







1、概述
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。MyBatis-Plus 提供了通用的mapper和service,可以在不编写任何SQL语句的情况下,快速的实现对单表的 CRUD、批量、逻辑删除、分页等操作。
我们的愿景是成为 MyBatis 最好的搭档,就像魂斗罗中的 1P、2P,基友搭配,效率翻倍。

特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作

支持数据库
- MySQL,Oracle,DB2,H2,HSQL,SQLite,PostgreSQL,SQLServer,Phoenix,Gauss ,ClickHouse,Sybase,OceanBase,Firebird,Cubrid,Goldilocks,csiidb
- 达梦数据库,虚谷数据库,人大金仓数据库,南大通用(华库)数据库,南大通用数据库,神通数据库,瀚高数据库
框架结构
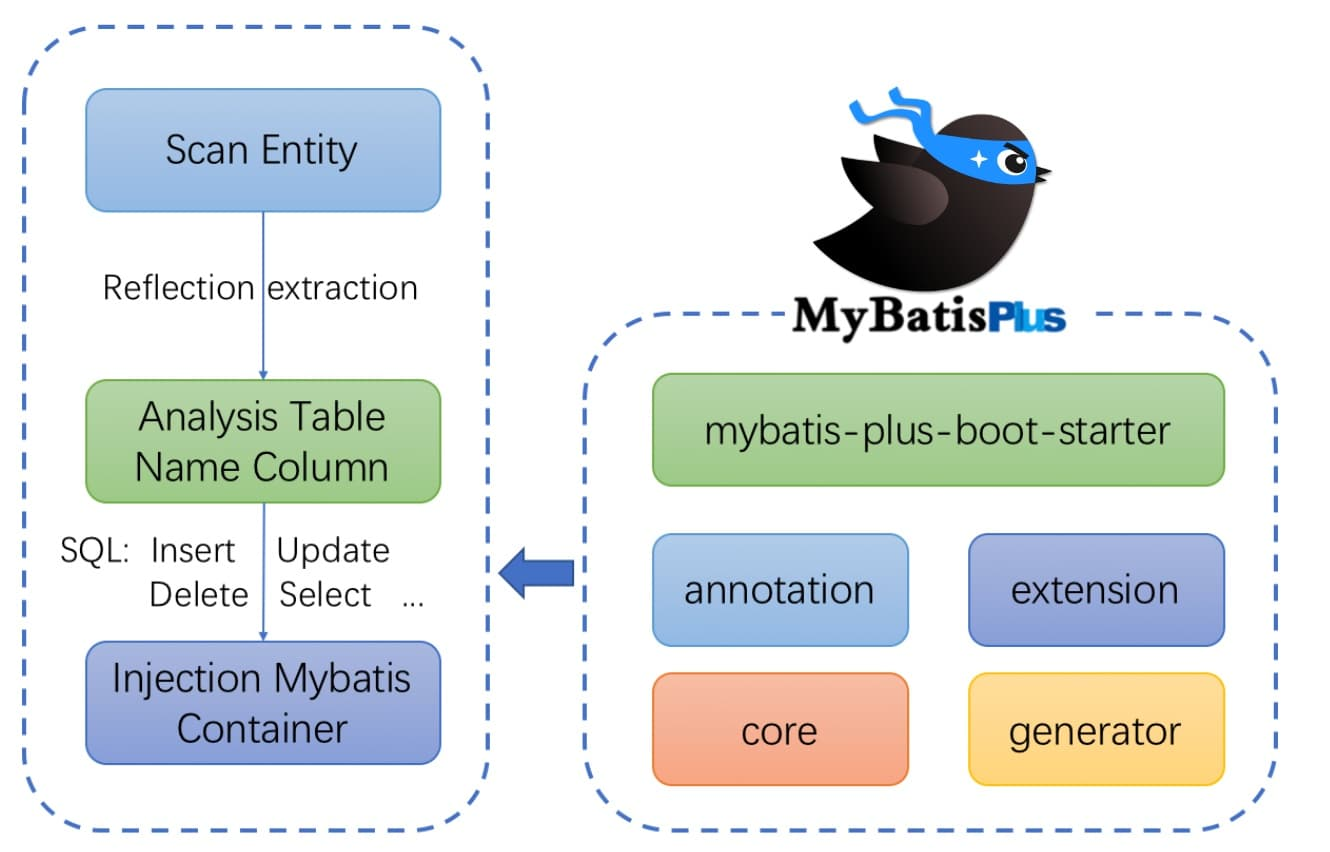
- 从扫描实体类开始,通过反射技术将实体类中的属性进行抽取,
- 抽取后分析当前表和实体类之间的关系,以及通过反射技术抽取出来的实体类中的属性与当前字段之间的关系,
- 根据当前调用的方法生成相应的 SQL 语句,将 SQL 语句注入到 mybatis 容器中,从而实现最终的功能。
官方文档
https://baomidou.com/pages/24112f/
2、MyBatis-Plus 初始化工程
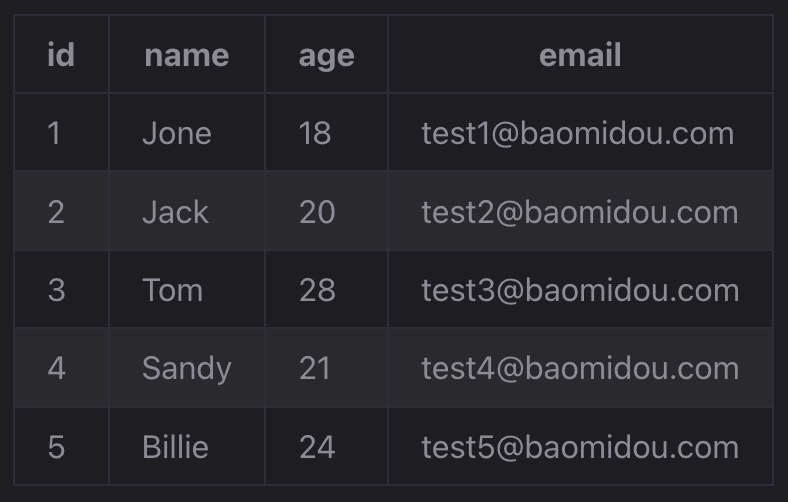
创建表及添加数据
CREATE DATABASE `mybatis_plus` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
use `mybatis_plus`;
CREATE TABLE `user` (
`id` bigint(20) NOT NULL COMMENT '主键ID',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, 'test1@baomidou.com'),
(2, 'Jack', 20, 'test2@baomidou.com'),
(3, 'Tom', 28, 'test3@baomidou.com'),
(4, 'Sandy', 21, 'test4@baomidou.com'),
(5, 'Billie', 24, 'test5@baomidou.com');
创建工程
添加相关依赖
<!-- mybatis-plus启动器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<!-- lombok用于简化实体类开发 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
安装 Lombok 插件
配置
application.yml文件
spring:
# 配置数据源信息
datasource:
# 配置数据源类型
type: com.zaxxer.hikari.HikariDataSource
# 配置连接数据库的各个信息
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis_plus?serverTimezone=GMT%2B8&characterEncoding=utf-8&useSSL=false
username: root
password: 283619
# 配置mybatis-plus的日志信息
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
注意:
- MySQL5.7版本的url:
jdbc:mysql://localhost:3306/mybatis_plus?characterEncoding=utf-8&useSSL=false - MySQL8.0版本的url:
jdbc:mysql://localhost:3306/mybatis_plus?serverTimezone=GMT%2B8&characterEncoding=utf-8&useSSL=false
在 Spring Boot 启动类中添加
@MapperScan注解,扫描Mapper文件夹
@SpringBootApplication
@MapperScan("cn.xx.mapper") // 扫描指定包下的mapper接口
public class MybatisplusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisplusApplication.class, args);
}
}
创建实体类
User.java
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
创建 Mapper 接口
public interface UserMapper extends BaseMapper<User> {
}
添加测试类,进行功能测试
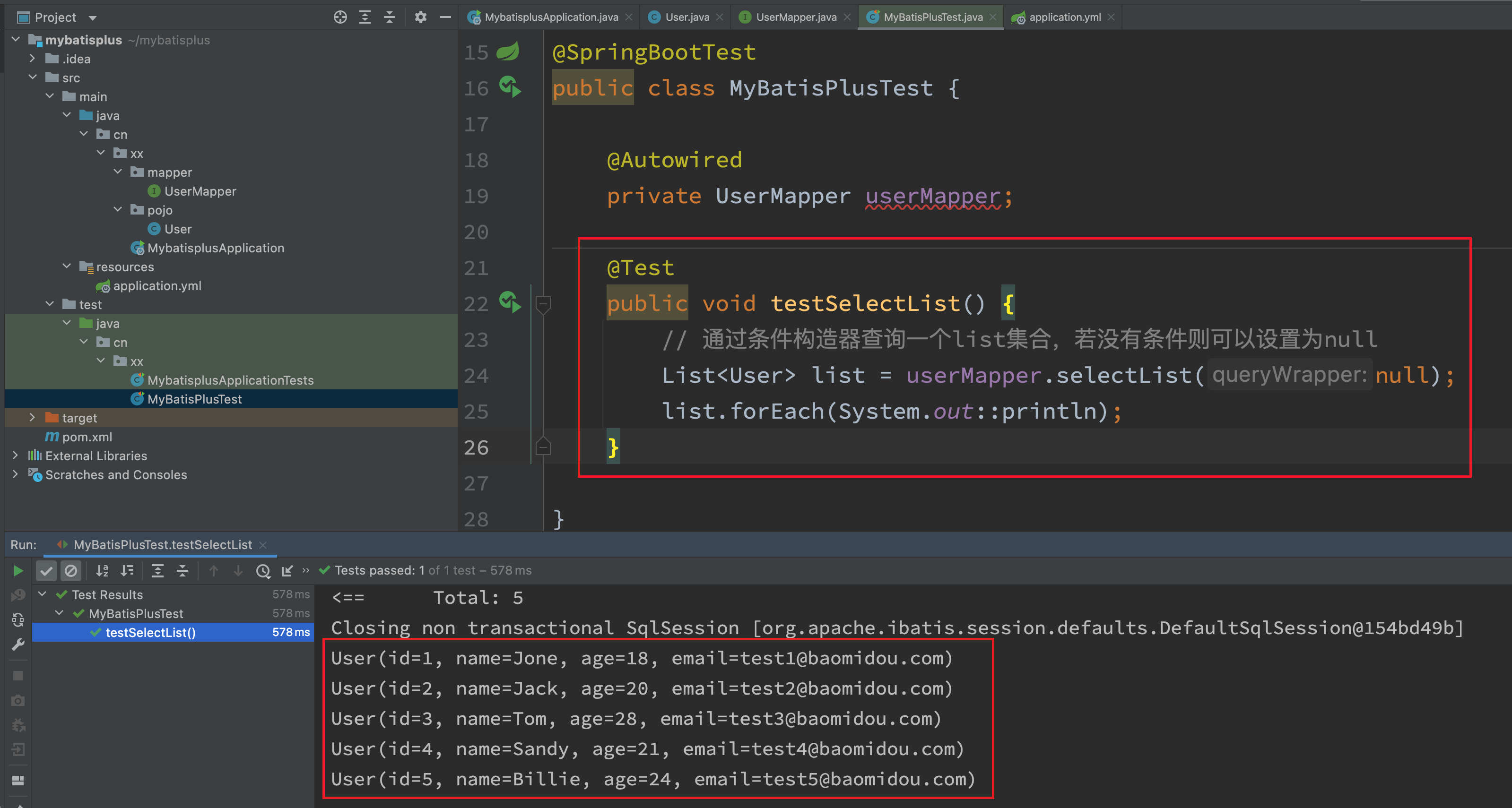
@SpringBootTest
public class MyBatisPlusTest {
@Autowired
private UserMapper userMapper;
@Test
public void testSelectList() {
// 通过条件构造器查询一个list集合,若没有条件则可以设置为null
List<User> list = userMapper.selectList(null);
list.forEach(System.out::println);
}
}
3、BaseMapper 中的 CRUD
BaseMapper 方法
- 通用 CRUD 封装 BaseMapper 接口,为
Mybatis-Plus启动时自动解析实体表关系映射转换为Mybatis内部对象注入容器 - 泛型
T为任意实体对象 - 参数
Serializable为任意类型主键,Mybatis-Plus不推荐使用复合主键,约定每一张表都有自己的唯一id主键 - 对象
Wrapper为条件构造器
MyBatis-Plus 中的基本 CRUD 在内置的 BaseMapper 中都已得到了实现,因此我们继承该接口以后就可以直接使用。
BaseMapper 中提供的 CRUD 方法:
- 增加:Insert
// 插入一条记录
int insert(T entity);
- 删除:Delete
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
- 修改:Update
// 根据 whereWrapper 条件,更新记录
int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);
// 根据 ID 修改
int updateById(@Param(Constants.ENTITY) T entity);
- 查询:Selete
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意:只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
插入
新增:int insert(T entity)
/**
* 实现新增用户信息:
* INSERT INTO user ( id, name, age, email ) VALUES ( ?, ?, ?, ? )
*/
@Test
public void testInsert() {
User user = new User();
user.setName("张三");
user.setAge(23);
user.setEmail("zhangsan@qq.com");
int result = userMapper.insert(user);
System.out.println("result = " + result);
// 获取自增的id
System.out.println("id = " + user.getId()); // id = 1581472109366976514
}
最终执行的结果,所获取的id为1581472109366976514,这是因为 MyBatis-Plus 在实现插入数据时,会默认基于雪花算法的策略生成id

删除
- 根据 ID 删除数据:int deleteById(Serializable id);
/**
* 通过id删除用户信息:
* DELETE FROM user WHERE id=?
*/
@Test
public void testDeleteById() {
// 注意该数值已经超过int的范围,需要在后面加上一个L表示long类型
int result = userMapper.deleteById(1581472109366976514L);
System.out.println("受影响的行数为:" + result);
}
- 根据 Map 条件删除数据:int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
/**
* 根据Map集合中所设置的条件进行删除用户信息:
* DELETE FROM user WHERE name = ? AND age = ?
*/
@Test
public void testDeleteByMap() {
Map<String, Object> map = new HashMap<>();
map.put("name", "张三");
map.put("age", 23);
int result = userMapper.deleteByMap(map);
System.out.println("受影响的行数为:" + result);
}
- 根据 ID 批量删除数据:int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
/**
* 通过多个id实现批量删除:
* DELETE FROM user WHERE id IN ( ? , ? , ? )
*/
@Test
public void testDeleteBatchIds() {
List<Long> list = Arrays.asList(1L, 2L, 3L);
int result = userMapper.deleteBatchIds(list);
System.out.println("受影响的行数为:" + result);
}
修改
int updateById(@Param(Constants.ENTITY) T entity);
/**
* 根据id修改用户信息:
* UPDATE user SET name=?, email=? WHERE id=?
*/
@Test
public void testUpdate() {
User user = new User();
user.setId(4L);
user.setName("李四");
user.setEmail("lisi@qq.com");
int result = userMapper.updateById(user);
System.out.println("受影响的行数为:" + result);
}
查询
- 根据 ID 查询用户信息:T selectById(Serializable id);
/**
* 根据id查询用户信息:
* SELECT id,name,age,email FROM user WHERE id=?
*/
@Test
public void testSelect() {
User user = userMapper.selectById(1L);
System.out.println("user = " + user);
}
- 根据多个 ID 查询多个用户信息:List selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
/**
* 根据多个id查询多个用户信息:
* SELECT id,name,age,email FROM user WHERE id IN ( ? , ? , ? )
*/
@Test
public void testSelectBatchIds() {
List<Long> ids = Arrays.asList(1L, 2L, 3L);
List<User> users = userMapper.selectBatchIds(ids);
users.forEach(System.out::println);
}
- 根据 Map 所设置的条件查询用户信息:List selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
/**
* 根据Map所设置的条件查询用户信息:
* SELECT id,name,age,email FROM user WHERE name = ? AND age = ?
*/
@Test
public void testSelectByMap() {
Map<String, Object> map = new HashMap<>();
map.put("name", "Jack");
map.put("age", 20);
List<User> users = userMapper.selectByMap(map);
users.forEach(System.out::println);
}
- 查询所有用户信息:List selectList(@Param(Constants.WRAPPER) Wrapper queryWrapper);
/**
* 查询所有用户数据:
* SELECT id,name,age,email FROM user
*/
@Test
public void testSelectList1() {
List<User> users = userMapper.selectList(null);
users.forEach(System.out::println);
}
4、通用 Service
- 通用 Service CRUD 封装
IService接口,进一步封装 CRUD 采用get 查询单行、remove 删除、list 查询集合、page 分页前缀命名方式区分Mapper层避免混淆, - 泛型
T为任意实体对象 - 建议如果存在自定义通用 Service 方法的可能,请创建自己的
IBaseService继承Mybatis-Plus提供的基类 - 对象
Wrapper为 条件构造器
MyBatis-Plus 中有一个接口 IService 和其实现类 ServiceImpl,封装了常见的业务层逻辑,详情查看源码 IService 和 ServiceImpl
因此我们在使用的时候仅需在自己定义的 Service 接口中继承 IService 接口,在自己的实现类中实现自己的 Service 并继承 ServiceImpl ****即可
IService 中的 CRUD 方法
- 增加:Save、SaveOrUpdate
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);
// TableId 注解存在更新记录,否插入一条记录
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
- 删除:Remove
// 根据 entity 条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
- 修改:Update
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);
- 查询:Get、List、Count
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
// 查询总记录数
int count();
// 根据 Wrapper 条件,查询总记录数
int count(Wrapper<T> queryWrapper);
- 分页:Page
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
调用 Service 层操作数据
我们在自己的 Service 接口中通过继承 MyBatis-Plus 提供的 IService 接口,不仅可以获得其提供的 CRUD 方法,而且还可以使用我们自定义的方法。
- 创建
UserService并继承IService
/**
* UserService继承IService模板提供的基础功能
*
* @author xiexu
* @create 2022-10-16 11:56
*/
public interface UserService extends IService<User> {
}
- 创建
UserService的实现类并继承ServiceImpl
/**
* ServiceImpl实现了IService,提供了IService中基础功能的实现
* 若ServiceImpl无法满足业务需求,则可以使用自定的UserService定义方法,并在实现类中实现
*
* @author xiexu
* @create 2022-10-16 11:56
*/
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
- 测试查询记录数:int count( );
/**
* 查询总记录数:
* SELECT COUNT( * ) FROM user
*/
@Test
public void testGetCount() {
long count = userService.count();
System.out.println("总记录数为:" + count);
}
- 测试批量插入数据:boolean saveBatch(Collection entityList);
/**
* 批量添加:
* INSERT INTO user ( id, name, age ) VALUES ( ?, ?, ? )
*/
@Test
public void testInsertMore() {
List<User> list = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
User user = new User();
user.setName("xx" + i);
user.setAge(20 + i);
list.add(user);
}
boolean b = userService.saveBatch(list);
System.out.println(b ? "添加成功!" : "添加失败!");
}
5、常用注解
@TableName
经过以上测试,在使用MyBatis-Plus实现基本的CRUD时,我们并没有指定要操作的表,只是在Mapper接口继承BaseMapper时,设置了泛型User,而操作的表为user表,由此得出结论,MyBatis-Plus在确定操作的表时,由BaseMapper的泛型决定,即实体类型决定,且默认操作的表名和实体类型的类名一致。
引出问题
若实体类类型的类名和要操作的表的表名不一致,会出现什么问题?
我们将表user更名为t_user,测试查询功能
程序抛出异常,Table ‘mybatis_plus.user’ doesn’t exist,因为现在的表名为t_user,而默认操作的表名和实体类型的类名一致,即 user 表

解决问题
- 使用注解
在实体类上添加
@TableName("t_user"),标识实体类对应的表名,即可成功执行 SQL 语句
@Data
@TableName("t_user") // 设置实体类所对应的表名
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
- 使用全局配置
在开发过程中,我们经常遇到以上问题,即实体类所对应的表都有固定的前缀,例如
t_或tbl_。此时,可以使用MyBatis-Plus提供的全局配置,为实体类所对应的表名设置默认的前缀,那么就不需要在每个实体类上通过@TableName标识实体类对应的表
# 配置mybatis-plus的日志信息
mybatis-plus:
# 设置mybatis-plus的全局配置
global-config:
db-config:
# 设置实体类所对应的表的统一前缀
table-prefix: t_
@TableId
经过以上测试,MyBatis-Plus在实现 CRUD 时,会默认将 id 作为主键列,并在插入数据时,默认基于雪花算法的策略生成id
引出问题
若实体类和表中表示主键的不是id,而是其他字段,例如
uid,MyBatis-Plus会自动识别uid为主键列吗?
我们将实体类中的属性id改为uid,将表中的字段id也改为uid,测试添加功能
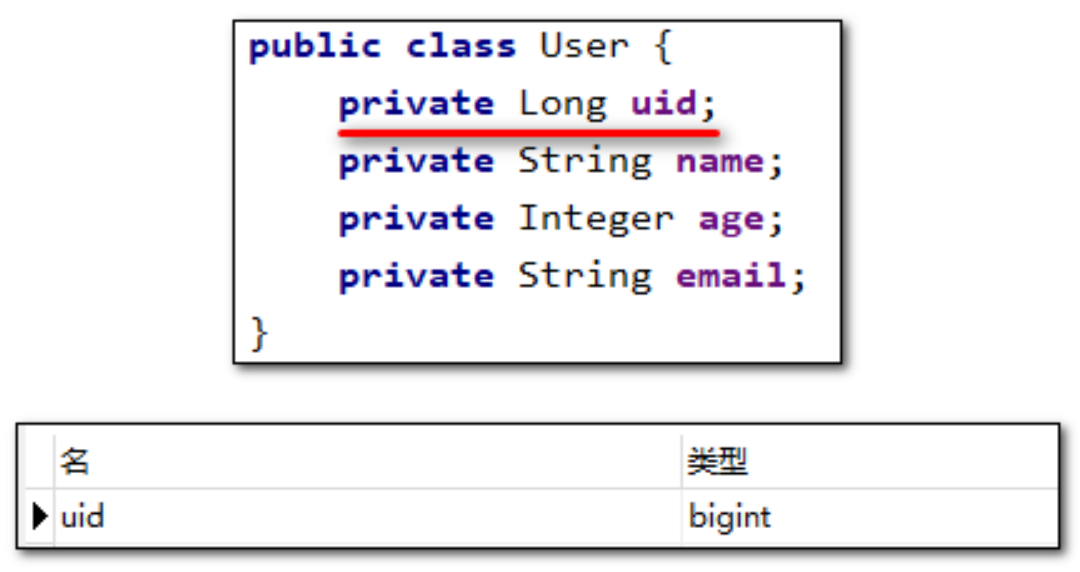
程序抛出异常,Field ‘uid’ doesn’t have a default value,说明MyBatis-Plus没有将uid作为主键赋值

解决问题
在实体类中uid属性上通过
@TableId将其标识为主键,即可成功执行SQL语句
@Data
public class User {
@TableId // 将属性所对应的字段指定为主键
private Long uid;
private String name;
private Integer age;
private String email;
}
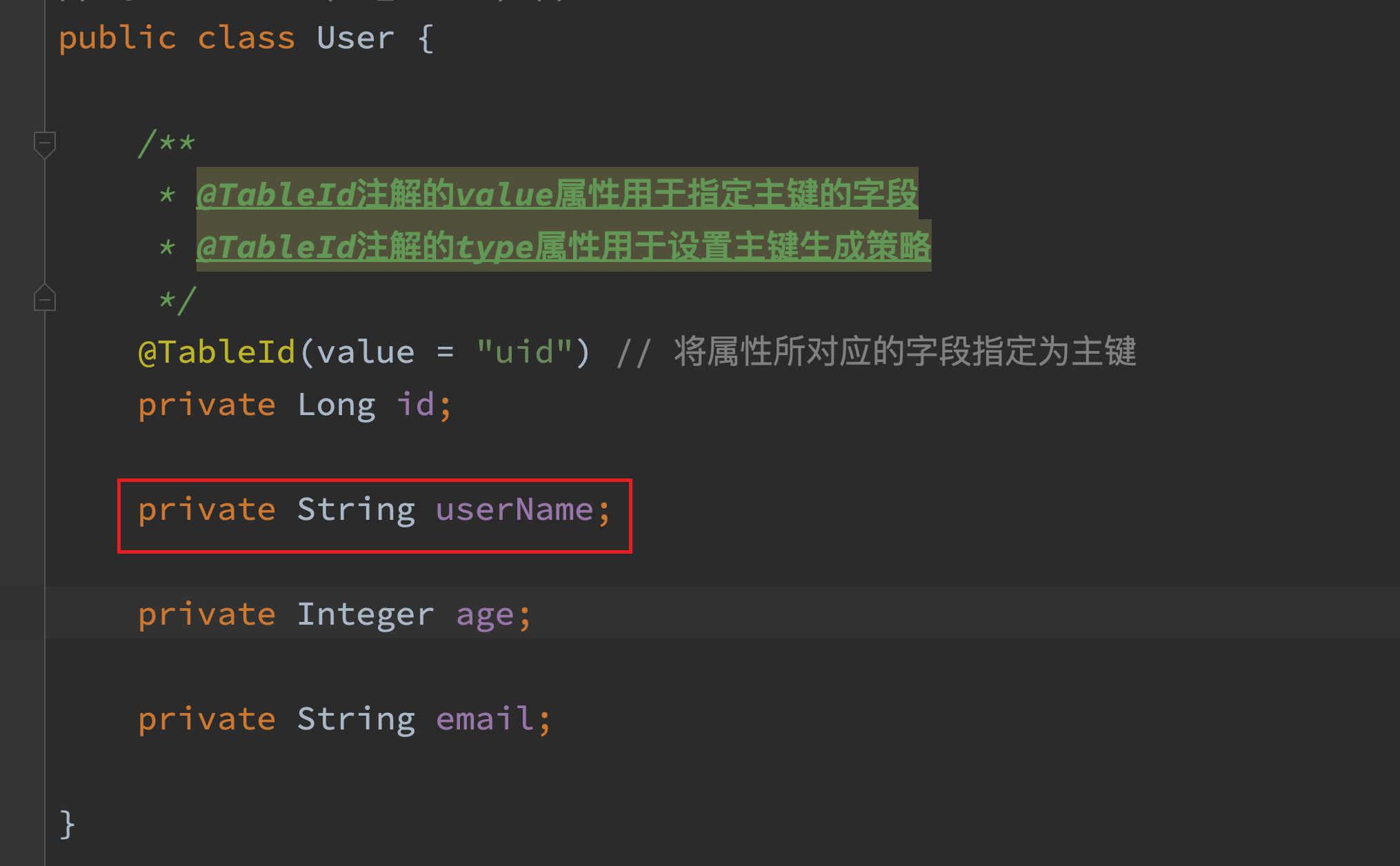
@TableId的value属性
若实体类中主键对应的属性为id,而数据库表中表示主键的字段为uid,此时若只在属性id上添加注解@TableId,则抛出异常 Unknown column ‘id’ in ‘field list’,即 MyBatis-Plus 仍然会将id作为表的主键进行操作,而表中表示主键的是字段uid,此时需要通过@TableId注解的value属性,指定表中的主键字段,@TableId("uid")或@TableId(value="uid")

解决问题:
@Data
public class User {
// @TableId注解的value属性用于指定主键的字段
@TableId(value = "uid") // 将属性所对应的字段指定为主键
private Long id;
private String name;
private Integer age;
private String email;
}

@TableId的type属性
type属性用来定义主键策略:默认雪花算法
常用的主键策略:
| 值 | 描述 |
|---|---|
| IdType.ASSIGN_ID(默认) | 基于雪花算法的策略生成数据id,与数据库id是否设置自增无关 |
| IdType.AUTO | 使用数据库的自增策略,注意:该类型请确保数据库设置了id自增 |
@Data
public class User {
/**
* @TableId注解的value属性用于指定主键的字段
* @TableId注解的type属性用于设置主键生成策略
*/
@TableId(value = "uid", type = IdType.AUTO) // 将属性所对应的字段指定为主键
private Long id;
private String name;
private Integer age;
private String email;
}
配置全局主键策略:
# 配置mybatis-plus的日志信息
mybatis-plus:
# 设置mybatis-plus的全局配置
global-config:
db-config:
# 设置实体类所对应的表的统一前缀
table-prefix: t_
# 设置统一的主键生成策略
id-type: auto
雪花算法
需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
数据库分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进
行拆分。
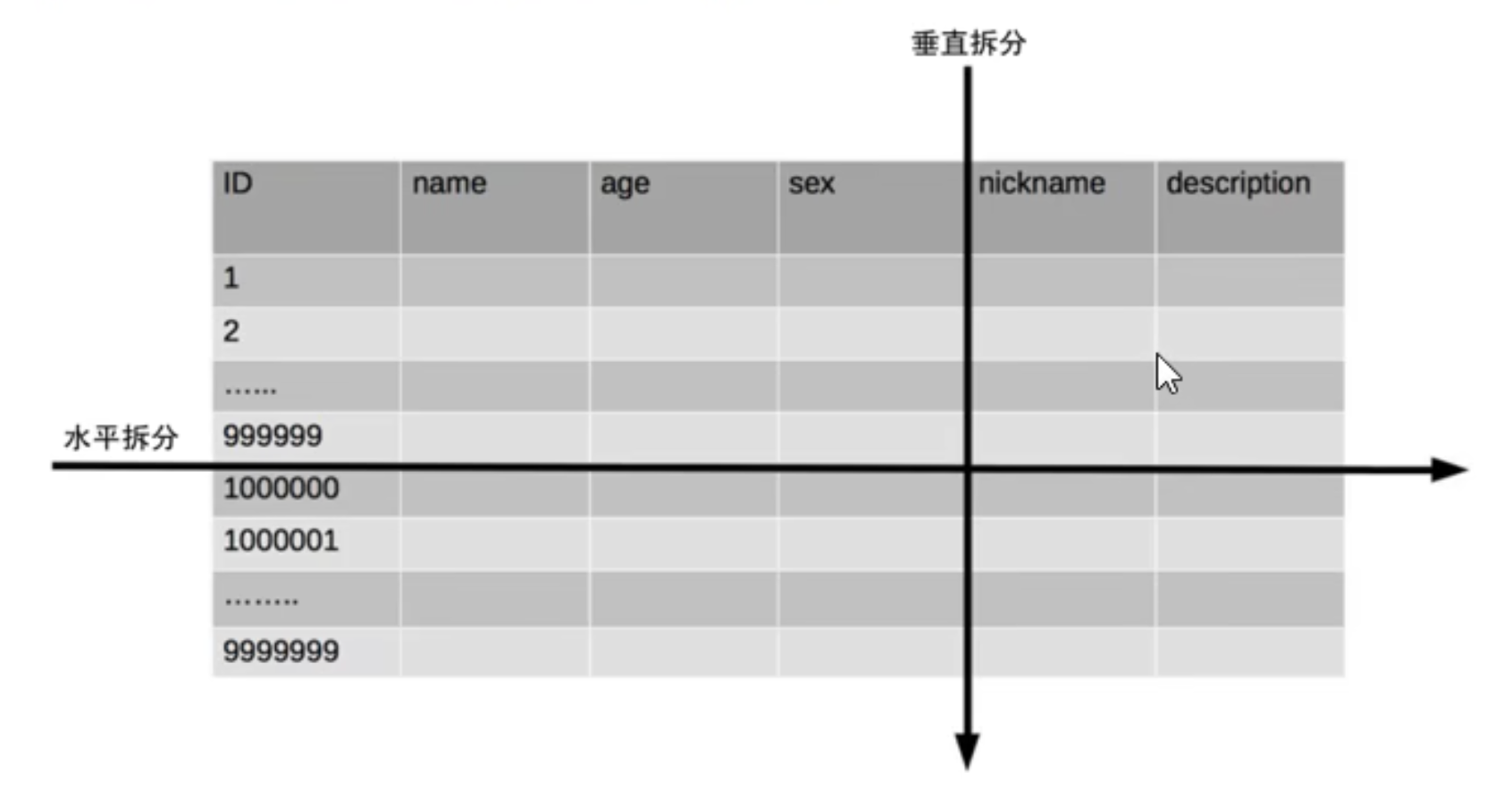
垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
例如,上面示意图中的 nickname 和 description 字段,假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询的,而 nickname 和 description 两个字段主要是用于展示,一般不会在业务查询中用到。description 字段本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
水平分表
水平分表适合表的行数特别大的表,有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过 1000万就要进行分表了;而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。
但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患。
水平分表相比垂直分表,会引入更多的复杂性,例如要求全局唯一的数据id该如何处理。
主键自增
- 以最常见的用户 ID 为例,可以按照 1000000 的范围大小进行分段,1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此类推。
- 复杂点:分段大小的选取。分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
- 优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
- 缺点:分布不均匀。假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1 条,而另外一个分段实际存储的数据量有 1000 万条。
取模
- 同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的子表中。
- 复杂点:初始表数量的确定。表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
- 优点:表分布比较均匀。
- 缺点:扩充新的表很麻烦,所有数据都要重分布。
雪花算法
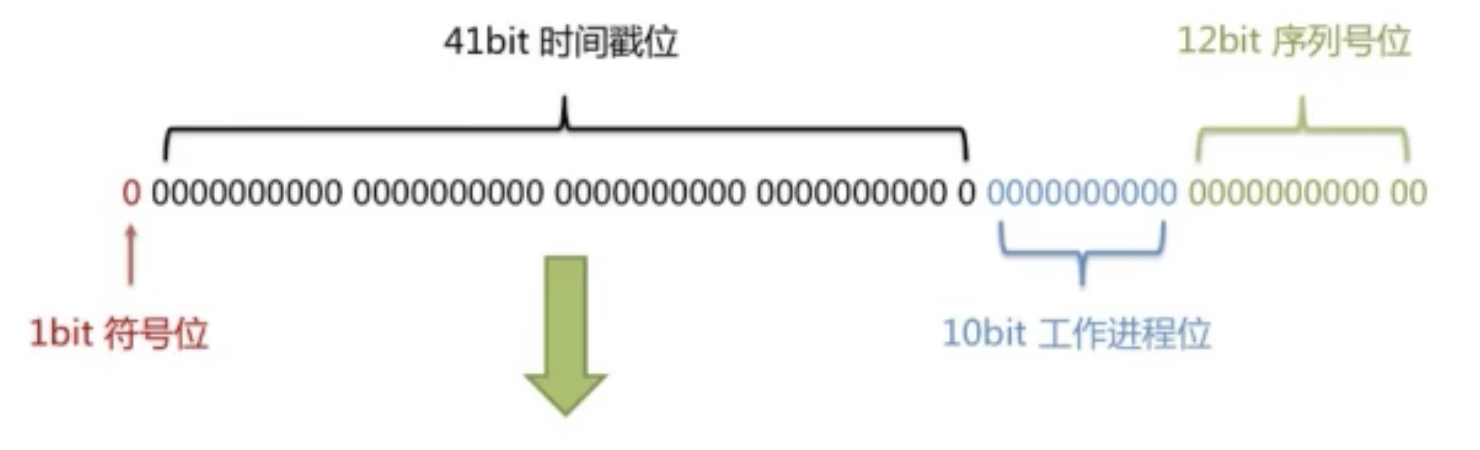
雪花算法是由 Twitter 公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
- 核心思想:
长度共64bit(一个long型)。
首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年。
10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以部署在1024个节点)。
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
- 优点:
整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
@TbaleField
经过以上测试,我们可以发现,MyBatis-Plus在执行SQL语句时,要保证实体类中的属性名和表中的字段名一致
如果实体类中的属性名和字段名不一致的情况,会出现什么问题呢?
情况一
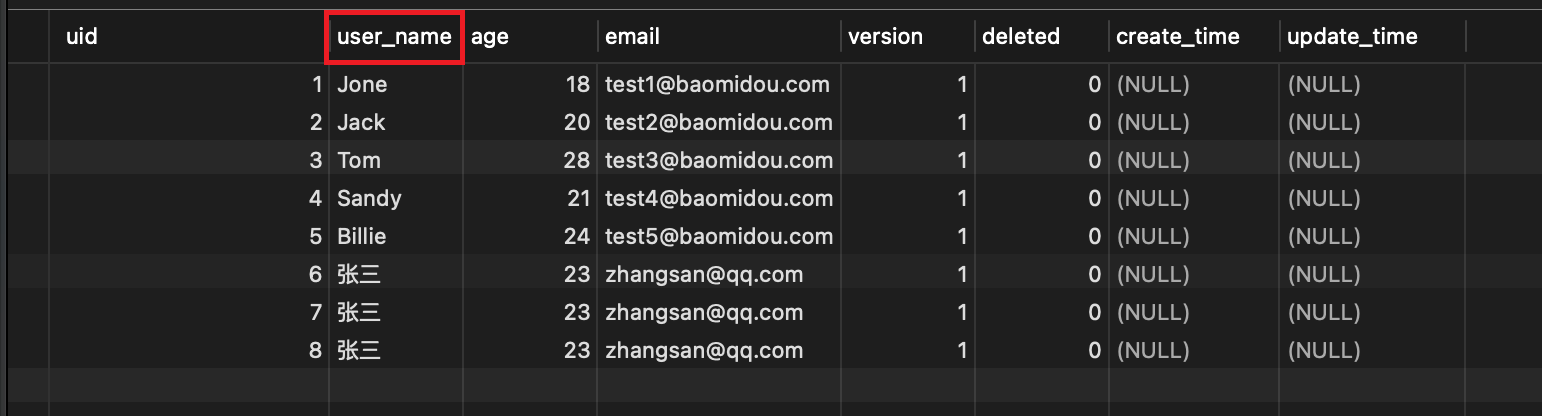
若实体类中的属性使用的是驼峰命名风格,而表中的字段使用的是下划线命名风格
例如实体类属性userName,表中字段user_name
此时MyBatis-Plus会自动将下划线命名风格转化为驼峰命名风格
相当于在MyBatis中配置
情况二
若实体类中的属性和表中的字段不满足情况1
例如实体类属性name,表中字段user_name
此时需要在实体类属性上使用@TableField("user_name")设置属性所对应的字段名
@Data
public class User {
/**
* @TableId注解的value属性用于指定主键的字段
* @TableId注解的type属性用于设置主键生成策略
*/
@TableId(value = "uid") // 将属性所对应的字段指定为主键
private Long id;
// 指定属性所对应的字段名
@TableField("user_name")
private String name;
private Integer age;
private String email;
}
@TableLogic
逻辑删除
- 物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除的数据
- 逻辑删除:假删除,将对应数据中代表是否被删除字段的状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录
- 使用场景:可以进行数据恢复
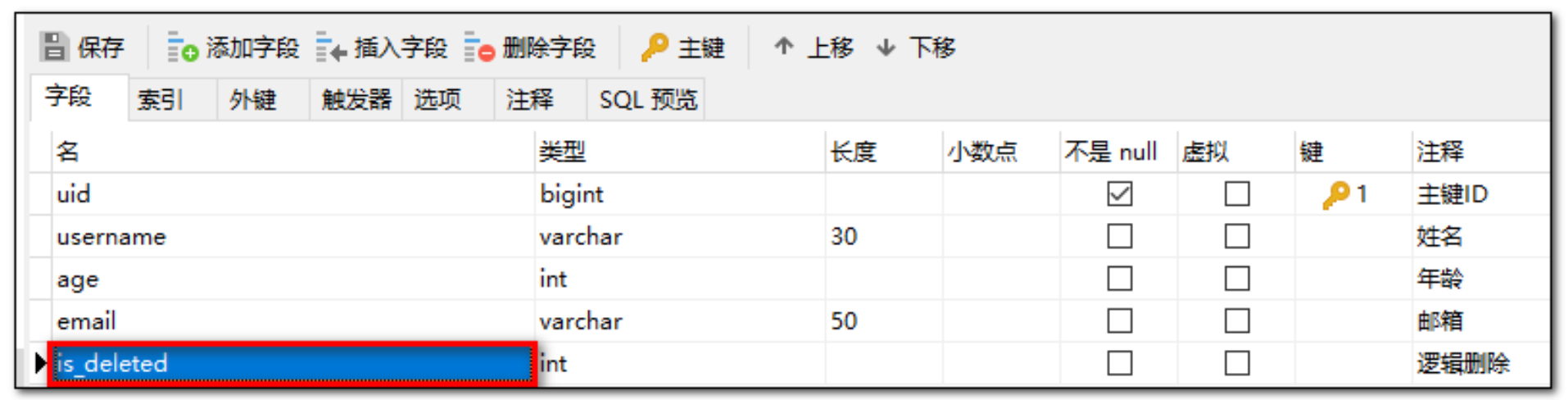
实现逻辑删除
- 数据库中创建逻辑删除状态列,设置默认值为0
- 实体类中添加逻辑删除属性
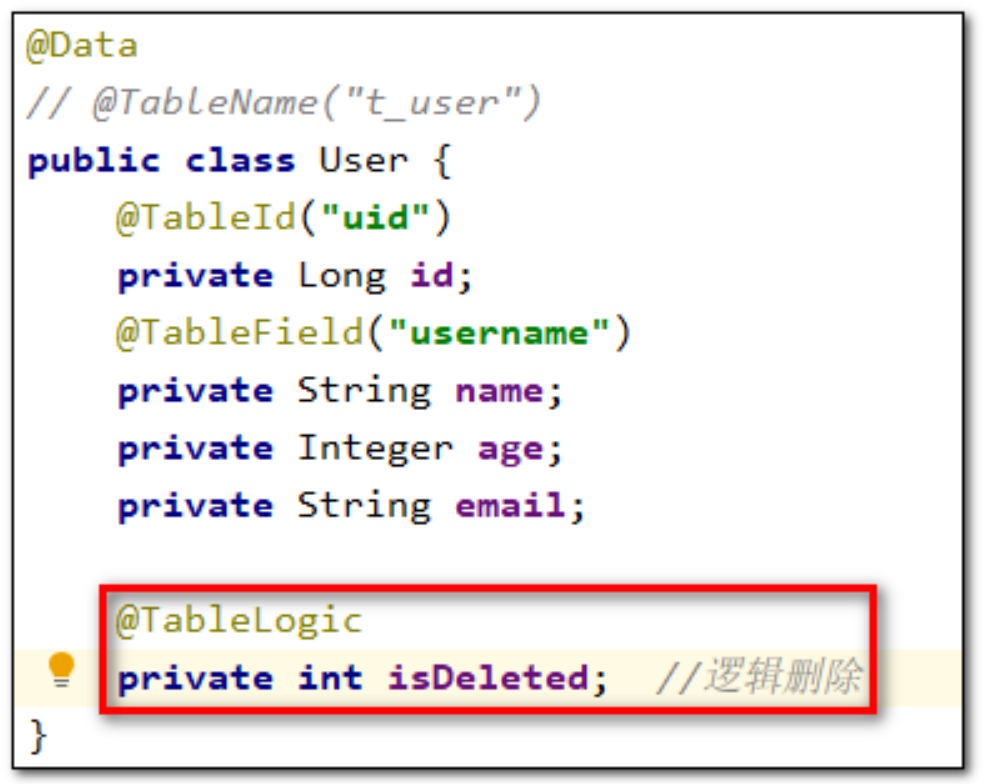
- 测试删除功能,真正执行的是修改

- 此时执行查询方法,查询的结果自动添加条件
is_deleted=0
















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











