







print(s4[1:4])
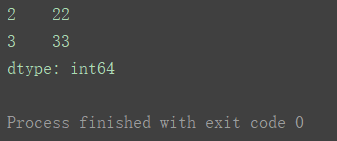
Series对象有index和value属性,可直接调用进行查看。
import pandas as pd
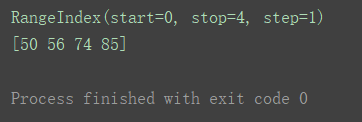
s1 = pd.Series([50, 56, 74, 85])
print(s1.index)
print(s1.values)
=================================================================================
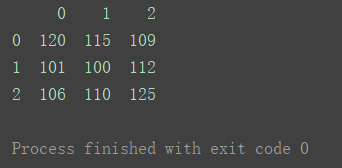
2.1.1不指定index和columns
当不指定index和columns时,默认为0, 1, 2。
import pandas as pd
data = [[120, 115, 109], [101, 100, 112], [106, 110, 125]]
df = pd.DataFrame(data=data)
print(df)
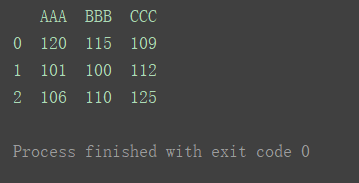
2.1.2指定index和columns
import pandas as pd
data = [[120, 115, 109], [101, 100, 112], [106, 110, 125]]
index = [0, 1, 2]
columns = [‘AAA’, ‘BBB’, ‘CCC’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
2.1.3使用字典创建DataFrame
键为列名,值为该列数据组成的列表。值也可以是单个元素,表示该列都取该值。
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106],
‘BBB’: [115, 100, 110],
‘CCC’: [109, 112, 125],
‘DDD’: ‘ABCDEFG’
}, index=[0, 1, 2])
print(df)
for col in df.columns:
series = df[col]
print(series)

2.3.1 loc标签索引
2.3.1.1获取单行数据
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 117, 114, 122],
‘BBB’: [115, 100, 110, 125, 123, 120],
‘CCC’: [109, 112, 125, 120, 116, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=======================")
print(df.loc[1])
df.loc[1]获取到标签索引为1的数据,在这里即第一行的。

2.3.1.2获取多行数据
print(df)
print("=======================")
print(df.loc[[1, 3]])

2.3.1.3切片连续多行数据
标签索引切片时左右边界的值都可以取。
print(df)
print("=======================")
print(df.loc[1:5])

2.3.2iloc位置索引
2.3.2.1获取某行数据
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 117, 114, 122],
‘BBB’: [115, 100, 110, 125, 123, 120],
‘CCC’: [109, 112, 125, 120, 116, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=======================")
print(df.iloc[1])
df.iloc[1]获取到第二行(下标为1)数据

2.3.2.2获取多行数据
print(df)
print("=======================")
print(df.iloc[[0, 2]])

2.3.2.3切片连续多行数据(左闭右开)
遵照左闭右开
print(df)
print("=======================")
print(df.iloc[1: 4])

某行(第二行)至最后一行
print(df)
print("=======================")
print(df.iloc[1:])

(或df.iloc[1::]写法也可)
2.3.3直接获取指定列数据
- 直接传入列名即可获取
2.3.3.1获取单列
获取单列有两种写法如下,结果有所不同
print(df)
print("=======================")
print(df[‘AAA’])
print(type(df[‘AAA’]))

print(df)
print("=======================")
print(df[[‘AAA’]])
print(type(df[[‘AAA’]]))

根据程序运行结果,df[‘AAA’]得到的是一个Series,而df[[‘AAA’]]得到的结果是一个DataFrame。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









