







本博客为《利用Python进行数据分析》的读书笔记,请勿转载用于其他商业用途。
文章目录
1. 分层索引
分层索引是pandas的重要特性,允许你再一个轴向上拥有多个(两个或两个以上)索引层级。笼统地说,分层索引提供了一种更低维度的形式中处理更高维度数据的方式。例:
data = pd.Series(np.random.randn(9),
index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
data
#
a 1 0.084340
2 1.252705
3 -1.305060
b 1 0.629035
3 -1.099427
c 1 -0.785977
2 -0.524298
d 2 0.144326
3 0.945895
dtype: float64
我们看到的是一个以MultiIndex作为索引的Series的美化视图。索引中的“间隙”表示“直接使用上面的标签”:
data.index
#
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
codes=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]])
通过分层索引对象,也可以成为部分索引,允许你简洁地选择出数据的子集:
data['b']
#
1 0.629035
3 -1.099427
dtype: float64
data['b': 'c']
#
b 1 0.629035
3 -1.099427
c 1 -0.785977
2 -0.524298
dtype: float64
data.loc[['b', 'd']]
#
b 1 0.629035
3 -1.099427
d 2 0.144326
3 0.945895
dtype: float64
在“内部”层级中进行选择也是可以的:
data.loc[:, 2]
#
a 1.252705
c -0.524298
d 0.144326
dtype: float64
分层索引在重塑数据和数组透视表等分组操作中扮演了重要角色。例如,你可以使用unstack方法将数据在DataFrame中重新排列:
data.unstack()
#
1 2 3
a 0.084340 1.252705 -1.305060
b 0.629035 NaN -1.099427
c -0.785977 -0.524298 NaN
d NaN 0.144326 0.945895
unstack的反操作是stack:
data.unstack().stack()
#
a 1 0.084340
2 1.252705
3 -1.305060
b 1 0.629035
3 -1.099427
c 1 -0.785977
2 -0.524298
d 2 0.144326
3 0.945895
dtype: float64
在DataFrame中,每个轴都可以拥有分层索引:
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'],
['Green', 'Red', 'Green']])
frame
#
Ohio Colorado
Green Red Green
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
分层的层级可以有名称(可以是字符串或Python对象)。如果层级有名称,这些名称会在控制台输出中显示:
frame.index.names = ['key1', 'key2']
frame.columns.names = ['state', 'color']
frame
#
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
注意区分行标签中的索引名称’state’和’color’。
通过部分列索引,你可以选出列中的组:
frame['Ohio']
#
color Green Red
key1 key2
a 1 0 1
2 3 4
b 1 6 7
2 9 10
1.1 重排序和层级排序
有时,我们需要重新排列轴上的层级顺序,或者按照特定层级的值对数据进行排序。swaplevel接收两个层级序号或层级名称,返回一个进行了层级变更的新对象(但是数据是不变的):
frame.swaplevel('key1', 'key2')
#
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
另一方面,sort_index只能在单一层级上对数据进行排序。在进行层级变换时,使用sort_index以是的结果按照层级进行字典排序也很常见:
frame.sort_index(level=1)
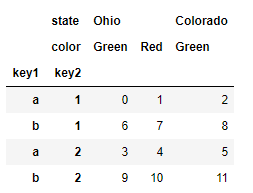
frame.swaplevel(0, 1).sort_index(level=0)
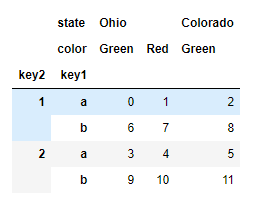
如果索引按照字典顺序从最外层开始排序,那么数据选择性能会更好——调用sort_index(level=0)或sort_index可以得到这样的结果。
1.2 按层级进行汇总统计
通常我们不会使用DataFrame中的一个或多个列作为行索引;反而你可能想要将行索引移动到DataFrame的列中。下面是一个示例:
frame = pd.DataFrame({
'a': range(7), 'b': range(7, 0, -1),
'c': ['one', 'one', 'one', 'two', 'two',
'two', 'two'],
'd': [0, 1, 2, 0, 1, 2, 3]})
frame
#
a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
DataFrame的set_index函数会生成一个新的DataFrame,新的DataFrame使用一个或多个列作为索引:
frame2 = frame.set_index(['c', 'd'])
frame2
#
a b
c d
one 0 0 7
1 1 6
2 2 5
two 0 3 4
1 4 3
2 5 2
3 6 1
默认情况下这些列会从DataFrame中移除,你也可以将它们留在DataFrame中:
frame.set_index(['c', 'd'], drop=False)
#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6613
6613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









