







1、寻找文章对应链接
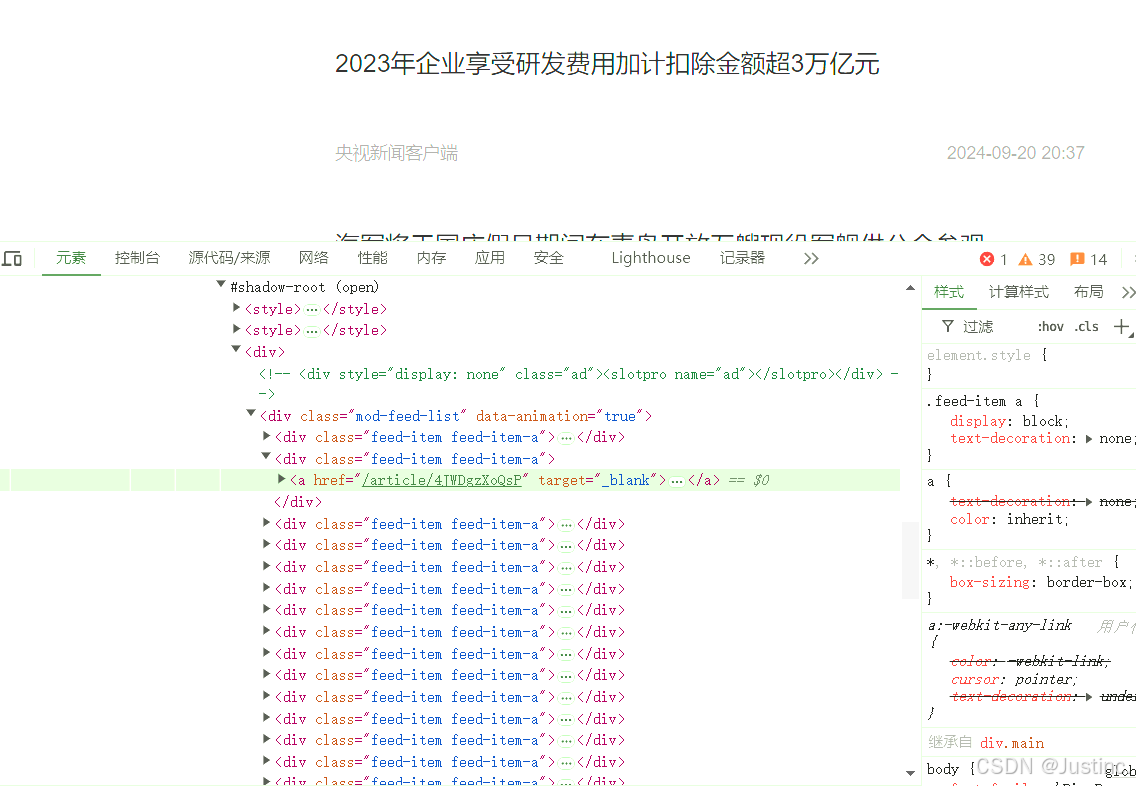
-
我们发现并不是一段完整的url,抓包进行分析
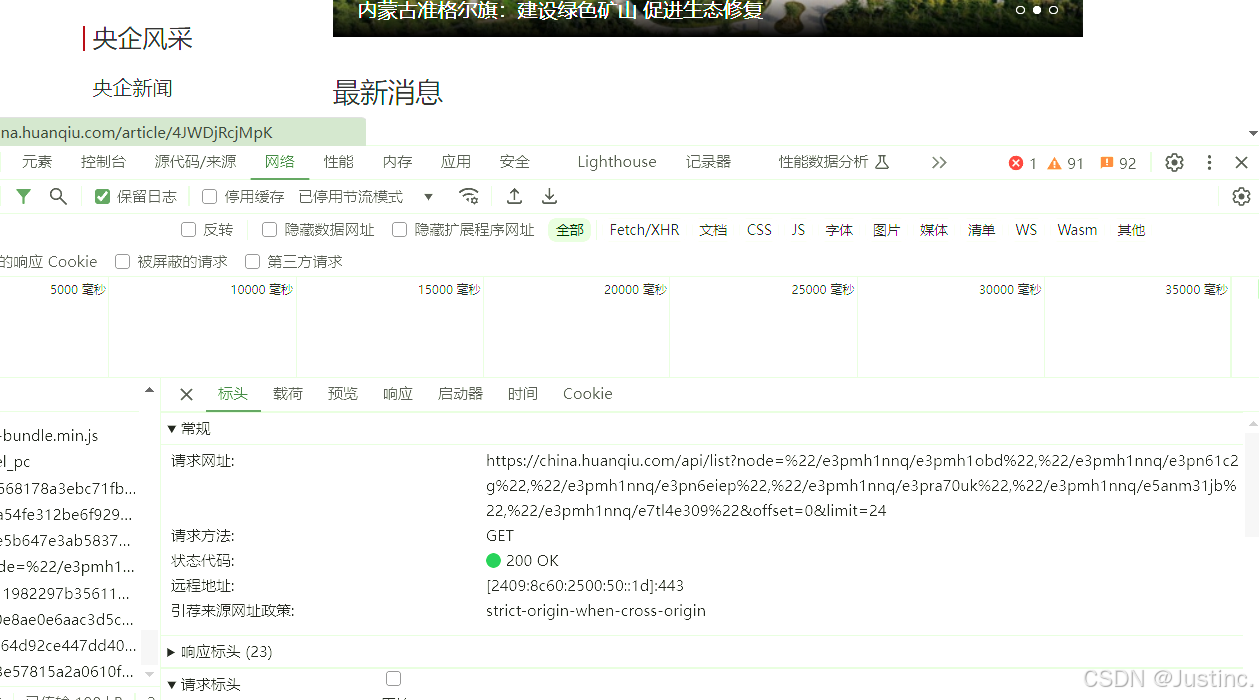
-
发现一段带有参数的请求,而且网页并没有翻页操作按键,所以我们推测是懒加载,向下滑动网页分析链接。
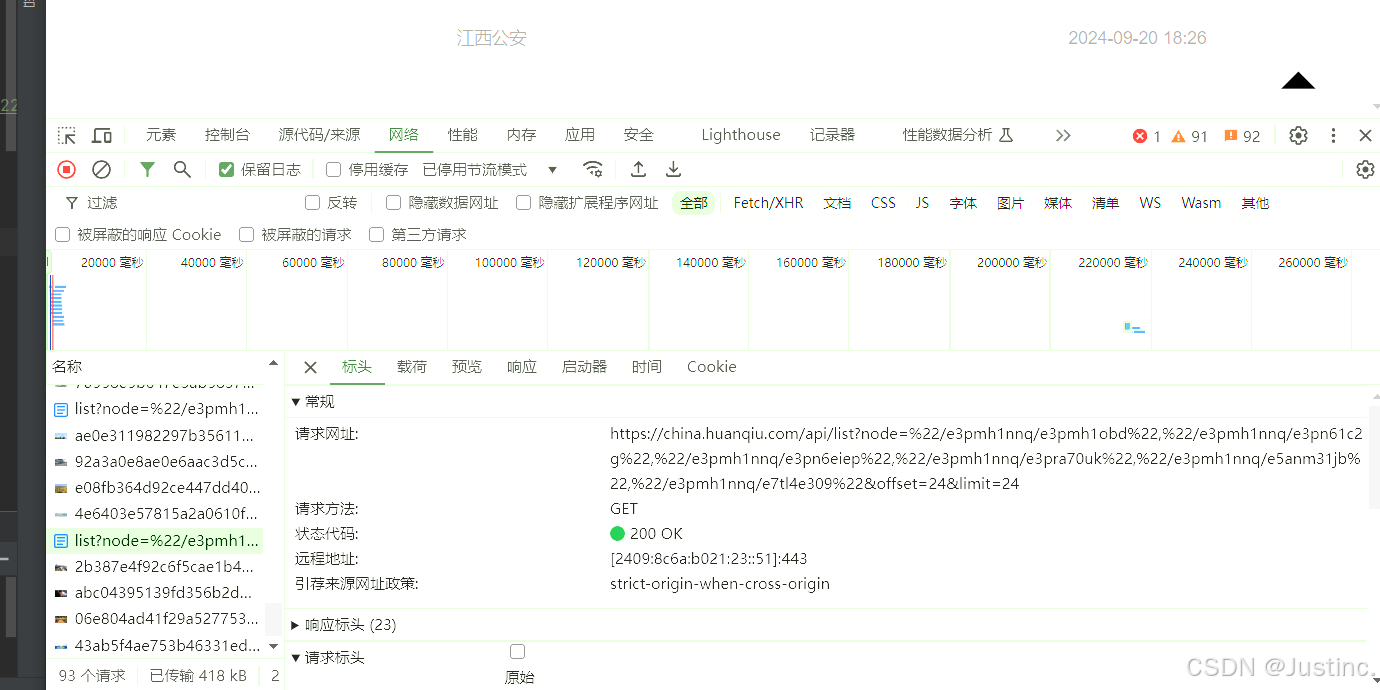
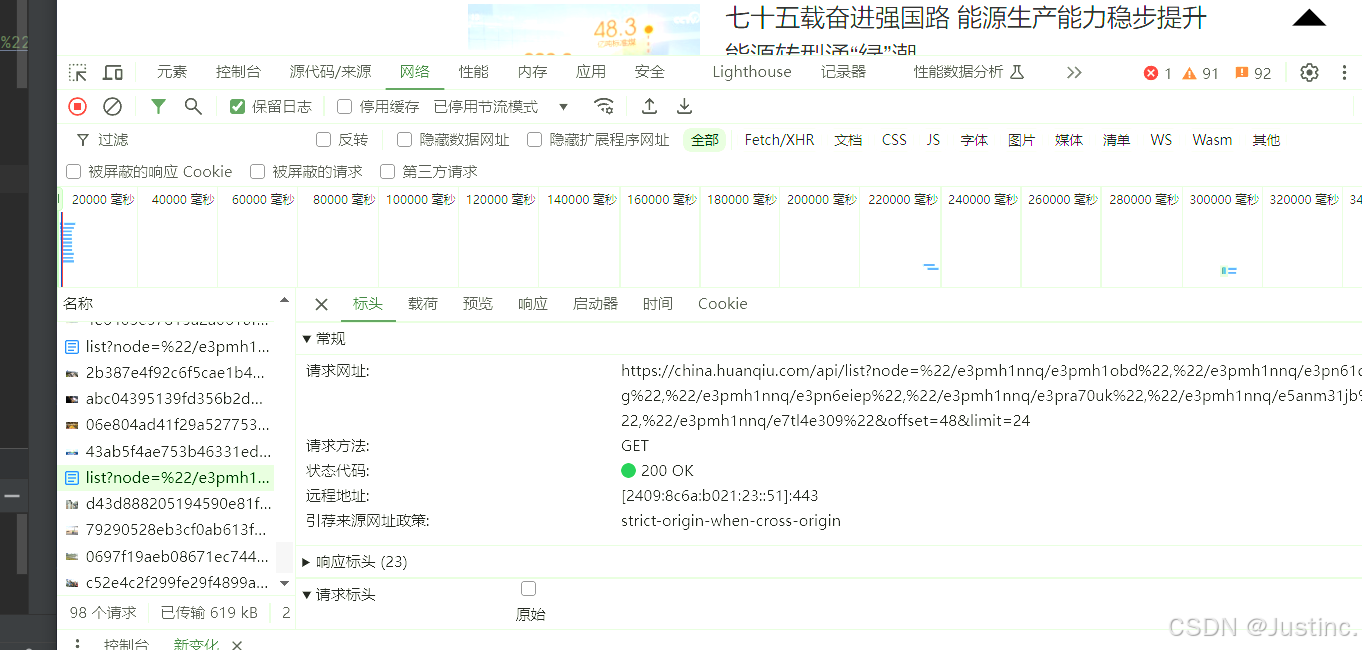
- 发现offset参数发生改变,由后面参数推测每次最多加载24个
# url链接
url = f"https://china.huanqiu.com/api/list?node=%22/e3pmh1nnq/e3pmh1obd%22,%22/e3pmh1nnq/e3pn61c2g%22,%22/e3pmh1nnq/e3pn6eiep%22,%22/e3pmh1nnq/e3pra70uk%22,%22/e3pmh1nnq/e5anm31jb%22,%22/e3pmh1nnq/e7tl4e309%22&offset={i}&limit=24"
2、解析内容
- 获取示例文本
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
url = f"https://china.huanqiu.com/api/list?node=%22/e3pmh1nnq/e3pmh1obd%22,%22/e3pmh1nnq/e3pn61c2g%22,%22/e3pmh1nnq/e3pn6eiep%22,%22/e3pmh1nnq/e3pra70uk%22,%22/e3pmh1nnq/e5anm31jb%22,%22/e3pmh1nnq/e7tl4e309%22&offset=0&limit=24"
response = requests.get(url=url, headers=headers)
response_text = response.content.decode("utf8")
text = response_text
- 获取文章链接
urls = []
url_ = re.findall('"aid": ".*?",', response_text)
for u in url_:
url = "https://china.huanqiu.com/article/" + re.findall("4\\w*", u)[0]
urls.append(url)
- 获取文章标题
titles = []
title_ = re.findall('"title": ".*?",', response_text)
for t in title_:
title = re.search('("title"): "(.*?)"', t).group(2)
titles.append(title)
- 获取文章作者
authors = []
author_ = re.findall('"name":".*?"', response_text)
for a in author_:
author = re.search('("name"):"(.*?)"', a).group(2)
authors.append(author)
- 获取文章内容
articles = []
for article_url in urls:
text_ = []
article = requests.get(url=article_url, headers=headers)
article_response = article.content.decode("utf8")
article_text1 = re.findall('<section data-type="rtext"><p>.*</p>', article_response) # 匹配文章内容
article_text2 = [re.sub(r'<[^>]+>', '', content) for content in article_text1] # 去除文章的html标签
# 打印提取的文本内容
for text in article_text2:
text_.append(text)
article_ = text_[0]
articles.append(article_)
3、保存获取内容
with open("前24条新闻数据.txt", "w", encoding="utf-8") as f:
# for i in range(0, len(info_str), 80): # 每隔80个字进行分行
# f.write(info_str[i: i + 40] + "\n")
for i in info_list: # 按照内容分行
f.write(str(i)+"\n")



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









