







香蕉派BPI-F3是一款工业级 8核RISC-V开源硬件开发板,它采用进迭时空(SpacemiT) K1 8核RISC-V芯片设计,CPU集成2.0 TOPs AI计算能力。4G DDR和16G eMMC。2个GbE以太网接口,4个USB 3.0和PCIe M.2接口,支持HDMI和双MIPI-CSI摄像头

进迭时空
进迭时空(杭州)科技有限公司是一家成立于2021年11月,专注于高性能RISC-V处理器核、芯片及核心软件系统的创新与研发的企业。公司由一批国内知名的RISC-V处理器技术专家共同发起,并在杭州、珠海、上海、北京、英国等地设有办公地点。进迭时空的核心团队成员来自平头哥、全志等国内知名的半导体企业,拥有丰富的高端芯片研发与商业运营经验。公司旨在推动RISC-V架构的技术发展,其产品广泛应用于边缘计算到云计算等多个场景,包括高端智能机器人、高性能计算盒子、边缘服务器、新一代智能云终端、自动驾驶等。
进迭时空 K1 开源硬件开发板: 香蕉派 BPI-F3
基于RISC-V开放指令集架构,致力于打造更节能、更通用的AI处理器平台,推动全球开源、开放生态计算能力建设。
K1主要用于单板计算机、网络存储、云计算机、智能机器人、工业控制、边缘计算机等。

卓越的CPU性能
8核RISC-V AI CPU,提供50KDMIPS CPU算力和2.0TOPS AI算力
单核CPU算力领先ARM A55 30%以上
强大的向量算力
全球首款支持RVA22 Profile、支持256bit RVV 1.0标准的RISC-V CPU, 提供2倍于Neon的SIMD并行处理算力
通用的AI算力
以CPU核融合方式提供AI算力,实现与所有主流AI生态的快速对接
领先的算力能效
RISC-V架构的精简和卓越的微架构设计,算力能效比ARM A55高20%
丰富的IO能力
集成多套PCIe、USB、GMAC、SPI等接口,提供全面的外设连接选型
符合工业级标准
CPU在-40˚C~85˚C的环境温度下仍能提供稳定可靠的持续算力输出,满足工业应用的苛刻环境需求

基于进迭时空的AI技术路线,以轻量化插件的方式,通过开放的软件栈,使得K1芯片能够在短时间内支持大量开源模型的部署,目前已累计验证了包括图像分类、图像分割、目标检测、语音识别、自然语言理解等多个场景的约150个模型的优化部署,timm、onnx modelzoo、ppl modelzoo等开源模型仓库的支持通过率接近100%,而且理论上我们能够支持所有的公开onnx模型。

作为进迭时空首颗自研高性能计算芯片,K1芯片除了在AI方面取得了突破性成果,在包括存储性能、计算性能、浮点性能等芯片的三个核心性能上,相较ARM同级别的Cortex-A55
芯片也都取得代差级优势。
同等微架构下,存储性能大幅领先于ARM Cortex-A55
芯片存储的速度越快,计算机的运行速度也就越快,这也意味着能够更快地访问和处理数据,缩短反应时间,对于需要高效数据交换的AI终端应用场景来说,尤为重要。陈志坚博士介绍,在存储性能方面,同等微架构下,K1芯片搭载的进迭时空自研RISC-V 智算核X60™表现亮眼,大幅领先ARM Cortex-A55 15%。其中,LMbench Write单项来看,最高可达6.32GB每秒,LMbench Copy和Read,分别可达3.35GB每秒和3.56GB每秒,远超ARM Cortex-A55的读写和复制速度。此外,X60智算核在内存stream方面的各项指标也远超ARM Cortex-A55。
同等微架构下,计算性能大幅领先于ARM Cortex-A55
在各大领域的真实应用中,X60™智算核的实际计算性能也大幅领先ARM Cortex-A55。在相同工艺下,X60™智算核单位频率的性能大幅领先,这来自于之前提到的出色的各项传统CPU的性能,也来自于X60™智算核基于RISC-V Vector的强大SIMD性能。图像性能方面,最高为ARM Cortex-A55图像性能的2.14倍,压缩性能的1.2倍,绘制性能的1.19倍。
提高芯片的计算性能,也可以通过提高数据并行性能来实现。这种能力也被称为向量计算能力。事实上,AI大模型推理涉及大量的向量运算和矩阵运算,利用处理器的向量指令功能,能够加快模型的推理速度。
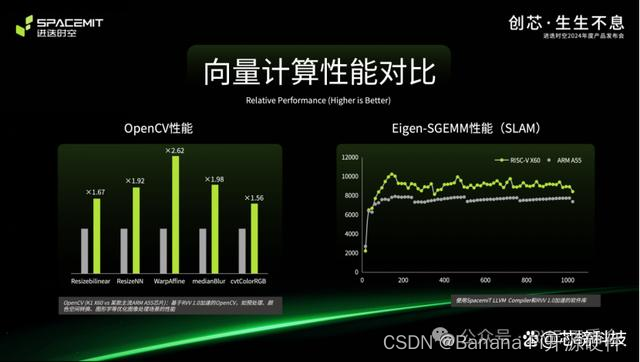 据发布会公布的数据显示,基于RISC-V Vector 1.0标准,X60™智算核可以提供2倍于ARM Neon的256-bit SIMD并行处理算力。相比Arm Neon指令集能在多个领域的应用情况和带来的性能提升。在图像预处理、颜色空间转换、图形学等算法性能上,X60™是ARM Cortex-A55的1.5倍。此外,进一步在LU分解,QR分解,SVD分解,Chelesky分解,Eigen分解等五大矩阵进行分解后,基于在OpenBLAS+Eigen,核心计算,sgemm的性能上的突出表现,X60智算核是ARM Cortex-A55的1.5倍。更为重要的是,X60智算核的向量计算技术,还解决了SIMD技术带来的二进制不兼容问题,使同一份代码可以跑在基于RISC-V架构的任何矢量位宽的处理器上,开发者不需要经历ARM指令集扩展和代码重写,这意味着软件维护成本将大大降低,对RISC-V生态的建设具有重大意义。
据发布会公布的数据显示,基于RISC-V Vector 1.0标准,X60™智算核可以提供2倍于ARM Neon的256-bit SIMD并行处理算力。相比Arm Neon指令集能在多个领域的应用情况和带来的性能提升。在图像预处理、颜色空间转换、图形学等算法性能上,X60™是ARM Cortex-A55的1.5倍。此外,进一步在LU分解,QR分解,SVD分解,Chelesky分解,Eigen分解等五大矩阵进行分解后,基于在OpenBLAS+Eigen,核心计算,sgemm的性能上的突出表现,X60智算核是ARM Cortex-A55的1.5倍。更为重要的是,X60智算核的向量计算技术,还解决了SIMD技术带来的二进制不兼容问题,使同一份代码可以跑在基于RISC-V架构的任何矢量位宽的处理器上,开发者不需要经历ARM指令集扩展和代码重写,这意味着软件维护成本将大大降低,对RISC-V生态的建设具有重大意义。
同等微架构下,浮点运算能大幅领先于ARM Cortex-A55
浮点运算能力是芯片在进行浮点计算时的速度和精确度,对于Robot Computer时代里高强度的科学计算和图型处理等密集运算的应用程序来说,浮点性能尤为关键。
陈志坚博士介绍,进迭时空随机抽取的18个应用程序进行实测后,测试结果显示,X60™智算核在14个应用程序的运行数据都大幅领先于ARM Cortex-A55。其中,在X60™智算核上运行从头计算量子化学程序GAMESS,是ARM Cortex-A55的12.2倍,称得上“遥遥领先”。
下一步工作
面向未来,进迭时空将持续投入 RISC-V 高性能 CPU 核、高性能 CPU 芯片、基础和系统软件研发,形成完整计算系统解决方案:
第二代 RISC-V 高性能 CPU 核“X100”研发完毕,采用 12 级流水线和 4 发射乱序执行的超标量处理器架构,通用计算性能Coremark 达到 7.7/MHz,Spec2k6 超过 8.2/GHz,在 12nm 工艺下频率可达到 2.5GHz。同时完整符合服务器规格要求,是全球首款同时支持完整虚拟化、RAS 特性、安全、标准向量扩展、向量加解密、64 核互联的 RISC-V CPU 核,获得中国开放指令生态(RISC-V)联盟 2023 年度唯一的前沿创新奖。
搭载“X100”核的下一代 RISC-V AI CPU 芯片已启动研发,未来将继续拓展 RISC-V 在高性能计算领域的边界,成为新的标杆级别的量产 CPU 芯片产品。
同时进迭时空作为中电标协 RISC-V 工委会副会长单位,全球 RISC-V生态软件计划“RISE”会员单位等,将继续携手业界共建 RISC-V 应用生态。
进迭时空表示,坚信 RISC-V 是下一个机器人时代最佳的计算架构,RISC-V让中国企业有机会从指令集和 CPU 核开始做芯片和计算系统的软硬件融合优化,为世界交付具有代差级优势的芯片产品,在中国会诞生出具有全球影响力的 CPU 芯片企业。
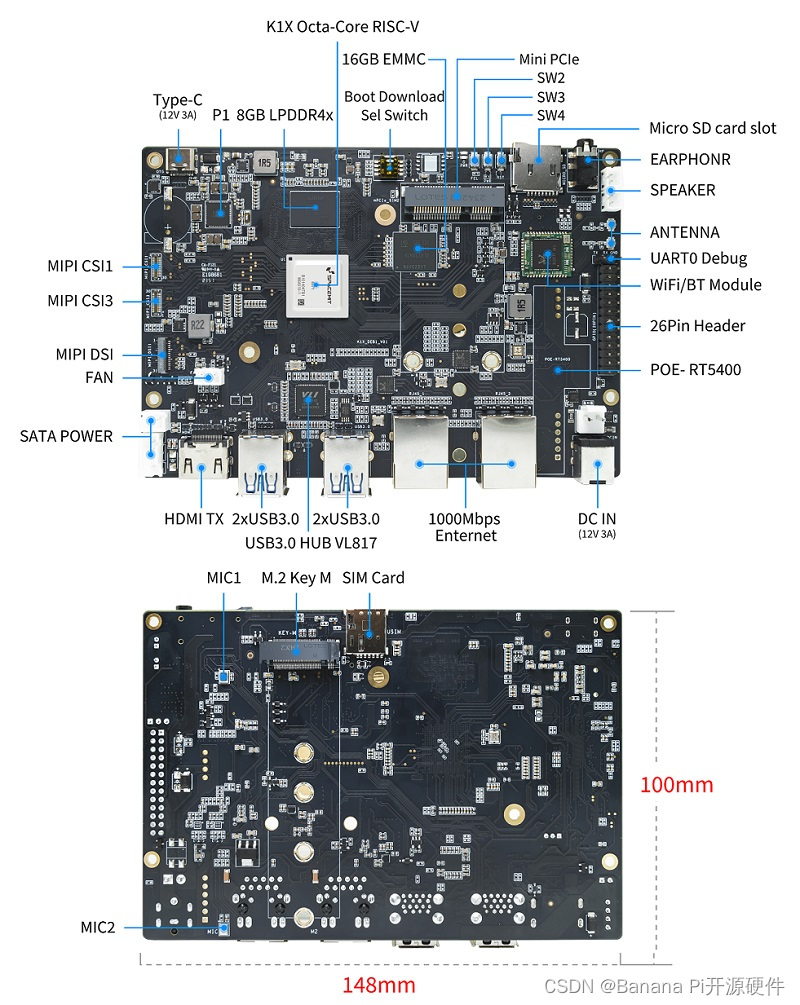
BPI-F3 ,接口齐全的RISC-V开发板

丰富的硬件接口:
在线文档:https://docs.banana-pi.org/zh/BPI-F3/BananaPi_BPI-F3














 3488
3488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









