






maxwell配置
1 数据同步脚本
1.1 maxwell配置路径
/data/maxwell/maxwell_start_sh
1.2 配置参考
maxwell_rms_55.sh
| Bash |
新增配置修改参考如下:
--host: 域名
--user: mysql用户名
--password: mysql密码
--filter: 过滤条件,支持正则,但是实际使用建议先测试
exclude: *.* 先排除所有数据
include:rms.* 按库名筛选保留
exclude:rms./^_\S+_(gho|ghc)$/ 排除ddl语句
exclude:rms.*.customer_card=" " 按列值排除
--kafka_topic=maxwell_prd_rms: 发送kafka对应Topic
--kafka_topic=maxwell_prd_%{database} 这种是按照库名发送对应topic,不存在时自动创建
--http_port: http端口,需要和其他服务不冲突(包括其他maxwell服务)
--http_path_prefix: 对应maxwell用户
--client_id: maxwell监控用户,一个maxwell服务在mysql中的唯一编码
--replica_server_id: 也表示唯一编码,建议可以和端口号对应
--config:maxwell的配置文件路径
--kafka_partition_hash:指定哈希算法将消息分发不同的kafka分区,这里使用murmur3算法
--producer_partition_by:决定了如何将binlog分发到不同的kafka分区。这里我按主键值primary_key将binlog分发到不同的kafka分区。
producer_partition_by参数的可选值包括:database、table、primary_key、transaction_id、thread_id 和 column。这些值分别表示按照数据库名、表名、主键、事务ID、线程ID 和 指定列的值来分发 binlog 事件到 Kafka 分区。
启动前需确定mysql服务已开通maxwell库写权限(maxwell库如果已创建不需要建库权限,否则需要建库权限),非maxwell所有库读权限
然后直接启动对应Maxwell脚本即可
- 通过类似ps -ef |grep db_rms_artemis_maxwell_cdh语句,能查询到指定maxwell程序,且10s左右仍不挂
- 查看kafka偏移量,有变化
满足以上两点认为启动成功
如下,根据某个唯一属性查询指定maxwell服务,直接kill -9 即可
第一种类型:权限不足
解决方案:确定如上1.3权限是否给齐
第二种类型:挂掉太长时间后重启,binlog日志过期 (报错如下图)
解决方案:参考下图,访问mysql的maxwell库,查看positions表,查看对应client_id的binlog_file是否是当前存在的binlog文件(可通过show binary logs;查看当前存在biglog文件),如果不存在,改成存在的最早一个binlog,且binlog_position改为1,再次重启(会丢失未处理binlog日志对应的数据)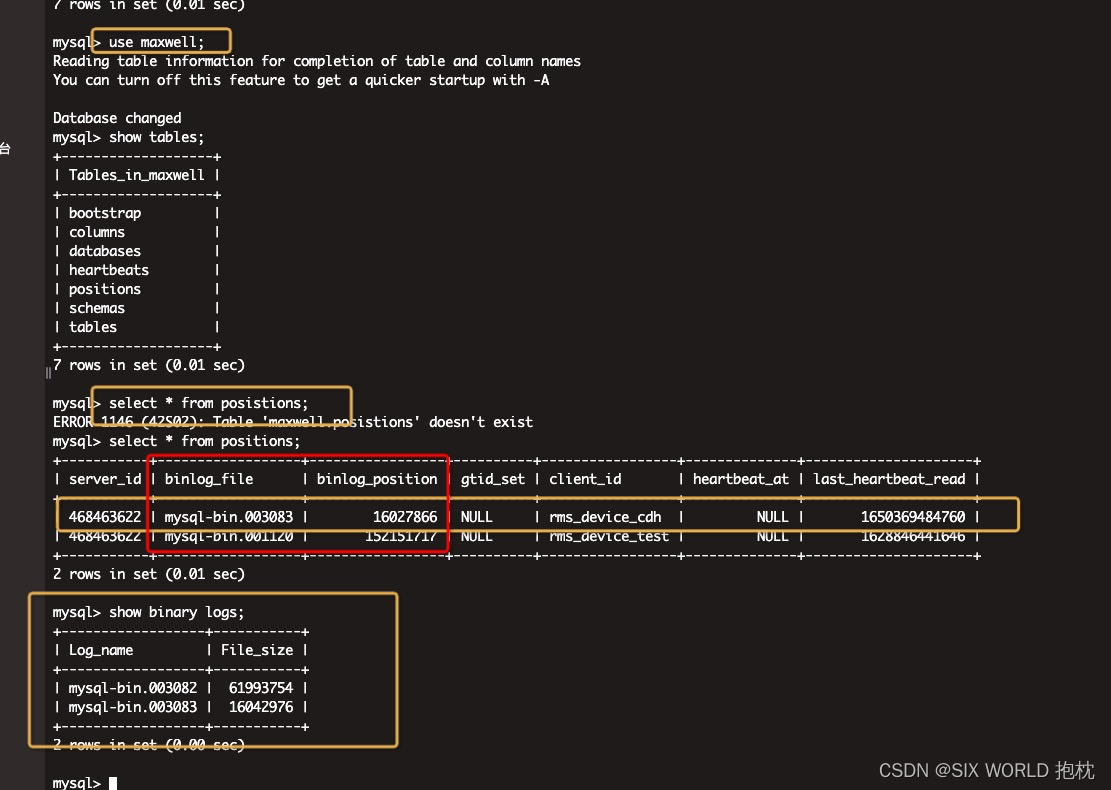
第三种类型:mysql新增库,但是没给maxwell用户权限,后又有其他操作,导致maxwell服务挂掉,且通过前两种方式都无法解决 【这部分先给权限再进行新增】
这种只能删除mysql的maxwell库,然后再启动maxwell服务(会在mysql中生成新的maxwell配置),暂无其他解决方案(重启后如果binlog日志文件没变动,不会丢失数据;如果binlog日志文件变动,会丢失未处理binlog日志部分数据)
2 数据预警脚本
该脚本用于maxwell因mysql服务异常挂掉后重启
脚本: /data/maxwell/monitor_maxwell/monitor.sh
#!/bin/bash
export JAVA_HOME=/usr/java/defaultdate=`date +%Y-%m-%d+%H:%M:%S`
dir=/data/maxwell/maxwell_log/isOnline.log# 保证arr1和arr2一一对应,arr1用来查询进程,arr2填好对应的maxwell脚本,当arr1对应的进程消失后,启动arr2对应的maxwell脚本
arr1=('db_hwyun_aibot_record_maxwell_cdh' 'db_hwyun_rms_engine_maxwell_cdh' )
arr2=('maxwell_hwyun_aibot_record_75.sh' 'maxwell_hwyun_rmsengine_62.sh' )length=${#arr1[@]}
echo "长度为:$length"
echo '-------------' >> ${dir}for ((i=0;i<${length};i++))
do
jobID=`ps -ef |grep ${arr1[$i]} | awk '{print $29}'` >> ${dir}
if [ ! $jobID ];then
echo ${date} >> ${dir}
echo "${jobID} ${arr2[$i]} is faild" >> ${dir}
`sh /data/maxwell/maxwell_start_sh/${arr2[$i]}` #重启脚本
sh /data/maxwell/alert_maxwell/run_maxwell_alert.sh ${arr1[$i]} ${jobID} ${date} #调用预警接口,这个是我们公司内部的,你们用自己公司的预警接口就行
echo "${jobID} faild 已重启 ${date}" >> ${dir}
else
echo "${jobID} is online ${date}" >> ${dir}
fi
done
exit;
3 maxwell binlog数据丢失处理
问题1(主因):丢失数据量超过5000条
21:54:11,036 ERROR MaxwellKafkaProducer - TimeoutException @ Position[BinlogPosition[mysql-bin.000113:476213575], lastHeartbeat=1649166824437] -- maxwell_prd_fms_new: fms:repay_plan_8:[(id,61749380)] 21:54:11,037 ERROR MaxwellKafkaProducer - Expiring 15 record(s) for maxwell_prd_fms_new-6: 30460 ms has passed since batch creation plus linger time
现况:目前kafka集群
producer.request.timeout.ms=30s,linger.ms=0,batch.size=16k。
分析:消息在producer发送端时,先保存在中间缓存中,组成批进行发送,如果超过默认限制时间(30s),还没发送出去就会报当前的异常,同时这批消息就会从消息队列中删除。
一个partition只会有队头的batch被发送,sender线程不会对发送中partition的其余batch检查过期,指向同一个broker的多个partition的batch能够合并成一个request发送。其中前两点是由Accumulator里的muted(进行中)变量来保证。只有muted的partition才不会对其余batch检查过期,在把batch组装成request即将发送时才会把partition添加进muted。如果是新的batch,因为网络抖动长时间(request.timeout.ms)不能组装成request,是会被sender线程检查过期并立即返回失败的callback。
Kafka producer源码解释:
public class TransactionManager {
// 存储着分区的下一个消息的序列号
private final Map<TopicPartition, Integer> nextSequence;
// 存储着正在发送的消息batch
private final Map<TopicPartition, PriorityQueue<ProducerBatch>> inflightBatchesBySequence;
synchronized void adjustSequencesDueToFailedBatch(ProducerBatch batch) {
if (!this.nextSequence.containsKey(batch.topicPartition))
return;
int currentSequence = sequenceNumber(batch.topicPartition);
currentSequence -= batch.recordCount;
if (currentSequence < 0)
throw new IllegalStateException("Sequence number for partition " + batch.topicPartition + " is going to become negative : " + currentSequence);
// 更新该分区的下个序列号,这样之后的消息就会从这个序列号开始,填补了这个序列号的缺失
setNextSequence(batch.topicPartition, currentSequence);
for (ProducerBatch inFlightBatch : inflightBatchesBySequence.get(batch.topicPartition)) {
if (inFlightBatch.baseSequence() < batch.baseSequence())
continue;
// 如果有在这条消息batch之后,发送的消息,需要更新它的序列号
// 序列号变为减去batch的消息数目
int newSequence = inFlightBatch.baseSequence() - batch.recordCount;
if (newSequence < 0)
throw new IllegalStateException("....");
// 更新新的序列号
inFlightBatch.resetProducerState(new ProducerIdAndEpoch(inFlightBatch.producerId(), inFlightBatch.producerEpoch()), newSequence, inFlightBatch.isTransactional());
}
}
}
原因:
-
kafka服务端压力过大导致处理请求慢;
-
客户端在短时间发送大量数据导致发送瓶颈(攒批,提升性能);
-
一些参数配置和应用本身数据流量模型不匹配;
-
broker机器故障;
结论:
-
同时设置
batch.size和linger.ms,就是哪个条件先满足就都会将消息发送出去。设置:linger.ms=50ms,batch.size=32k -
可以去kafka配置文件中修改,也可以去maxwell配置文件中修改(数据同步脚本中是--config对应的配置文件),这边修改的是maxwell配置文件。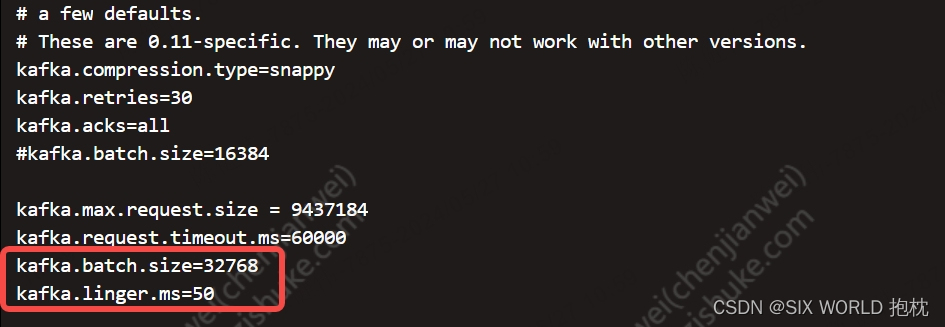















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









