








摘要
- 主要思想:区别于现有方法中大多在LR图像上一点点增加细节,PULSE(Photo Upsampling via Latent Space Exploration)遍历HR自然图像的流形空间,找到下采样后为原始LR图像的HR自然图像。
- PULSE方法是完全自监督的。
- 所提出的方法可以基于任何的下采样形式(即不局限于下三次采样的特定倍数等)
一、介绍
-
生成一组潜在的HR图像与超分的目标是不相符的,原因在于生成的图像集合的大小随比例因子指数级增长。这样会导致多幅HR图像对应一幅LR图像的结果。
-
已有的超分方法多采用在SR图像和HR图像之间优化MSE loss的方式,但MSE会将图像的细节区域同时模糊掉,因此不应该只采用MSE进行超分效果的度量。
-
为了避免MSE及相关拓展方法对于图像细节部分的模糊,本篇文章提出了一种新的超分模式。目的在于找到实际位于自然图像流形空间上的图像,并且保证找到的图像可以正确下采样为提供的原始LR图像。
-
本文中提出的方法采用预训练好的生成模型去拟合自然图像的分布特征,对于给定的LR图像,我们遍历流形空间,根据生成模型的潜在空间参数化,找到可以正确下采样为所给LR图像的空间区域。(?)
这种方法的可以实现完全的自监督学习,其好处在于:- 其允许在没有相应LR-HR对数据库的情况下,对不同下采样因子的图像使用相同的网络。
- 其不需要设置一个进行超分的特定网络(超分任务与生成模型一同进行)
-
文章提出的方法框架中可以使用任何带有可微分生成器的生成模型,eg:VAEs,GANs,本文中采用的是GAN。
-
文章的主要贡献:
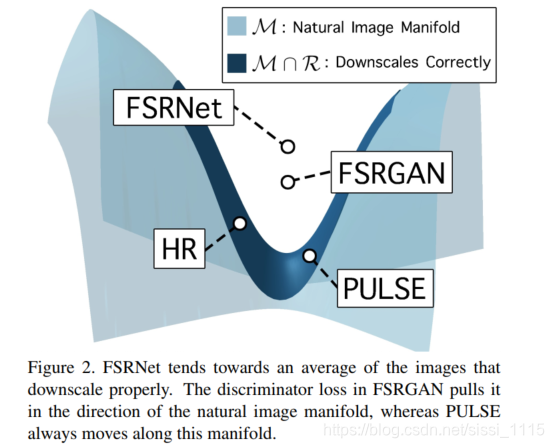
- 一种图像超分的新示例:以往方法中根据LR图像重建HR图像的方式实际上是平均了多个生成的可能结果,这种平均给结果带来了模糊。而本文提出的新方法将生成真实的HR图像,并保证其可以下采样为给定的LR图像。
- 一种解决超分的新方法:本文提出的方法采用styleGAN模型,在潜在空间中找到映射到真实图像以及下采样正确的区域。
- 一种基于高维高斯先验的潜在空间的原始搜索方法:我们的任务希望在生成模型的潜在空间中找到可以映射到现实输出的点,由于肥皂泡效应(大部分高维高斯密度的分布靠近超球面的表面),而传统的对数似然正则化则倾向于将潜在的向量从超球面移向原点。因此,我们将搜索空间限制在超球面的表面,这样做保证了高维潜在空间的真实输出,否则的话,这些空间将很难搜索。(?)
二、相关工作
目前基于CNN的超分方法都基于同一个pipeline:通过下采样HR图像得到的LR图像,被喂进由卷积层和上采样层构成的CNN网络中,生成SR图像,根据所选择的损失函数以及原始的HR图像计算损失。
2.1 当前的趋势
有监督的神经网络称为超分任务的主流,除此之外,ResNet也使得在处理任务时我们可以训练更为庞大的网络。
目前两个主要趋势有:一、优化SR和HR间的像素平均距离。二、重点在感知质量。
2.2 损失函数
2.3 生成式对抗网络GAN
本文采用的是一种完全无监督的GAN进行训练,它在生成模型上寻找潜在空间中可以映射到真实图像且可以正确下采样得到原始LR图像的点。
三、实现方法
目标:学习一个生成器G,当其应用于LR图像时,可以产生一个更高分辨率的超分图像SR
I
S
R
=
S
R
(
I
L
R
)
I_{SR}=SR(I_{LR})
ISR=SR(ILR)
即最小化
L
=
∣
∣
I
H
R
−
I
S
R
∣
∣
p
p
L=||I_{HR}-I_{SR}||_p^p
L=∣∣IHR−ISR∣∣pp
令R为可以正确下采样到LR图像的图像集合:
R
=
I
∣
D
S
(
I
)
=
I
L
R
R={I|DS(I)=I_{LR}}
R=I∣DS(I)=ILR
则当产生SR图像时生成的loss为:
∫
M
∩
R
∥
∣
I
H
R
−
I
S
R
∣
∣
p
p
d
P
(
I
H
R
)
\int_{M\cap R} \||I_{HR}-I_{SR}||_p^p\, dP(I_{HR})
∫M∩R∥∣IHR−ISR∣∣ppdP(IHR)
因此,最佳的ISR是一组可以正确下采样的HR图像的加权像素平均值。
针对上述思想,本文给出了一种新的单图超分框架:
R
ϵ
=
I
∣
∣
D
S
(
I
)
−
I
L
R
∣
∣
p
p
<
=
ϵ
R_\epsilon={I||DS(I)-I_{LR}||_p^p<=\epsilon}
Rϵ=I∣∣DS(I)−ILR∣∣pp<=ϵ
即
R
ϵ
R_\epsilon
Rϵ就是可以正确下采样的图像集合。
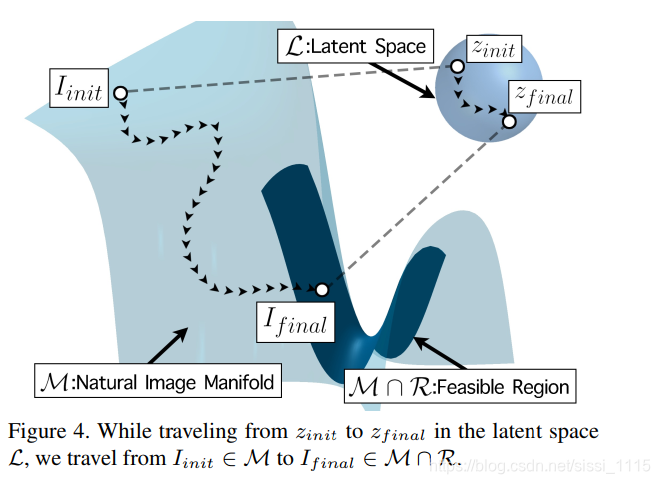
接下来我们继续寻找
I
S
R
∈
M
∩
R
ϵ
I_{SR}\in M\cap R_\epsilon
ISR∈M∩Rϵ,也就是一组既真实又可以正确下采样的图像。
3.1 降维损失
传统的超分方法没办法保证SR图像接近现实图像的流形空间,而本文提出的方法由于一直在M空间中进行计算,因此不需要对这一点进行损失度量。
本文方法需要计算损失的是生成的SR图像与LR图像的相关程度。
L
D
S
(
I
S
R
,
I
L
R
)
=
∣
∣
D
S
(
I
S
R
−
I
L
R
∣
∣
p
p
L_{DS}(I_{SR},I_{LR})=||DS(I_{SR}-I_{LR}||_p^p
LDS(ISR,ILR)=∣∣DS(ISR−ILR∣∣pp
注意:降维损失可以用于监督或非监督模型,因为其不基于参考HR图像。
3.2 潜在空间搜索
为了找到区域M,令其可以正确降维为LR图像,我们需要一个可微的流形,沿着流形的微分通过降维损失就可以找到相应的空间区域。
在本文中将采取自主无监督学习的方法近似这样的流形可微性。
除此之外,我们还需要使得所选出来的响亮尽可能的处于一个高概率密度(?)的区域,针对这个想法,我们需要对先验信息的负对数增加一个损失项。
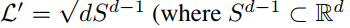
这将问题从整个潜在空间的梯度下降到投影后的超球面上。
四、实验
- styleGAN使用karras开源的ffhq预训练网络
- 对于每张图像,使用100次球状梯度下降,学习率0.4,latent随机初始化
- data:CelebA HQ(因为CelebA分辨率低)
- 用来比较的SOTA:用CelebA HQ训练的,因为用FFHQ训练的效果非常差
- 对比方法:bicubic upsampling, FSRNet, FSRGAN,pulse(×8), pulse(×64)
六、Bias
PULSE方法在对于有色人种输入时,输出仍为白人。(styleGAN方法的纰漏)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









