






Hadoop分布式集群搭建
- 创建虚拟机(用VmWare工具,centos6)
- 克隆三台机器
master
slaver1
slaver2
- 分别在每台机器上安装jdk >= 1.7版本
vim /etc/profile

四、同步三台虚拟机的时间(时间同步)每台机器都要做同样的操作
1、yum install ntp
2、输入“cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime”
3、输入“ntpdate pool.ntp.org”
注意:如果电脑可以上网,但是虚拟机不可以上网,可以如下操作
编辑 vim /etc/resolv.conf
添加如下两行指令
nameserver 202.106.0.20
nameserver 8.8.8.8
- 设置主机名
10.1.13.103(IP号) 设置这台机器的主机名为master
10.1.13.104(IP号) 设置这台机器的主机名为slaver1
10.1.13.105(IP号) 设置这台机器的主机名为slaver2
在10.1.13.103(IP号)机器上执行如下操作
- adduser master
- passwd master 提示输入密码和再次确定
- 修改主机名 vim /etc/sysconfig/network

- 给master用户root权限
chmod +w /etc/sudoers
vim /etc/sudoers

- 重启虚拟机,选择master用户登录
注意:另外两台机器也做同上的操作(名字分别为slaver1和slaver2)
- 修改主机映射(三台机器都是一样的操作)
- vim /etc/hosts
把hosts中的内容都删除,然后添加如下

- 配置静态ip
1、vim /etc/udev/rules.d/70**-net.rules

改完的效果

2、vim /etc/sysconfig/network-scripts/ifcfg-eth0
原来的样子

修改后的样子
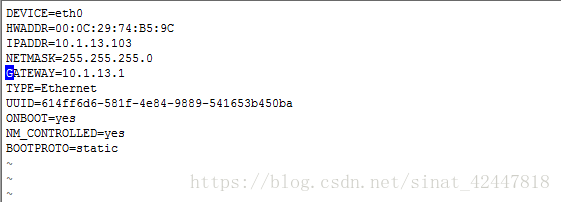
- 重启网卡
service network restart
成功后,提示如下

- 剩下的两台机器,做同上操作(ip和mac地址是不一样)
- 配置三台机器之间的免密登录(必须在主机master上操作)
ssh-keygen -t rsa 然后四个回车
ssh-copy-id master 提示输入密码
ssh-copy-id slaver1 提示输入密码
ssh-copy-id slaver2 提示输入密码
测试: ssh slaver1 就不需要输入密码 然后在exit到当前用户,可以执行下一次测试
- 下载hadoop压缩包,解压(以下的所有操作都在主机上 进行) 温馨提示:最好在官网下载,src的源码,然后在自己的机器上编译,这样就不会出现找不到jar包的异常
- 把hadoop解压到/usr/local/目录下
tar -zxvf hadoop-2.8.4.tar.gz -C /usr/local
- 把hadoop-2.8.4改名为hadoop
进入到/usr/local/下执行
mv hadoop-2.8.4 hadoop
- 配置hadoop环境变量(也在主机下执行)
vim /etc/profile

立即让配置文件生效
source /etc/profile
此时,可以直接使用hadoop指令了
eg: hadoop version

- 关闭防火墙(三台机器都要关闭)
service iptables status
service iptables stop(临时关闭,不需要重启虚拟机)
chkconfig iptables off(永久关闭,需要重启机器生效)
- 修改主机的配置文件
进入到/uer/local/hadoop文件夹
然后mkdir namenode
mkdir datanode
mkdir tmp
进入到 /usr/loacal/hadoop/etc/hadoop文件然后如下编辑
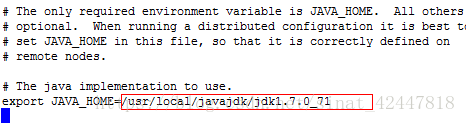
1、vim hadoop-env.sh
原来

该后
2、vim core-site.xml
在configuretion中添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
效果

3、vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/datanode</value>
</property>
效果

4、vim mapred-site.xml(没有mapred-site.xml但是有一个 mapred-site.xml.template
5、我们可以把名字改一下就可以了)
- mv mapred-site.xml.template mapred-site.xml
- vim mapred-site.xml 然后添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
效果

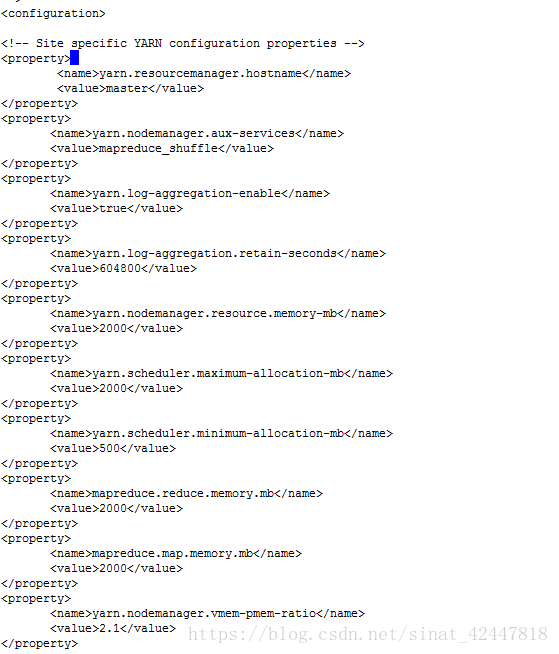
6、yarm-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>500</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2000</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
效果

7、slaver
vim slavers
master
slaver1
slaver2
效果

- 下发配置文件到分机上
下发hadoop到分机
- scp -r /usr/local/hadoop root@slaver1:/usr/local/
- scp -r /usr/local/hadoop root@slaver2:/usr/local/
下发环境变量配置文件到分机
- scp -r /etc/profile root@slaver1:/etc/
- scp -r /etc/profile root@slaver2:/etc/
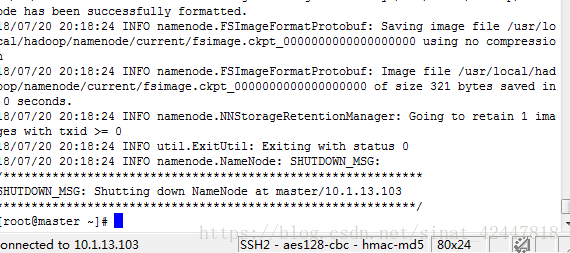
- 第一次执行的时候在主机下格式化namenode
hadoop namenode -format
格式化成功
- 启动hadoop集群
- start-all.sh
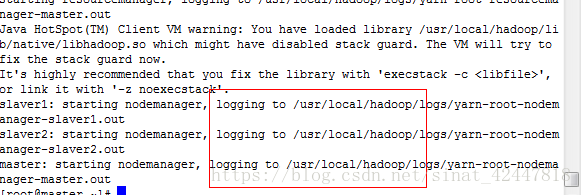
- 关闭集群
- stop-all.sh
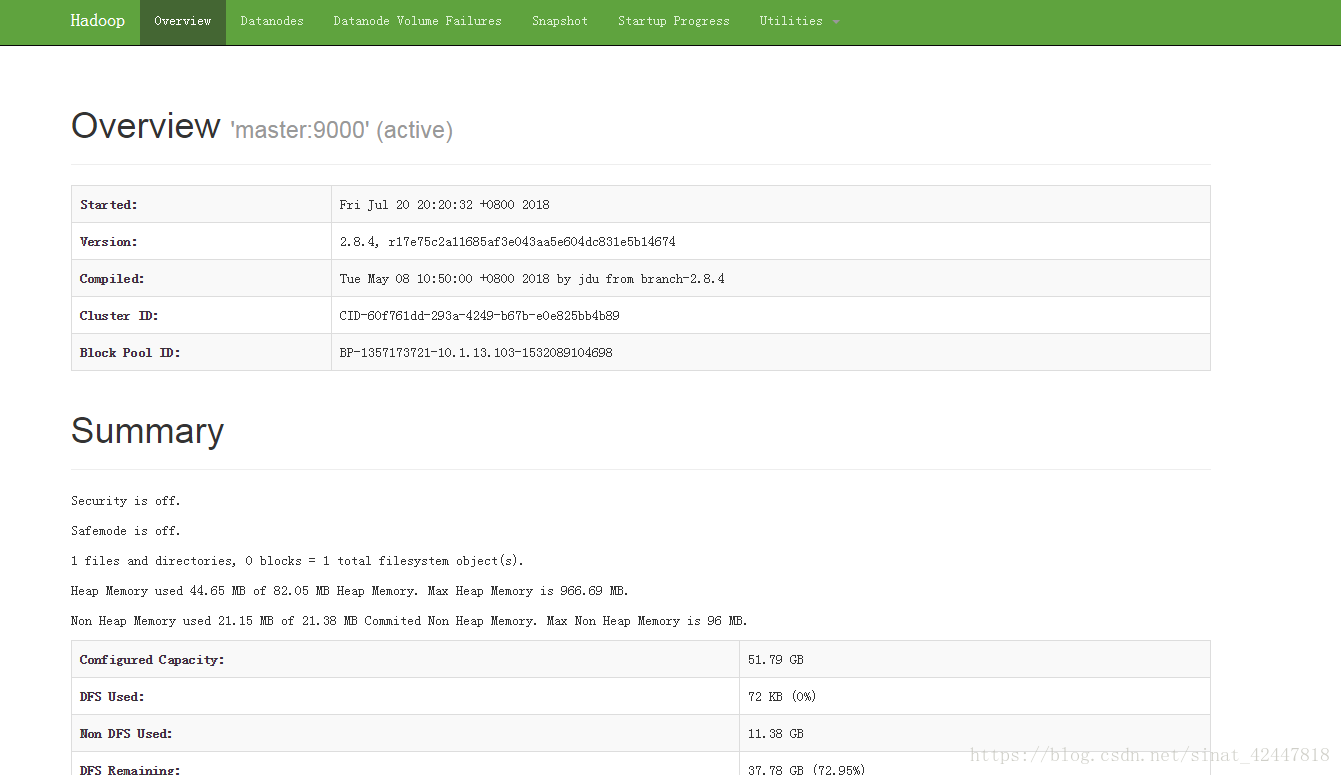
- 测试集群是否可用
- 访问10.1.13.103:50070
- 访问10.1.13.103:8088

- 测试mapreduce来实现对pi的计算
- 进入到/usr/local/hoaddop/shared/hadoop/mapreduce
2、执行
hadoop jar hadoop-mapreduce-examples-2.8.4.jar pi 20 50
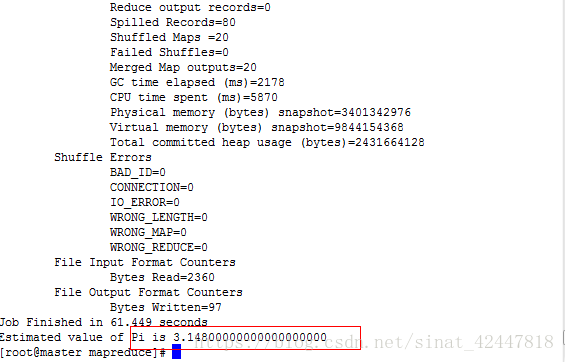
恭喜你成功了:如果你遇到如下问题
1、启动时提示文件不是安全的,可以做如下操作
到hadoop的bin目录下
执行:./hadoop dfsadmin -safemode leave命令。
如果输入hadoop没有提示,那么可以执行 source /etc/profile














 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









