








我认为是需要去学习的,不是说全部都要去学一遍,但起码前端至少要会看,能看懂前端代码。
爬虫它本质就是利用程序模拟各种网络请求然后获取网页里面的信息,如果看不懂网页源码是无法做好一个爬虫的。
要是想深入学习爬虫,肯定绕不过前端的知识,html+css+javascript更是其中的基础知识了。
全栈的话这个概念太大了,能大概了解一点当然是更好,爬虫就是和这些打交道。

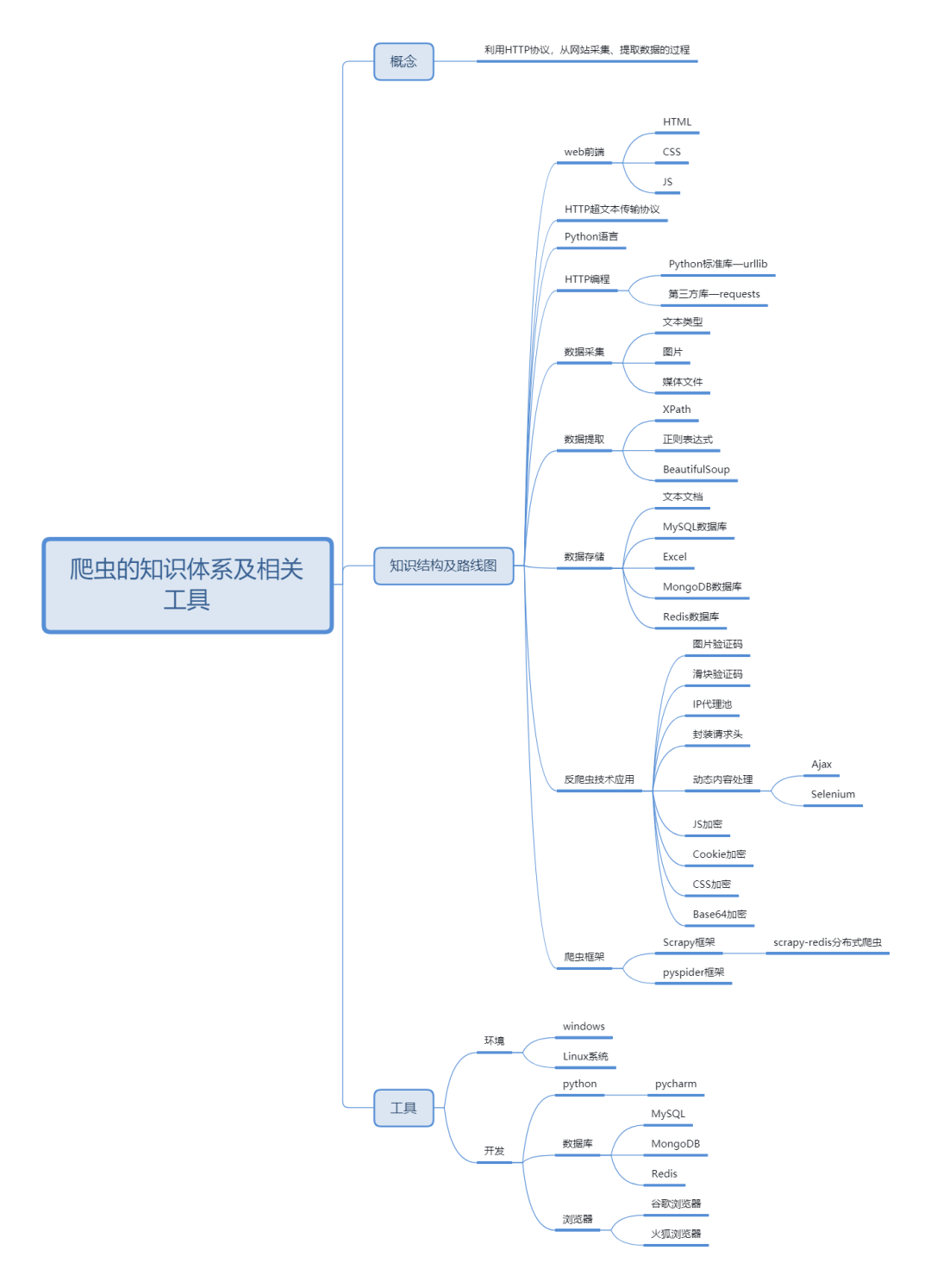
01 爬虫技术掌握
做爬虫需要掌握的技术有下面几个:
① HTTP必须要有很深刻的理解,这是你纵横网络的立身之本
② BeautifulSoup、xpath这些都是基础操作了,一定要做到非常熟练
③ Scrapy框架要会用,要能信手捏来写个分布式爬虫
④ Webdriver、Selenium、PhantomJS也要会使用
所以想要入门Python 爬虫,首先先解决四个问题:
(1)熟悉Python编程
(2)了解HTML
(3)了解网络爬虫的基本原理
(4)学习使用python爬虫库
02 基础语言:Python编程
-
首先下载python的版本;
Python2跟python3怎么选?
个人建议Python3,毕竟Python3是未来的方向,现在多数的学习教程都已经更新到了Python3。
当然这也不是强求一定要选Python3,可以结合自己的需求来选。
-
选择适合自己的开发工具;
python常用的开发工具有:pycharm、Visual Studio Code、Sublime Text、anaconda,但是比较推荐使用pycharm。
-
最后项目练习;
可以在网上找一些实操网站,练一练项目,实验楼、Github、开源中国这几个网站,优质的练手项目很多,可以自己去找找。
可以跟着写一些python小项目案例,来提高自己的编程能力。
-
基础实战:
-> 文件的基本操作
-> 异常处理的解决方式
-> 熟练库的安装使用
-> 能看懂简单的报错信息,知道如何排查错误
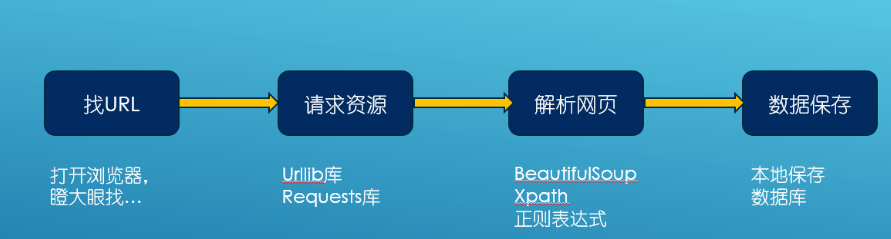
03 爬虫四步
网络爬虫,其实叫作网络数据采集更容易理解。
就是通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。
-
根据url获取HTML数据
-
解析HTML,获取目标信息
-
存储数据
-
重复第一步
一般爬虫会涉及到,数据采集,数据清洗,数据存储,数据展示等。
如果说涉及前端部分的内容就是数据展示部分,将你爬去的数据进行展示在网页中让人直观的看。
但是在Python中会有相同的库作为替换,所以你可以不用学习前端知识也能完成这个目的。
如果说涉及后端部分的内容就是数据的存储,把你当爬虫数据存储到数据库中。
这一步你也可以有替代方案,把数据存储在txt文件中,excel文件中都是可以的,这样你就不用花费时间专研数据库等后端知识。
最后,数据采集部分;
会涉及一些网络知识,但是现在的Python第三方库已经很成熟,你很多只要查看文档理解如何用即可。初期不用探究底层原理,也能够完成你的数据采集工作。
数据清洗,就是通过Python变成语言来进行操作,找到你需要的内容,这部分就是主要你来完成和学习的编程内容了。
04 几个常用的爬虫类库
Urllib
urllib是python中请求url链接的标准库,无需安装,直接可以用。
并且提供了如下功能:网页请求、响应获取、代理和cookie设置、异常处理、URL解析;
如果想系统性的学习urllib库,可以直接看它的官方文档。
主要包含以下几个模块:
-
urllib.request:用于打开和阅读URL
-
urllib.error:包含由引发的异常urllib.request
-
urllib.parse:用于解析URL
-
urllib.robotparser:用于解析robot.txt文件
其中urllib.request,urllib.error两个库在爬虫程序中应用比较频繁。
Request
使用 Request 伪装成浏览器发起 HTTP 请求;
如果不设置 headers 中的 User-Agent,默认的User-Agent是Python-urllib/3.5。
可能一些网站会将该请求拦截,所以需要伪装成浏览器发起请求。
我使用的 User-Agent 是 Chrome 浏览器
import urllib.request
url = "http://tieba.baidu.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))-
Request 高级用法
如果我们需要在请求中添加代理、处理请求的 Cookies,我们需要用到Handler和OpenerDirector。
(1)Handler
Handler 能处理请求(HTTP、HTTPS、FTP等)中的各种事情;
它的具体实现是这个类 urllib.request.BaseHandler;它是所有的 Handler 的基类,其提供了最基本的Handler的方法。
例如default_open()、protocol_request()等;
继承 BaseHandler 有很多个,我就列举几个比较常见的类:
-
ProxyHandler:为请求设置代理
-
HTTPCookieProcessor:处理 HTTP 请求中的 Cookies
-
HTTPDefaultErrorHandler:处理 HTTP 响应错误。
-
HTTPRedirectHandler:处理 HTTP 重定向。
-
HTTPPasswordMgr:用于管理密码,它维护了用户名密码的表
-
HTTPBasicAuthHandler:用于登录认证,一般和 HTTPPasswordMgr 结合使用。
(2) OpenerDirector
对于 OpenerDirector,我们可以称之为 Opener。
实际上它就是 urllib 为我们提供的一个Opener,那 Opener 和 Handler 又有什么关系?
opener 对象是由 build_opener(handler) 方法来创建出来;
我们需要创建自定义的 opener,就需要使用 install_opener(opener)方法。
值得注意的是,install_opener 实例化会得到一个全局的 OpenerDirector 对象。
Beautiful Soup
BeautifulSoup4是爬虫必学的技能;
BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
灵活方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式,即可方便地实现网页信息的提取。
Beautiful Soup支持的解析器

Python为我们提供了主要是lxml、Beautiful Soup、pyquery等解析库,当然了,还有re。
这四个库的比较呢:
-> 如果你的前端基础比较扎实,用pyquery是最方便的
-> Beautiful Soup这个库,对于爬虫初学者来说,强力推荐这个库
-> re速度比较快,但是写正则比较麻烦
-> lxml的速度也是相对较快的,建议使用
Re正则表达式
是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式。
是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
它的作用在于:
1、从字符串中匹配满足某种规则的内容,多数用于爬虫应用程序。
2、字符串内容是否满足某种规则,多用于验证用户输入。例如密码是否规范,手机号是否正确等。
这几种库都是比较常见的解析库,新手小白不必全部都精通。
能够熟练一两种解析库的使用就可以了,足以应付入门阶段的一般爬虫数据的抓取了。
Scrapy
Scrapy是一个专业高效的爬虫框架;
它使用专业的Twisted包高效的处理网络通信,使用lxml(专业的XML处理包),cssselect 高效的提取HTML页面的有效信息,同时也提供了有效的线程管理。
可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
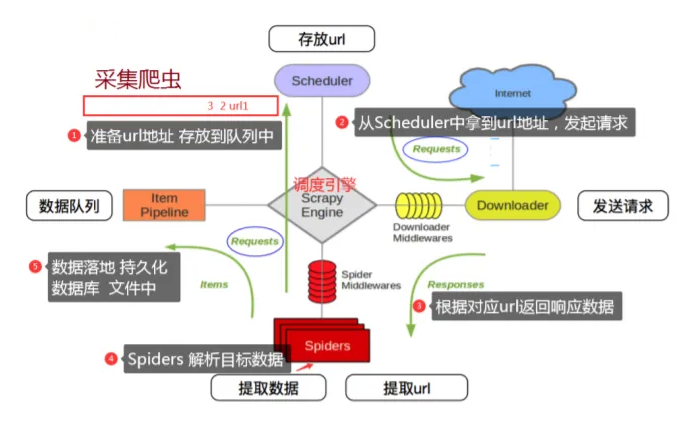
结构:5+2 结构
5个模块分别是:
engine模块 + spiders模块(框架入口)+ scheduler模块+ downloader模块+ item pipelines(框架出口)模块
2个中间件分别是:
spiderMiddleware 和 downloaderMiddleware
3条数据流路径:
1️⃣ spiders模块经过engine模块到达scheduler模块(request请求)
2️⃣ scheduler模块通过engine模块 到达downloader模块, 将数据返回给spider模块
3️⃣ spider模块通过engine模块分别达到item pipelines模块 和 scheduler模块
Scrapy是非常主流的爬虫框架,写爬虫还不会Scrapy,你就out啦!
05 小 结
其实爬虫只要你会了以下这几步,大部分爬虫就没有问题了。
但是!这里有个但是!
如果你遇到了一个网站,反爬做的很厉害,那你就需要去想象做了哪些限制,然后对限制进行模拟。
这个时候,就需要一些前端的知识了,有时你甚至需要去读页面的JS方法,尝试理解反爬的思路并做出相应的调整。
其实爬虫的门槛不高,只要你能够正常的使用浏览器进行网络操作,就已经可以尝试去写一些简单的爬虫了。
如果要做一个高可用高并发快速的爬虫,那就需要更多的关于多线程分布式等等的知识了。关注gzh【Python编程学习圈】学习更多Python技术知识,内容详细丰富,还有大量干货资料可以免费领取,福利满满!
一些特定的网站还是需要具备一些专业知识的,所以技术层面上的东西多学点总是好的。















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









