







上节课没讲完的一个案例
优化 limit 分页
在很多应用场景中我们需要将数据进行分页,一般会使用limit加上偏移量的方法实现,同时加上合适的orderby 的子句,如果这种方式有索引的帮助,效率通常不错,否则的化需要进行大量的文件排序操作,还有一种情况,当偏移量非常大的时候,前面的大部分数据都会被抛弃,这样的代价太高。
要优化这种查询的话,要么是在页面中限制分页的数量,要么优化大偏移量的性能
利用子查询,优化一个 limit 分页

例如,原语句:
select * from rental limit 1000000,5;
利用子查询,优化后的语句:(是因为走了索引)
select * from rental a join(select rental_id from rental limit 1000000,5) b on a.rental_id=b.rental_id;
优化union查询
mysql总是通过创建并填充临时表的方式来执行union查询,因此很多优化策略在union查询中都没法很好的使用。经常需要手工的将where、limit、order by等子句下推到各个子查询中,以便优化器可以充分利用这些条件进行优化

行转列可以使用unoin快速实现:

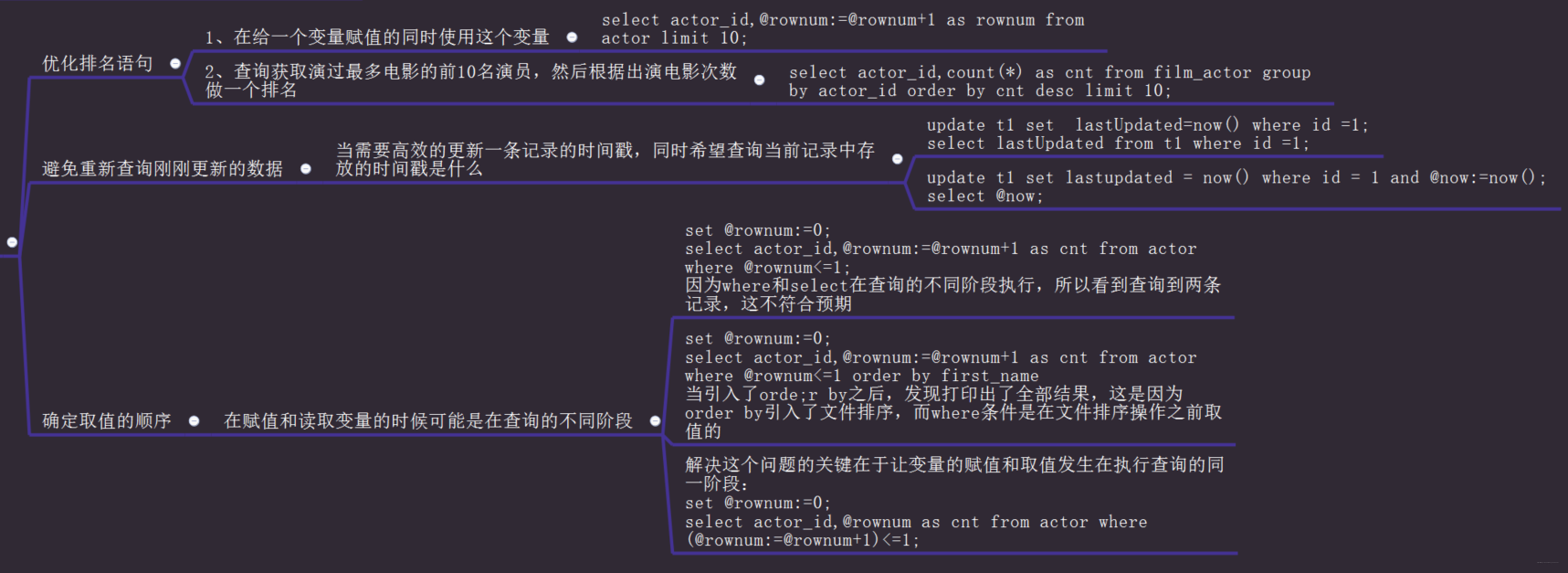
推荐使用用户自定义变量
用户自定义变量是一个容易被遗忘的mysql特性,但是如果能够用好,在某些场景下可以写出非常高效的查询语句,在查询中混合使用过程化和关系话逻辑的时候,自定义变量会非常有用。
用户自定义变量是一个用来存储内容的临时容器,在连接mysql的整个过程中都存在。

自定义变量的使用案例
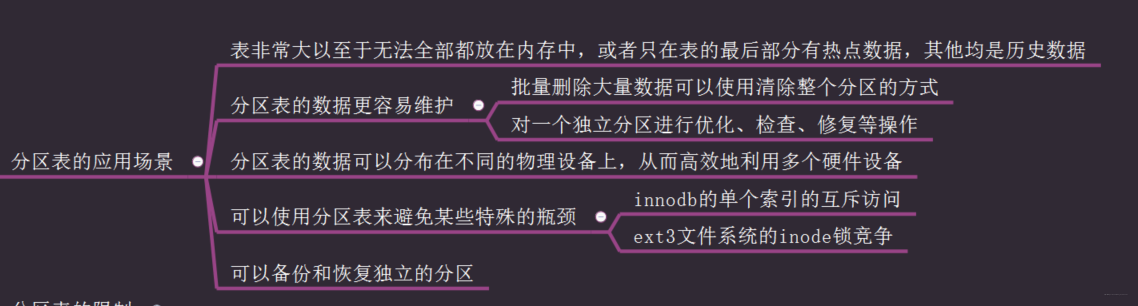
分区表
对于用户而言,分区表是一个独立的逻辑表,但是底层是由多个物理子表组成。分区表对于用户而言是一个完全封装底层实现的黑盒子,对用户而言是透明的,从文件系统中可以看到多个使用#分隔命名的表文件。
mysql在创建表时使用partition by子句定义每个分区存放的数据,在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询就无须扫描所有分区。
分区的主要目的是将数据安好一个较粗的力度分在不同的表中,这样可以将相关的数据存放在一起。
分区表的应用场景
分区表的限制

分区表的底层原理
分区表由多个相关的底层表实现,这个底层表也是由句柄对象标识,我们可以直接访问各个分区。存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引知识在各个底层表上各自加上一个完全相同的索引。从存储引擎的角度来看,底层表和普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
分区表的操作按照以下的操作逻辑进行:
select查询
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据
insert操作
当写入一条记录的时候,分区层先打开并锁住所有的底层表,然后确定哪个分区接受这条记录,再将记录写入对应底层表
delete操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作
update操作
当更新一条记录时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录再哪个分区,然后取出数据并更新,再判断更新后的数据应该再哪个分区,最后对底层表进行写入操作,并对源数据所在的底层表进行删除操作
有些操作是支持过滤的,例如,当删除一条记录时,MySQL需要先找到这条记录,如果where条件恰好和分区表达式匹配,就可以将所有不包含这条记录的分区都过滤掉,这对update同样有效。如果是insert操作,则本身就是只命中一个分区,其他分区都会被过滤掉。mysql先确定这条记录属于哪个分区,再将记录写入对应得曾分区表,无须对任何其他分区进行操作
虽然每个操作都会“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,例如innodb,则会在分区层释放对应表锁。
分区表的类型
这个可以直接到MySQL官网上去看,解释和例子都给的比较清晰。

如何使用分区表
如果需要从非常大的表中查询出某一段时间的记录,而这张表中包含很多年的历史数据,数据是按照时间排序的,此时应该如何查询数据呢?
因为数据量巨大,肯定不能在每次查询的时候都扫描全表。考虑到索引在空间和维护上的消耗,也不希望使用索引,即使使用索引,会发现会产生大量的碎片,还会产生大量的随机IO,但是当数据量超大的时候,索引也就无法起作用了,此时可以考虑使用分区来进行解决
全量扫描数据,不要任何索引
使用简单的分区方式存放表,不要任何索引,根据分区规则大致定位需要的数据为止,通过使用where条件将需要的数据限制在少数分区中,这种策略适用于以正常的方式访问大量数据
索引数据,并分离热点
如果数据有明显的热点,而且除了这部分数据,其他数据很少被访问到,那么可以将这部分热点数据单独放在一个分区中,让这个分区的数据能够有机会都缓存在内存中,这样查询就可以只访问一个很小的分区表,能够使用索引,也能够有效的使用缓存
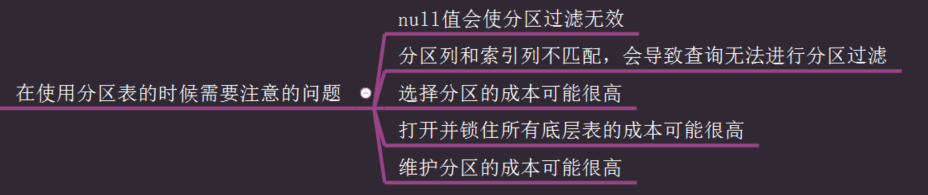
在使用分区表的时候需要注意的问题
范围分区示例
范围分区表的分区方式是:每个分区都包含行数据且分区的表达式在给定的范围内,分区的范围应该是连续的且不能重叠,可以使用values less than运算符来定义。
1、创建普通的表
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
);
2、创建带分区的表,下面建表的语句是按照 store_id 来进行分区的,指定了4个分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3833
3833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









