







 本文详细介绍了如何实现一个基于Deep Q-learning Network(DQN)的二叉树状态学习模型,旨在训练agent从状态0找到通向目标状态6的最短路径。通过神经网络替代传统q-table,提升智能和适应性。文中提供了源代码,并对关键函数进行了注释解释,适合对深度强化学习感兴趣的读者进行学习和交流。
本文详细介绍了如何实现一个基于Deep Q-learning Network(DQN)的二叉树状态学习模型,旨在训练agent从状态0找到通向目标状态6的最短路径。通过神经网络替代传统q-table,提升智能和适应性。文中提供了源代码,并对关键函数进行了注释解释,适合对深度强化学习感兴趣的读者进行学习和交流。
实现一个Deep Q-learning Network(二叉树状态DQN)
代码主要解决的问题: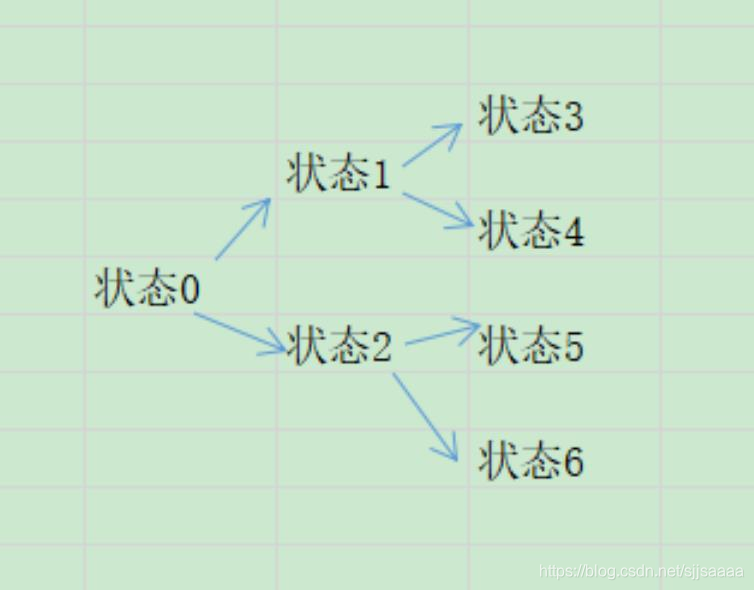
有0-6,7个状态,从上图是他们可以状态跳转的方向和关系。
我们设定状态6是最终GDAL,目标,训练agent能够从状态0,通过若干次的训练,他能够知道捷径是什么:0-2-6.但一开始agent是不知道的。
源代码:
源代码每一行都有注释,有助于理解。
import numpy as np #导入科学计算库
GENMAX=4000 #学习循环次数
STATENO=7 #状态数
ACTIONNO=2 #动作数
ALPHA=0.1 #学习率
GAMMA=0.9 #off-policy 率
EPSILON=0.3 #
SEED=65535 # 随机种子
REWARD=1 #奖励
GOAL=6#目标状态
UP=0 #动作上,就是状态右上走
DOWN=1 #动作下,就是状态右下走
LEVEL=2 #状态层数
INPUTNO=7 #输入神经元数量
HIDDENNO=2 #隐藏层神经元数量
OUTPUTNO=2 #输出神经元数量
NNALPHA=3 #神经网络Neural Network 学习系数
def updateq(s,snext,a,wh,wo,hi): #更新q值
qv=0 #初始化q-value = 0
qvalue_sa=0 #初始化q-value_state-action 用于获取神经网络的输出值
qvalue_snexta=0 #获取下一个状态下的q_value神经网络值
e=np.zeros((INPUTNO+1)) #初始化神经网络输入值
e[s]=1 #对输入进行设定
qvalue_sa=forward(wh,wo[a],hi,e) #返回神经网络在当前a和当前状态e的值
e[s]=0 #清空输入
e[snext]=1 #获取假定已经跳转到下一个状态的时候的神经网络初始化
qvalue_snexta=forward(wh,wo[set_a_by_q(snext,wh,wo,hi)],hi,e)
#下一个状态下的神经网络计算的qvalue
if snext==GOAL :#如果下一个状态是目标
qv=qvalue_sa+ALPHA*(REWARD-qvalue_sa) #累加q-value奖励
else:#如果下一个状态不是目标
qv=qvalue_sa+ALPHA*(GAMMA*qvalue_snexta-qvalue_sa) #进行有折扣的累加
return qv #返回当前状态和动作下的q值
def selecta(s,wh,wo,hi): #通过 当前状态+神经网络参数 => 选择动作
a=0
if(frand()<EPSILON): # 有一定概率的随机选择怎么走
a=rand0or1() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











