








每到年底,都有很多同学在各种社交平台晒出自己的年度报告,听了多少歌、什么时段听....
在大数据面前,每个人都成了透明人一样。虽然可怕,但是也已经习以为常。
大多数歌曲爱好者在Spotify上听歌,它是最受欢迎的歌曲流媒体平台之一。
如果你是一个程序员,那么你知道如何建立代码和歌曲之间的关系吗?
今天,就来给大家介绍一下。
编码和分析
导入下列工具包:
#for mathematical computation
import numpy as np
import pandas as pd
import scipy.stats as stats
#for data visualization
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import plotly
import plotly.express as px
% matplotlib inline
让我们加载数据看一下。
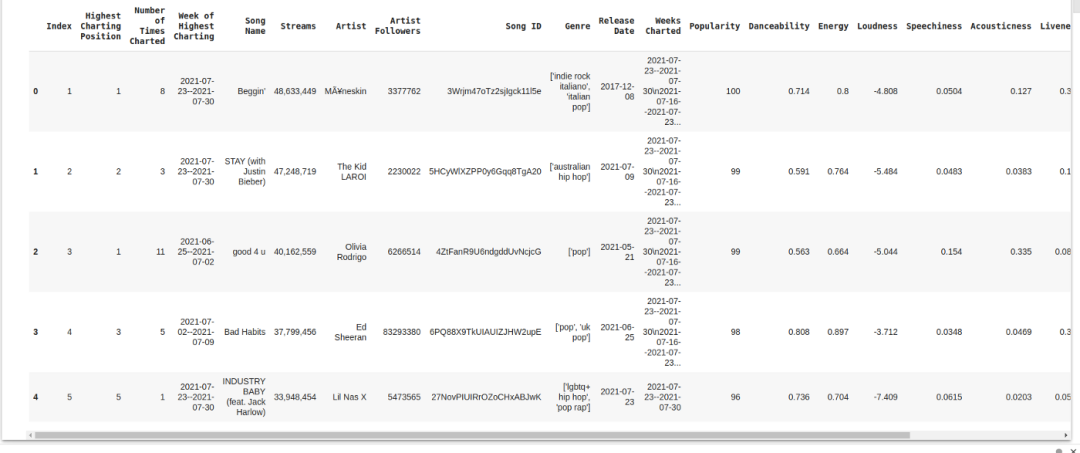
下载数据集并将其添加到路径中,然后,读取数据集的前5个数据:
df = pd.read_csv("/content/spotify_dataset.csv", encoding='latin-1')
df.head()
现在运行这段代码,你会在屏幕上看到类似下图这样:
读取数据更多信息:
#data info
df.info()
#Check missing values
df.isnull().sum()
看看每一列中的空值。我们很幸运,在我们的数据集中没有空值。
之后,用每一列属性的类型来获取我们的数据集的更多信息:
歌手上榜次数
#number of times charted by artist
df_numbercharted=df.groupby('Artist').sum().sort_values('Number of Times Charted', ascending=False)
df_numbercharted=df_numbercharted.reset_index()
df_numbercharted
对于这一点,我们取一个歌手,将其上榜次数相加,并将每个人按降序排列:
px.bar(x='Artist', y='Number of Times Charted', data_frame=df_numbercharted.head(7), title="Top 7 Artists with Highes Number of Times Charted")
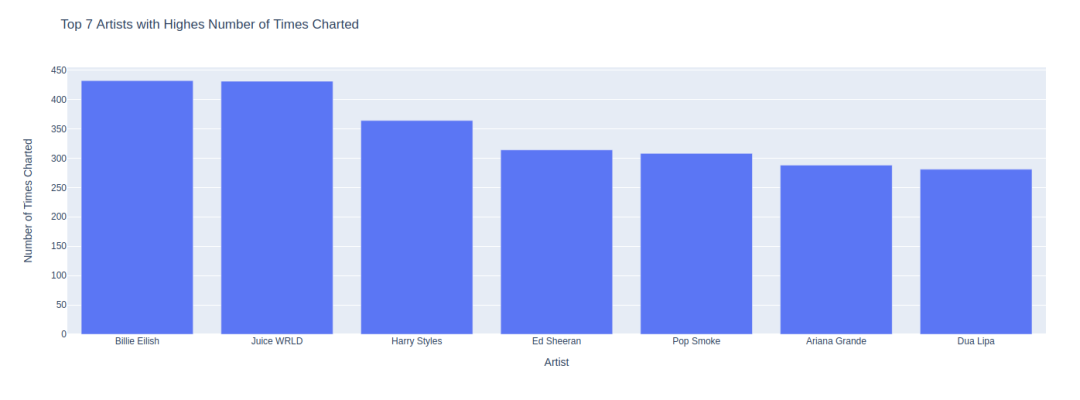
当你运行代码时,你会看到类似上面的图片。
Billie Elish在上榜次数最多的名单中名列前茅。上面的柱状图只有前7名歌手,你可以查看前10名或更多艺术家的情况,只要试着玩玩代码就可以了。
最近我花费了几天的时间,整理了1份理论+实践的Python入门进阶教程,这或许是你见过非常好的一份学习资料之一。独家打造、完全免费,需要的同学可以关注gzh【Python编程学习圈】,发送“学习资料”获取~
列之间的相关性
让我们看看各列之间的相关性,并检查我们是否能发现任何有趣的东西。
为此,让我们首先清理我们拥有的数据。之后,将所有的列转换为数字。
#clean data first
df=df.fillna('')
df=df.replace(' ', '')
df['Streams']=df['Streams'].str.replace(',','')
#convet all numeric columns to numeric
df[['Highest Charting Position', 'Number of Times Charted', 'Streams', 'Popularity', 'Danceability', 'Energy', 'Loudness', 'Speechiness',
'Acousticness', 'Liveness', 'Tempo', 'Duration (ms)', 'Valence',
]] = df[['Highest Charting Position', 'Number of Times Charted', 'Streams','Popularity', 'Danceability', 'Energy', 'Loudness', 'Speechiness',
'Acousticness', 'Liveness', 'Tempo', 'Duration (ms)', 'Valence',
]].apply(pd.to_numeric)
让我们也把年份从 "发布日期 "这一栏中分离出来,以便能够分析其相关性:
df['Release Year'] = pd.DatetimeIndex(df['Release Date']).year
现在,绘制热力图:
%matplotlib inline
f,ax = plt.subplots(figsize=(14,10))
sns.heatmap(df.corr(),annot = True,fmt = ".1f",ax = ax)
plt.show()
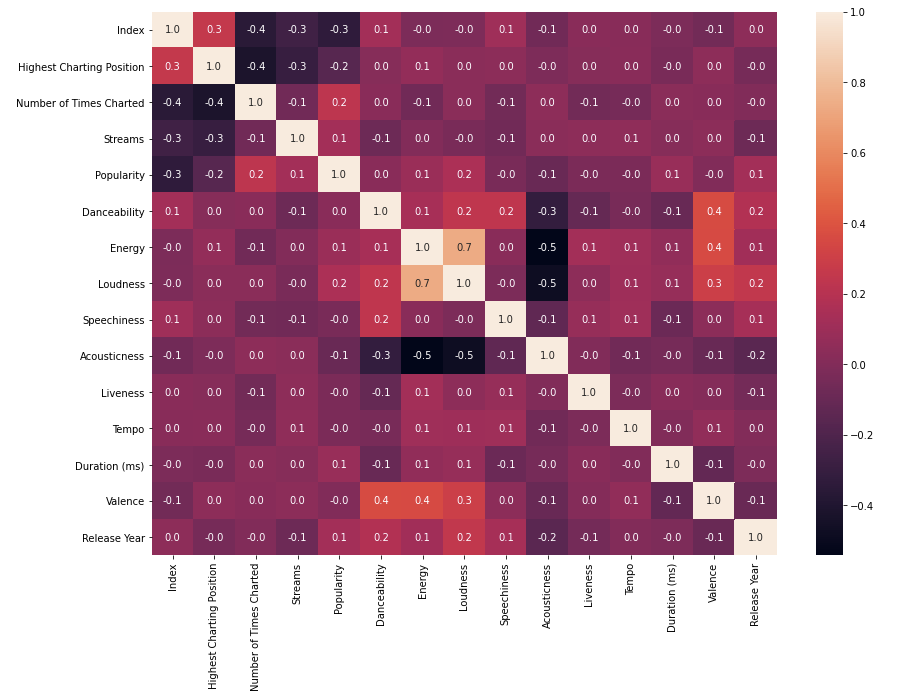
我们都知道,原声音乐往往是安静的,需要仔细聆听。
这就是为什么它与能量和响度呈负相关的原因,这很有意义。
现在,在代码中,"annot"被用来显示立方体中的数字。"fmt"用于数字,如果你设置fmt="0.2%",那么在立方体中数字将以百分比的形式出现,并有2位小数。
很明显,我们不希望这样,因为它使可读性变得模糊。
舞蹈性
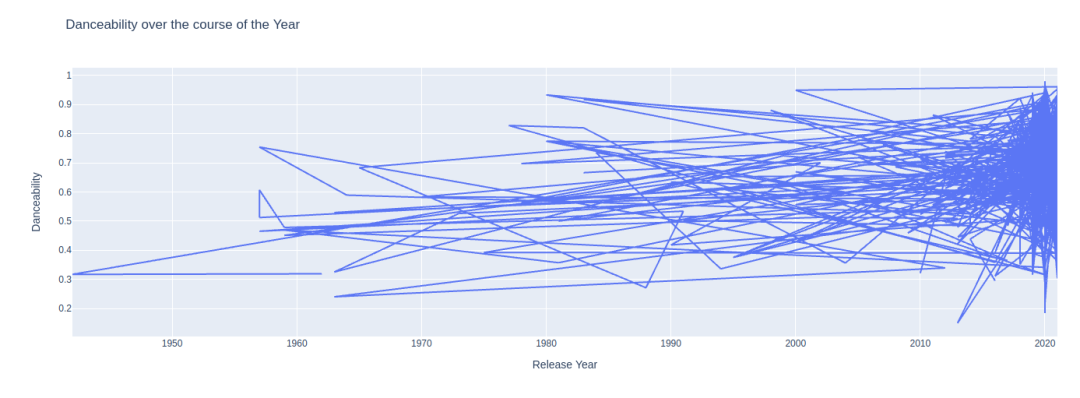
px.line(x='Release Year', y='Danceability', data_frame=df, title="Danceability over the course of the Year")
现在,看看这些年来舞蹈性是如何变化的。
当你执行上面代码时,你会在图示看到这样的东西。
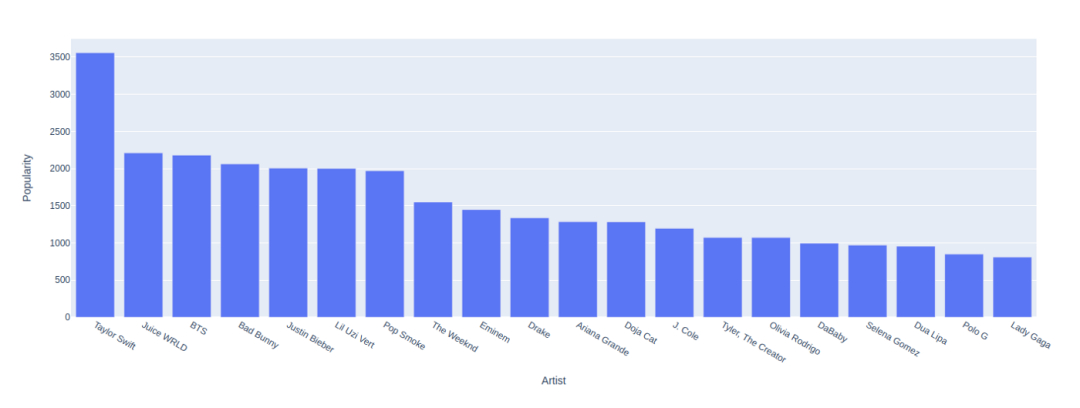
20位最受欢迎的歌手
artistbypop = df.groupby('Artist').sum().sort_values('Popularity' ,ascending=False)[:20]
artistbypop=artistbypop.reset_index()
#plot the graph
px.bar(x='Artist', y='Popularity', data_frame=artistbypop)
在这里,我根据受欢迎程度对艺术家进行排序。Taylor Swift位居榜首,其次是Juice WRLD和其他人。
最受欢迎的流派
df['Genre']=df['Genre'].astype(str)
df["Genre"][df["Genre"] == "[]"] = np.nan
df["Genre"] = df["Genre"].fillna(0)
#here we get rid of useless symbols to be able to separate genres
df.Genre=df.Genre.str.replace("[", "")
df.Genre=df.Genre.str.replace("]", "")
df.Genre=df.Genre.str.replace("'", "")
#now we devide genre strings by comma
df["Genre"] = df["Genre"].str.split(",")
df=df.explode('Genre')
df
首先,我们去掉无用的符号,以便能够分开流派。
之后,用逗号划分流派字符串。
下一个命令是根据流派来分离行,每首有多于一个流派的歌曲将有多行,每行有一个流派。
例如,如果一首歌曲有2个流派,那么同一首歌将有2行,每行有不同的流派。
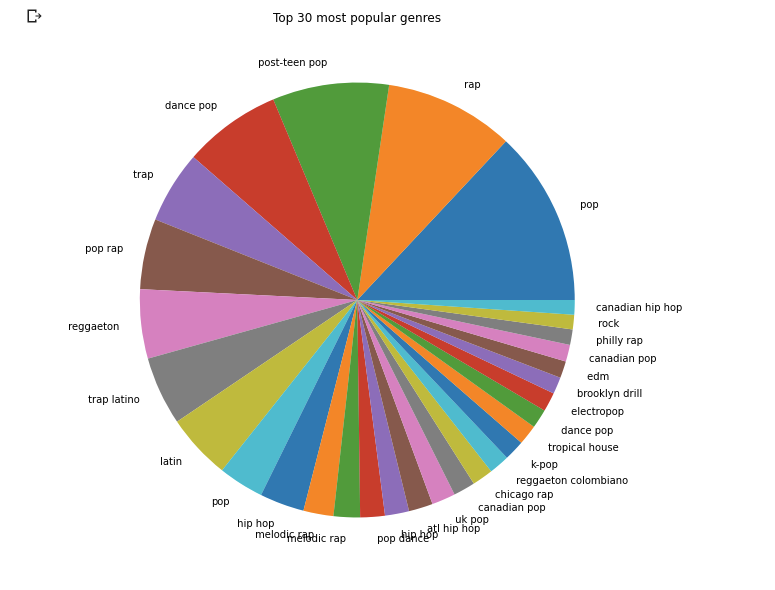
现在简单地绘制30种最受欢迎的流派的饼图:
fig = plt.figure(figsize = (10, 10))
ax = fig.subplots()
df.Genre.value_counts()[:30].plot(ax=ax, kind = "pie")
ax.set_ylabel("")
ax.set_title("Top 30 most popular genres")
plt.show()
好了,就这样吧。到这里,已经分析了Spotify的数据集。
你可以自己去挖掘更多自己感兴趣,或者对自己有价值的信息。















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









