
self.output_fc = nn.Linear(d_model, 1)
def forward(self, src):
# src shape: (batch_size, seq_len)
# 先将输入扩展一个维度(feature dimension)
src = src.unsqueeze(-1) # (batch_size, seq_len, 1)
# 线性映射到 d_model 维度
src = self.input_fc(src) # (batch_size, seq_len, d_model)
# 加入位置编码
src = self.pos_encoder(src) # (batch_size, seq_len, d_model)
# Transformer 默认输入 shape 为 (seq_len, batch_size, d_model)
src = src.transpose(0, 1) # (seq_len, batch_size, d_model)
# 得到编码器输出
output = self.transformer_encoder(src) # (seq_len, batch_size, d_model)
# 取最后一个时刻的隐藏状态作为整体特征表示
final_feature = output[-1, :, :] # (batch_size, d_model)
# 通过全连接层预测目标值
out = self.output_fc(final_feature) # (batch_size, 1)
return out.squeeze(-1), final_feature # 返回预测值和特征表示2.4 模型训练(Transformer部分)
核心代码:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TransformerRegressor().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 50
train_losses = []
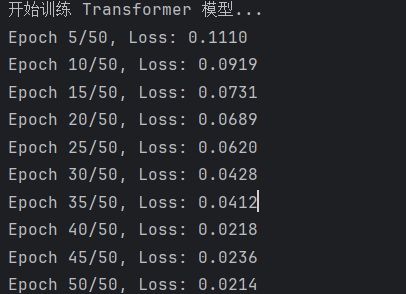
print("开始训练 Transformer 模型...")
for epoch in range(num_epochs):
model.train()
epoch_loss = 0.0
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
optimizer.zero_grad()
# 前向传播,得到预测值和内部特征
pred, _ = model(batch_x)
loss = criterion(pred, batch_y)
loss.backward()
optimizer.step()
epoch_loss += loss.item() * batch_x.size(0)
epoch_loss /= len(train_dataset)
train_losses.append(epoch_loss)
if (epoch+1) % 5 == 0:
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}")结果:
2.5 特征提取
利用训练好的 Transformer 模型提取训练集和测试集特征:
def extract_features(model, dataloader):
model.eval()
features = []
targets = []
predictions = []
with torch.no_grad():
for batch_x, batch_y in dataloader:
batch_x = batch_x.to(device)
pred, feat = model(batch_x)
features.append(feat.cpu().numpy())
predictions.append(pred.cpu().numpy())
targets.append(batch_y.cpu().numpy())
features = np.concatenate(features, axis=0)
targets = np.concatenate(targets, axis=0)
predictions = np.concatenate(predictions, axis=0)
return features, targets, predictions
train_features, train_targets, _ = extract_features(model, train_loader)
test_features, test_targets, test_transformer_pred = extract_features(model, test_loader)2.6 SVR建模
使用 SVR 对 Transformer 提取的特征进行回归建模:
svr_model = SVR(kernel='rbf', C=1.0, epsilon=0.1)
svr_model.fit(train_features, train_targets)2.7 SVR模型预测
对测试集进行预测:
svr_pred = svr_model.predict(test_features)
svr_mse = mean_squared_error(test_targets, svr_pred)
print(f"SVR Test MSE: {svr_mse:.4f}")结果:
![]()
2.8 结果可视化
原始时间序列:
plt.figure(figsize=(10, 6))
sns.set(font_scale=1.2)
plt.rc('font', family=['Times New Roman', 'Simsun'], size=12)
# 图1:原始乘客时间序列
plt.plot(time_series, load_series, color='blue', linewidth=2)
plt.xlabel("Time", fontsize=12)
plt.ylabel("Load", fontsize=12)
plt.title("Raw Time Series", fontsize=14)
plt.grid(True)
plt.tight_layout()
plt.show()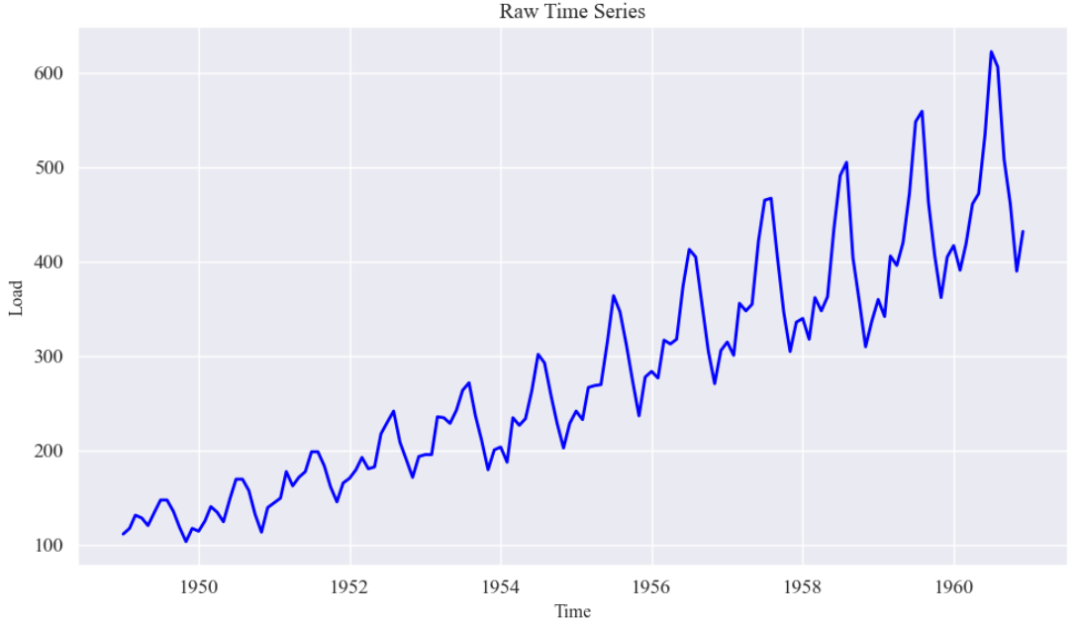
训练损失曲线:
plt.plot(range(1, num_epochs+1), train_losses, marker='o', color='red', linewidth=2)
plt.xlabel("Epoch", fontsize=12)
plt.ylabel("MSE Loss", fontsize=12)
plt.title("Training Loss Curve", fontsize=14)
plt.grid(True)
plt.tight_layout()
plt.show()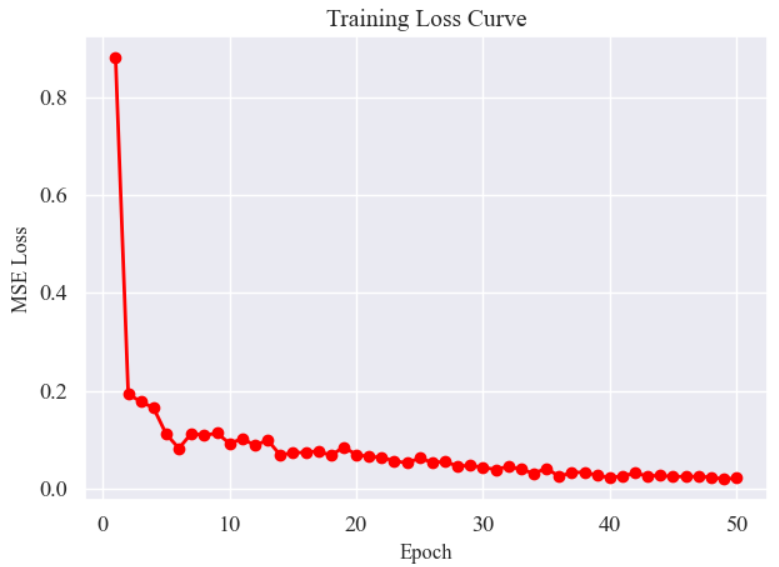
Transformer+SVR 的预测结果与真实乘客数对比(测试集),由于测试集数据在原始序列中位于后半部分,因此横轴使用测试数据对应的时间序列索引:
plt.plot(t_test, test_targets * std_val + mean_val, label="Actual Load", color='purple', linewidth=2)
plt.plot(t_test, svr_pred * std_val + mean_val, label="Predicted Load", color='cyan', linewidth=2, linestyle='--')
plt.xlabel("Time", fontsize=12)
plt.ylabel("Load", fontsize=12)
plt.title("Predicted vs. Actual Load", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()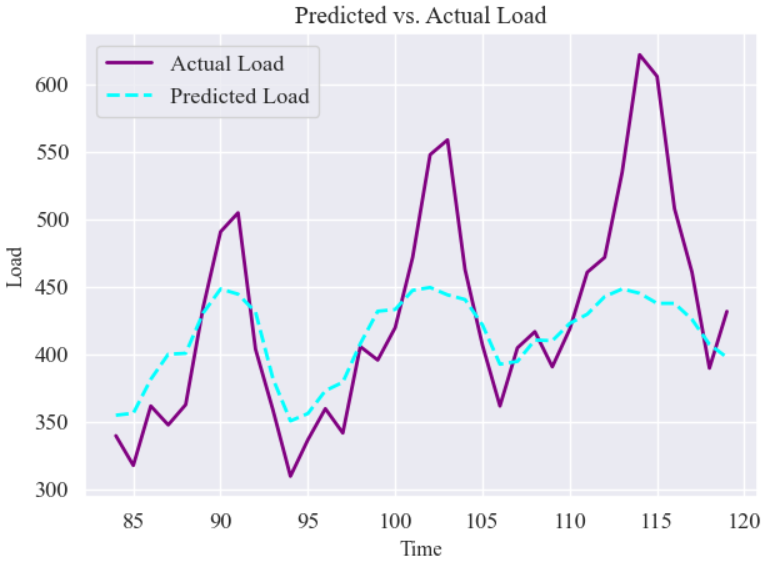
Transformer 特征 PCA 降维可视化,对测试集提取的高维特征进行 PCA 降维到二维:
pca = PCA(n_components=2)
features_2d = pca.fit_transform(test_features)
# 利用目标值进行颜色映射,形成散点图
sc = plt.scatter(features_2d[:, 0], features_2d[:, 1], c=test_targets, cmap='jet', s=50, alpha=0.8)
plt.xlabel("PC1", fontsize=12)
plt.ylabel("PC2", fontsize=12)
plt.title("PCA of Transformer Features", fontsize=14)
plt.colorbar(sc, label="Normalized Load")
plt.grid(True)
plt.tight_layout()
plt.show()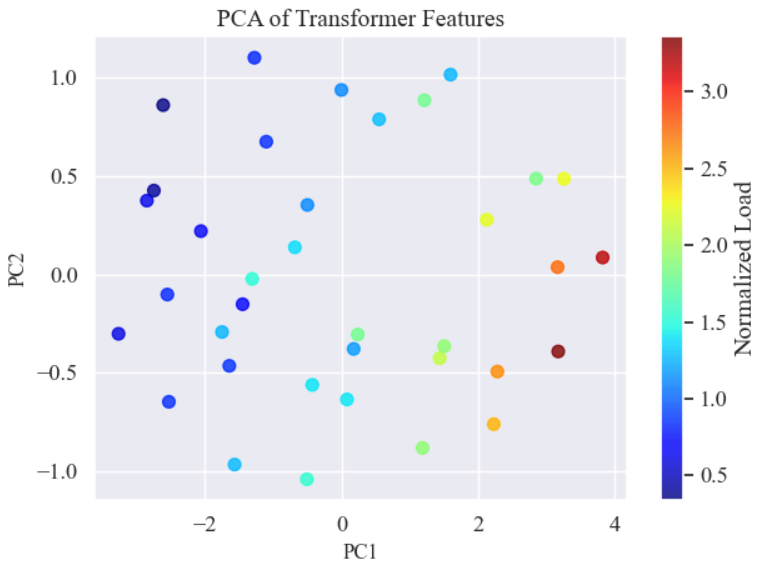
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











