







准备
概念明晰
- mmap:为什么会有mmap?我们知道,当我们在进程中申请内存写内存的时候,实际上是直接写在了这个(虚拟)内存对应的物理内存上。而我们读写文件时,却要在内核经过一次拷贝,那么有没有办法像读写内存那样读写文件,从而省去这次拷贝呢?mmap是linux提供的一个解决方案,用户可以把文件映射进内核,内核返回一个地址,用户对这个地址进行操作,就等于直接对文件进行读写,优点是省去了常规读写文件的把用户态数据拷贝进内核的开销,并且多个进程可以映射同一个文件,也是一种多进程通信的方案。关于共享内存,可以参阅宋宝华:世上最好的共享内存(Linux共享内存最透彻的一篇)
- vma:全称virtual_memory_area,直译过来就是虚拟内存区域。我们知道,linux是用虚拟内存管理进程的,进程申请内存时内核并不会直接分配物理内存给我们(万一用户分配了内存却不用不就很亏),而是在内核留下一条记录,等到真正要读写这段内存的时候才会给我们分配物理内存。虚拟内存有几个好处,1.隔离进程环境,是多进程运行的基础。2. 给每个进程提供更大的逻辑内存。mmap当然也使用到了虚拟内存,调用mmap的时候会返回一个内存地址,这个地址也是虚拟内存的地址,此时并没有分配物理内存,等到实际读写时才分配物理内存。
进程地址空间的布局
进程地址空间的布局有两种结构,一种是经典结构,另一种是改良后的布局结构。
经典布局
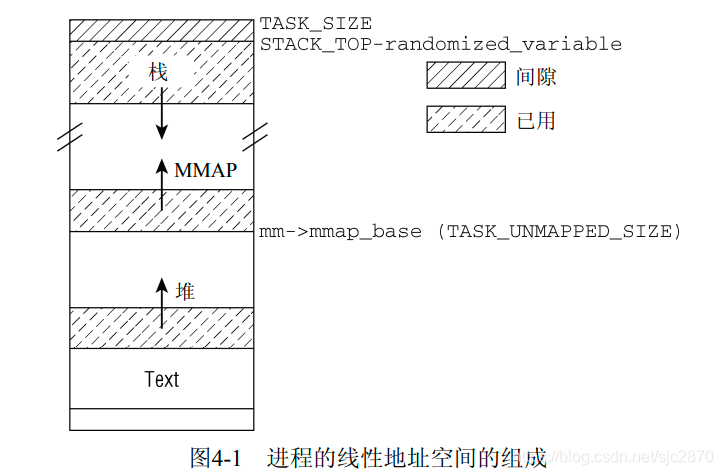
图示来自《深入Linux内核架构》
改良布局
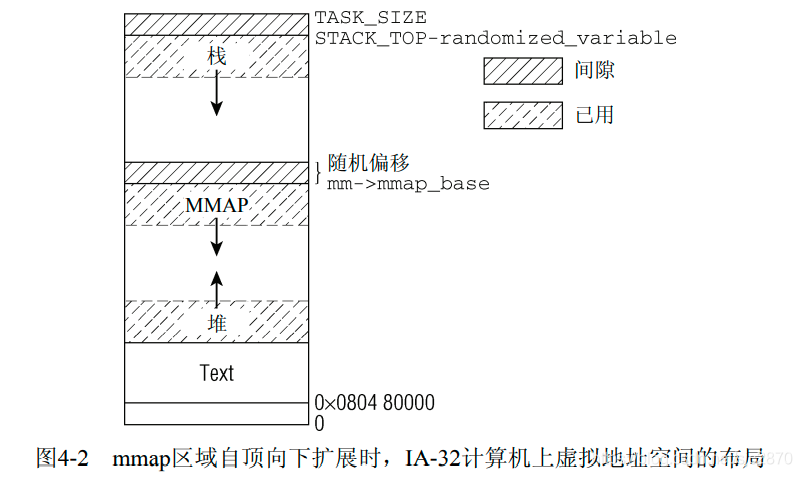
图示来自《深入Linux内核架构》
可以看到,mmap区域都是从mm->mmap_base开始,在经典布局下为TASK_UNMAPPED_BASE。mm也就是memory_manage,结构类型为mm_struct,是用于进程管理内存的数据结构,我们这里用到的不多。我们这里只讨论经典布局,也就是MMAP区域由低地址向高地址增长。
进程地址空间全景
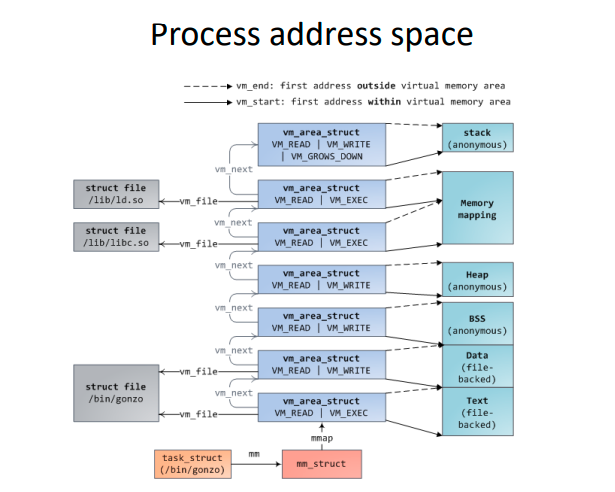
可以看到,整个进程的地址空间都是由vm_area_struct构成的,堆栈的背后都是一个个匿名页(page),而堆栈的权限又不相同。data segment, text segment 和mmap segment的背后都是一个个的文件页(page),它们的执行权限又不相同。这些匿名页和文件页共同组成了进程的整个地址空间。
图示来自
Process address space
数据结构
虚拟内存结构:
内核使用struct vm_area_struct结构来表示一段虚拟内存
结构如下:
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} linear;
struct list_head nonlinear;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
- vm_start和vm_end:虚拟内存的开始和结束地址
- vm_next, vm_prev:该任务(进程/线程)所有的vma结构会组成一个有序链表,按地址从低到高排序。vm_next和vm_prev就是链表的前一个和后一个元素。
- vm_rb:该任务(进程/线程)的所有vma结构会组成一颗红黑树,按地址从低到高排序。vm_rb就是它所在的节点。
- rb_subtree_gap:mmap使用augmented_tree和rb_subtree_gap来提升查找地址的性能。翻看linux源码可知,3.8之前查找地址的过程为线性的,时间复杂度为O(n),对应的函数是arch_get_unmapped_area。在3.8使用augmented_tree和rb_subtree_gap优化了该过程,查找地址的时间复杂度为O(logn),对应的函数是unmapped_area。可以说是一个巨大的性能提升了,我们下面会详述这个变量的使用。
- vm_mm:此虚拟内存区域所在的内存管理实例。每个vma会通过这个指针反向指向对应mm(memory_manage)实例。
- vm_page_prot:_PAGE_READ、_PAGE_WRITE和_PAGE_EXECUTE等,表示此区域的访问权限
- vm_flags:VM_READ、VM_WRITE、VM_EXEC、VM_SHARED分别指定了页的内容是否可以读、写、执行,或者由几个进程共享。 VM_MAYREAD、VM_MAYWRITE、VM_MAYEXEC、VM_MAYSHARE用于确定是否可以设置对应的VM_* 标志。这是mprotect系统调用所需要的。VM_GROWSDOWN和VM_GROWSUP表示一个区域是否可以向下或向上扩展(到更低或更高的虚拟地址)。由于堆自下而上增长,其区域需要设置VM_GROWSUP。VM_GROWSDOWN对栈设置,该区域自顶向下增长。
- shared:下面这个让人望而生畏的union结构,是为了实现文件页的反向映射。
- anon_vma_chain和anon_vma:为了实现匿名页的反向映射。反向映射这里涉及内容很多,会单独写一篇文章介绍,这里暂时跳过。
- vm_ops:是一个指向许多方法集合的指针。用于在虚拟内存区域上执行一些操作。
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
struct page * (*nopage)(struct vm_area_struct * area, unsigned long
address, int *type);
};
- 在创建和删除区域时,分别调用open和close。这两个接口通常不使用,设置为NULL指针。
- 但fault是非常重要的。如果地址空间中的某个虚拟内存页不在物理内存中,自动触发的缺页异常处理程序会调用该函数,将对应的数据读取到一个映射在用户地址空间的物理内存页中。
- nopage是内核原来用于响应缺页异常的方法,不如fault那么灵活。出于兼容性的考虑,该成员仍然保留,但不应该用于新的代码。
- vm_pgoffset指定了文件映射的偏移量,该值用于只映射了文件部分内容时(如果映射了整个文件,则偏移量为0)。映射的单位是页,而不是字节,也就是如果该值为1,对应的字节偏移量为4096.
- vm_file:
struct file结构代表了进程打开的一个文件实例。此成员代表了被映射的文件。 - vm_private_data:一般为NULL。
- vm_region:在没有设置mmu(Memory Management Unit)的场景下使用,一般机器都有mmu,这里我们不做讨论。
- vm_policy:内存策略。如果设置了NUMA(non-uniform memory access)–非一致性内存访问,就会启用内存策略机制。在多核cpu结构的系统中,某个cpu访问其本地的物理内存是最快的,而穿过总线访问公用内存或者其他cpu的内存就比较慢,而且还可能会有一致性的问题。为了解决这个问题,大神们开发了NUMA。这里不做讨论
mmap流程
在3.10内核中,不管是mmap,还是mmap2,还是mmap_pgoff系统调用,对应的实现都在sys_mmap_pgoff中,也就是SYSCALL_DEFINE6(mmap_pgoff,想看完整流程的朋友可以参考这个函数的实现,这里只讲最主要的逻辑实现。
我把内核mmap的流程大致分为三个步骤:
- 内核为进程找到找到一段合适的未被占用的虚拟内存,在进程地址空间的经典布局下,对应的函数为arch_get_unmapped_area。
- 为这段内存分配一个vma结构,并插入到管理vma的数据结构–红黑树中。对应的函数为mmap_region。
- 用户对内存进行读写,触发page fault,内核此时为虚拟内存分配物理内存,对应的函数为do_page_fault。
这篇文章只通过前两个阶段来看内核vma的组织和使用,并不涉及第三阶段。会在之后解析内存反向映射的文章中介绍第三阶段。
arch_get_unmapped_area
此函数的调用路径为:
SYSCALL_DEFINE6(mmap_pgoff
-->vm_mmap_pgoff
-->do_mmap_pgoff
-->get_unmapped_area
-->arch_get_unmapped_area
// 参数和系统调用mmap的参数含义是一样的
arch_get_unmapped_area(struct file *filp, unsigned long addr,
unsigned long len, unsigned long pgoff, unsigned long flags)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma;
struct vm_unmapped_area_info info;
// TASK_SIZE为虚拟空间最大地址,如果申请长度大于最大长度返回报错
if (len > TASK_SIZE)
return -ENOMEM;
// 如果flags中设置了MAP_FIXED,也就是用户指定地址且必须为这个地址
// 详见man mmap
if (flags & MAP_FIXED)
return addr;
// 如果没有设置MAP_FIXED,但是用户建议了一个地址,那么首先检查该区域是否与
// 现存区域重叠。如果不重叠,则将该地址作为目标返回。
if (addr) {
addr = PAGE_ALIGN(addr);
vma = find_vma(mm, addr);
if (TASK_SIZE - len >= addr &&
(!vma || addr + len <= vma->vm_start))
return addr;
}
info.flags = 0;
info.length = len;
info.low_limit = TASK_UNMAPPED_BASE;
info.high_limit = TASK_SIZE;
info.align_mask = 0;
return vm_unmapped_area(&info);
}
可以看到,主要调用了两个函数,find_vma来检查用户指定区域是否与现存区域重叠,如果不重叠则返回用户指定地址。vm_uimapped_area是真正查找空闲区域的函数。
在了解两个函数的实现之前,我们得首先回忆一下进程地址空间的经典布局,也就是mmap区域自低向高增长,也就是addr在下,而addr+len在上。我们把这段区域单独拿出来,也就是要找到这样一段区域
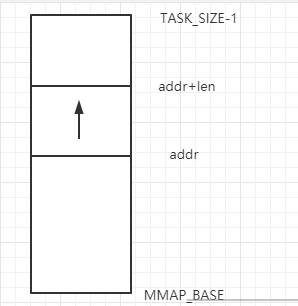
find_vma
现在来看find_vma的实现
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct *find_vma(struct mm_struct *mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = ACCESS_ONCE(mm->mmap_cache);
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
struct rb_node *rb_node;
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while (rb_node) {
struct vm_area_struct *vma_tmp;
vma_tmp = rb_entry(rb_node,
struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
}
return vma;
}
首先我们明确此函数的目的:给定地址,查找是否有一段vma区域覆盖了此地址。何为覆盖,也就是有一段内存区域包含了此地址,画图如下:
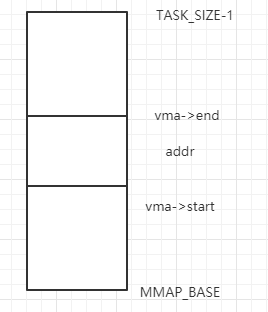
用代码表示也就是vma->end > addr && vma->start <= addr,此为跳出循环的条件。明确了跳出循环的条件后,我们接着看下面的逻辑:首先检查上次处理的区域(mmap_cache)是否符和条件,如果符和条件则直接返回,否则从红黑树的根节点开始查找,而红黑树是根据vma->vm_start对进程内所有的虚拟内存区域进行排序的一个数据结构。
那么在遍历红黑树的过程中,有几个场景需要处理:
- 此vma正好包含了指定的地址,直接返回
- 此vma区域在
addr之后,则需要转到左子树继续查找,因为左子树的地址更低 - 此vma区域在
addr之前,则需要转到右子树继续查找,因为右子树的地址更高
画图如下:
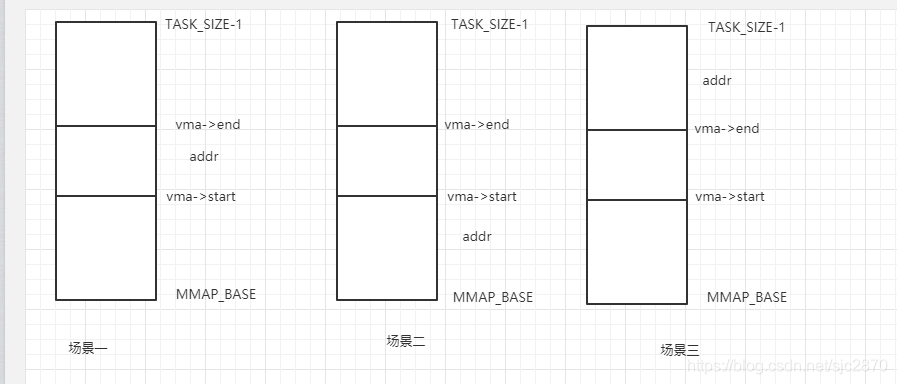
经过这样的遍历查找之后,如果有vma覆盖到了addr此地址则会返回该vma,否则返回NULL。
从find_vma返回之后,有两个判断:ASK_SIZE - len >= addr &&和(!vma || addr + len <= vma->vm_start)前者是为了确认addr+len没有超出最大内存,而后者是为了确认现在没有符和条件的vma,个人感觉addr + len <= vma->vm_start有点多余。
接着往下看,填充一个struct vm_unmapped_area_info结构,最主要的是填充了low_limithigh_limitlengh三个字段,其中low_limit是为了确保从TASK_UNMAPPED_BASE开始分配,而high_limit是为了确保不超过最大虚拟内存。
vm_unmapped_area
这个函数根据进程的地址空间布局,调用不同的函数,经典布局下直接调用unmapped_area
unmapped_area
函数定义见unmapped_area
在分析这个函数的实现前,我们先了解下struct vm_area_struct->rb_subtree_gap字段。我们知道,mmap区域是一个巨大的线性地址,其中有一些地址一些被分配为vma,而剩下的则没有被分配,那根据是否被分配,这个巨大的线性地址就被切割为了一个个片段,如图:
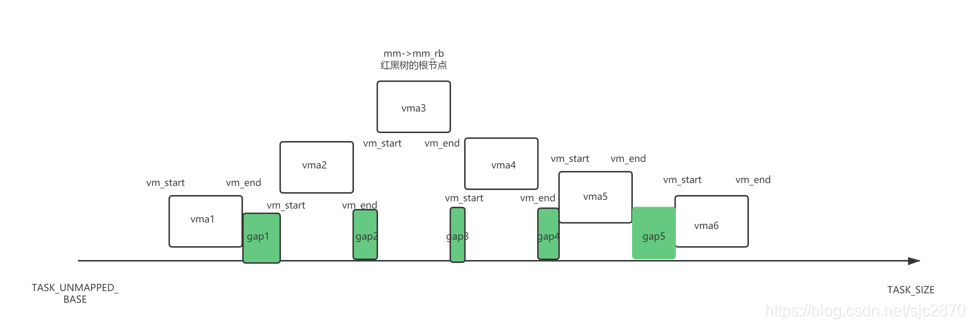
图中的空白区域为已分配的区域,而绿色区域则是还未分配的空洞。
进程把这些区域组织如下:
- 所有已分配的vma组织成一颗红黑树,
mm->mm_rb为红黑树的根节点 - 所有的vma又按序组织成一有序链表,
mm->mmap为链表的头节点。
那么其实有序链表的顺序也就是红黑树中序遍历的顺序。
vma->rb_subtree_gap则是以vma为根节点的tmp_vma与prev_tmp_vma之间的所有gap的最大值。
举例来说,vma3->rb_subtree_gap等于max(gap1, gap2, gap3, gap4, gap5)
vma4->rb_subtree_gap等于max( gap3, gap4, gap5)。
其实这在内核中是用augmented_tree来实现的,这种数据结构有点类似于interval tree,但内核又有所变化,用在这里是很合适的。关于这种数据结构可以上网搜索一下,概念不难,但理解却需要一点时间,这里限于篇幅不再详述。
计算方法对应的函数实现为vma_compute_subtree_gap
那么现在来看unmapped_area的实现,就容易理解的多了。
首先检查根节点的rb_subtree_gap是否小于length,如果小于则说明这棵树所有的空洞都小于length,那么直接跳转到check_highest标号在最高地址处分配内存。否则代表必定有一个未分配的gap内存满足用户的要求,那么接下来要做的就是遍历这颗红黑树,查找一段满足用户要求的未分配的gap,并把基址返回给用户。
对其中的几个变量做下说明:gap_start对应前一个vma的vm_end,gap_end对应正在遍历的vma的vm_start。
具体的查找过程就是一个二叉树的中序遍历:如果左子树的rb_subtree_gap大于length,那么转向左子树继续遍历(1673-1681行)。否则检查vma->vm_start - vma->vm_prev->vm_end > length,也就是检查本vma和前一个vma之间的gap是否大于length,如果大于则跳转到found标号处理(1684-1690行)。否则检查如果右子树的rb_subtree_gap大于length则转到右子树继续遍历(1693-1700行)。否则说明以本vma为根节点的子树都不符和要求,那么跳转到符和要求的父节点(1704-1715行)。
为什么是中序遍历呢,因为mmap要求返回符和用户需求的最小地址,只能是中序遍历。
最后完成搜索后,返回gap_start,也就是将空洞的基址作为一个新的vma的起点。
至此,第一阶段就结束了,我们完成了从线性空间中寻找一个符和用户要求的最低地址。但是仅仅找到地址还不够,还需要管理这个新的vma,下面来看这个过程。
mmap_region
此函数的调用路径是:
SYSCALL_DEFINE6(mmap_pgoff
-->vm_mmap_pgoff
-->do_mmap_pgoff
--> mmap_region
对应的函数实现是mmap_region
首先看下函数原型:
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff)
所有的参数和用户调用mmap的参数含义一样,唯一不同的是addr,这里的addr已经是我们经过查找后找到的一个有效的符和用户要求的addr。
主要流程如下:
- 首先,我们检查地址空间的限制,是否允许我们增长内存。
find_vma_links:查找新的vma在这颗rb_tree(或者说augmented_tree)中的插入位置,前一个vma和新vma的父节点。具体的过程和上面find_vma的过程类似,这里不再详述。vma_merge:检查是否可以和现存vma合并,如果地址相邻而且访问权限和内存策略等都一样,那么可以合并。- 接着分配新的vma结构并赋值
vm_mmvm_startvm_endvm_flagsvm_page_protvm_pgoffanon_vma_chain。注意这里的vm_pgoff等于用户传入的offset >> PAGE_SHIFT,也就是等于在文件内的起始偏移量,单位是页。 - 如果是文件映射,那么调用文件的mmap方法,一般设置为
generic_file_mmap,主要是vma->vm_ops = generic_file_vm_ops,为了page fault时分配物理内存。 vma_link:将新的vma加入到链表和rb_tree(或者说是augmented_tree)中方便管理
可以看到,前面都是一些检查和准备工作,最主要的就是调用vma_link,把新的vma加入到链表和augmented_tree中管理,这个函数主要调用__vma_link和__vma_link_file.而__vma_link主要调用__vma_link_list和__vma_link_rb。
__vma_link_list,顾名思义,将vma加入链表处理,这里逻辑很简单,读者可以自行阅读。
我们主要讲解__vma_link_rb。可能读者会问,这里不也就是加入红黑树管理吗。答案是的,但是因为rb_subtree_gap这个字段的存在,这个过程变得不再简单,下面我们逐行讲解这个函数。
__vma_link_rb
void __vma_link_rb(struct mm_struct *mm, struct vm_area_struct *vma,
struct rb_node **rb_link, struct rb_node *rb_parent)
{
/* Update tracking information for the gap following the new vma. */
if (vma->vm_next)
vma_gap_update(vma->vm_next);
else
mm->highest_vm_end = vma->vm_end;
/*
* vma->vm_prev wasn't known when we followed the rbtree to find the
* correct insertion point for that vma. As a result, we could not
* update the vma vm_rb parents rb_subtree_gap values on the way down.
* So, we first insert the vma with a zero rb_subtree_gap value
* (to be consistent with what we did on the way down), and then
* immediately update the gap to the correct value. Finally we
* rebalance the rbtree after all augmented values have been set.
*/
rb_link_node(&vma->vm_rb, rb_parent, rb_link);
vma->rb_subtree_gap = 0;
vma_gap_update(vma);
vma_rb_insert(vma, &mm->mm_rb);
}
首先明确,我们进入此函数时,vma已经被加入到链表管理。
如果vma->vm_next不为空,那么这个新的vma其实对应vma->next和原先我们未分配内存时的vma->next->vm_prev对应的空洞gap,但空洞gap此时已经被用作内存使用,所以gap也需要相应的更新。vma_gap_update主要调用了vma_gap_callbacks_propagate,但居然发现无法找到vma_gap_callbacks_propagate这个函数的定义?
原来,内核使用了一个宏来定义这个函数
#define RB_DECLARE_CALLBACKS(rbstatic, rbname, rbstruct, rbfield, \
rbtype, rbaugmented, rbcompute) \
static inline void \
rbname ## _propagate(struct rb_node *rb, struct rb_node *stop) \
{ \
while (rb != stop) { \
rbstruct *node = rb_entry(rb, rbstruct, rbfield); \
rbtype augmented = rbcompute(node); \
if (node->rbaugmented == augmented) \
break; \
node->rbaugmented = augmented; \
rb = rb_parent(&node->rbfield); \
} \
} \
static inline void \
rbname ## _copy(struct rb_node *rb_old, struct rb_node *rb_new) \
{ \
rbstruct *old = rb_entry(rb_old, rbstruct, rbfield); \
rbstruct *new = rb_entry(rb_new, rbstruct, rbfield); \
new->rbaugmented = old->rbaugmented; \
} \
static void \
rbname ## _rotate(struct rb_node *rb_old, struct rb_node *rb_new) \
{ \
rbstruct *old = rb_entry(rb_old, rbstruct, rbfield); \
rbstruct *new = rb_entry(rb_new, rbstruct, rbfield); \
new->rbaugmented = old->rbaugmented; \
old->rbaugmented = rbcompute(old); \
} \
rbstatic const struct rb_augment_callbacks rbname = { \
rbname ## _propagate, rbname ## _copy, rbname ## _rotate \
};
RB_DECLARE_CALLBACKS(static, vma_gap_callbacks, struct vm_area_struct, vm_rb,
unsigned long, rb_subtree_gap, vma_compute_subtree_gap)
内核使用这个面目狰狞的宏分别定义了三个函数vma_gap_callbacks_propagate vma_gap_callbacks_copy vma_gap_callbacks__rotate和一个变量vma_gap_callbacks。
vma_gap_callbacks_propagate用作更新vma节点的rb_subtree_gap以及更新父节点,祖父节点一直到指定的节点。但这里我们指定的节点为NULL,也就是一直更新到根节点,这是符和逻辑的。
接着往下看,如果vma->vm_next为空,说明我们是扩展了mmap区域的最高地址,那么此时需要更新它。
rb_link_node是真正的把新的vma节点插入rbtree或者说是augmented_tree中
下一句vma->rb_subtree_gap = 0;是为什么呢?我的理解是,因为此vma可能是本进程内分配的首个vma,所以这种场景下rb_subtree_gap就为0,这里设置为0也是起到一个默认值的作用。如果不是首个vma,在后面调用vma_gap_update更新就好了。
最后来看vma_rb_insert,这个函数主要实现了红黑树的旋转和相应地更新rb_subtree_gap的作用。
static inline void vma_rb_insert(struct vm_area_struct *vma,
struct rb_root *root)
{
/* All rb_subtree_gap values must be consistent prior to insertion */
validate_mm_rb(root, NULL);
rb_insert_augmented(&vma->vm_rb, root, &vma_gap_callbacks);
}
第一个函数首先对树内所有节点确认rb_subtree_gap有效,如果无效则直接BUG
第二个函数则用到了上面那个面目狰狞的宏所定义的变量vma_gap_callbacks,其中包含了定义的三个函数,我们这里会用到vma_gap_callbacks__rotate。我们知道,红黑树在插入新节点后,为了保持平衡是需要旋转节点的,那么这样一旋转,节点的vma_gap_callbacks就有可能改变,这里的vma_gap_callbacks__rotate就是为了保证节点旋转后对应vma的vma_gap_callbacks也可能相应地更新。
红黑树旋转的操作超出了这篇文章的范围,这里不再详述,有兴趣的读者可以自行阅读代码学习。vma_gap_callbacks__rotate的实现逻辑也很容易理解,把旋转节点的vma_gap_callbacks更新为被旋转节点的vma_gap_callbacks,然后更新被旋转节点的vma_gap_callbacks值。
至此,我们终于把新的vma节点加入到了链表和红黑树中正确的管理起来。最后来看__vma_link_file的实现
__vma_link_file
static void __vma_link_file(struct vm_area_struct *vma)
{
struct file *file;
file = vma->vm_file;
if (file) {
struct address_space *mapping = file->f_mapping;
if (vma->vm_flags & VM_DENYWRITE)
atomic_dec(&file_inode(file)->i_writecount);
if (vma->vm_flags & VM_SHARED)
mapping->i_mmap_writable++;
flush_dcache_mmap_lock(mapping);
if (unlikely(vma->vm_flags & VM_NONLINEAR))
vma_nonlinear_insert(vma, &mapping->i_mmap_nonlinear);
else
vma_interval_tree_insert(vma, &mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
}
}
其实这里主要是更新两个变量和为内存反向映射做准备。更新两个变量的逻辑比较容易理解,内存反向映射内容较多,下篇文章单独讲解
总结
其实本来只想看mmap的实现,结果mmap与虚拟内存强相关,也就变成了虚拟内存的组织管理与使用。总的来说,内核主要使用链表和红黑树来管理虚拟内存,通过把巨大的线性地址划分为一个个的vma和gap,vma中含有gap的信息,以此在分配新的内存过程中判断能否在gap中分配。在内核3.8之前,这个过程是通过对链表进行线性遍历来查找合适的区域,而3.8之后使用augented_tree和一个新的遍历rb_subtree_gap来实现O(logn)内查找合适的区域,是一个巨大的的性能提升。
遗憾的是这篇文章可能写的并不如想象中的那样详细,要交待的东西太多了,有点杂乱无章。本来还想写详细写一下augented tree和interval tree,想了想是属于数据结构的部分了,并不严格属于内核,也限于篇幅,没有交待这部分内容,有机会可以写一个关于interval tree的文章。
敬请期待下篇,从内存反向映射的实现来看vma的组织和使用,会补上这篇文章没有讲解的shared anno_vma anon_vma_chain几个字段和第三阶段的Page fault。
参考资料
《Linux内核源代码情景分析》
《深入linux内核架构》
红黑树 IN Linux (一)
【kernel doc】rbtree
【kernel doc】【vm】numa_memory_policy
Process address space
画图:https://www.processon.com/















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









