







Hashmap源码解读
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
关系继承
-
继承了AbstractMap<K,V>
-
实现了Map<K,V>,Cloneable,Serializable
- Cloneable空接口,表示可以克隆,创建并返回HashMap对象的一个副本。
- Serializable序列化接口,属于标记性接口,HashMap对象可以被序列化和反序列化
- AbstracMap父类提供了Map实现接口,以最大限度的减少实现此接口所需的工作
算法前提
- Hash简单实现
- 红黑树实现
简写HashMap8之前版本算法
package redisprc.test;
import java.util.*;
/**
* @Author lijiaxin
* @Description TODO
* @Date 2022/07/27/15:55
* @Version 1.0
*/
public class myMap<K, V> {
private Node<K,V>[] nodes;
private int size;
private static class Node<K,V> {
K key;
V value;
Node(K key,V value){
this.key = key;
this.value = value;
}
}
public void put(K key,V value){
if(nodes == null){
nodes = new Node[10];
}
int index = indexOfkey(key);
if (index!=-1){
nodes[index].value = value;
}else {
nodes[size] = new Node<K, V>(key,value);
size++;
}
}
private int indexOfkey(K key){
for (int index = 0; index < size; index++) {
if (key.equals(this.nodes[index].key)){
return index;
}
}
return -1;
}
public V get(K key){
int index = indexOfkey(key);
if (index!=-1){
return nodes[index].value;
}
return null;
}
public int size(){
return size;
}
}
简写红黑树算法
代码模块
package com.ljx.rebclackTree;
import javax.lang.model.util.Elements;
/*
* 创建RbTree,定义颜色
* 创建RBBNode
* 辅助方法,parentOF(node),isRed(node),isBlack(node),setRed(node),
* setBlack(node),InOrderPrint()
* 左旋方法定义leftRotate(node)
* 右旋方法定义rightRoate(node)
* 公开插入接口的方法定义insert(K key,V value)
* 内部插入接口定义方法insert(RBNode node)
* 修正插入导致红黑树失衡的放那份嘎定义:insertFixUp(RBNode node)
* */
public class RBTree<K extends Comparable<K>,V>{
private static final boolean RED = true;
private static final boolean BLACK = false;
/* 树根的引用*/
private RBNode root;
public RBNode getRoot() {
return root;
}
public void setRoot(RBNode root) {
this.root = root;
}
/*获取当前节点的父节点*/
private RBNode parentOf(RBNode node){
if (node!=null){
return node.parentp;
}
return null;
}
/*节点红黑判断*/
private boolean isRed(RBNode node){
return node!=null&&node.color == RED;
}
private boolean isBlack(RBNode ndoe){
return ndoe!=null&&ndoe.color == BLACK;
}
/*设置当前节点颜色红黑*/
private void setRed(RBNode node){
if (node!=null){
node.color = RED;
}
}
private void setBlack(RBNode node){
if (node!=null){
node.color = BLACK;
}
}
/*中序打印左中右*/
private void InOrderPrint(){
inOrderPrint(this.root);
}
private void inOrderPrint(RBNode node){
if (node!=null){
inOrderPrint(node.left);
System.out.println("key:"+node.key+",value:"+node.value);
inOrderPrint(node.right);
}
}
/*公开插入的方法*/
public void insert(K key,V value){
RBNode node = new RBNode();
node.setColor(RED);
node.setKey(key);
node.setValue(value);
insert(node);
}
private void insert(RBNode node){
RBNode parent = null;
RBNode x = this.root;
while (x!=null){
parent = x;
/*三种情况
* com>0 说明node.key大于x.key,需要到x的右子树寻找
* com=0 说明node.key等于x.key,需要进行替换操作
* com<0 说明node.key小于x.key,需要到x的左子树进行查找*/
int cmp = node.key.compareTo(x.key);
if (cmp>0){
x = x.right;
}else if(cmp<0){
x = x.left;
}else {
x.setValue(node.getValue());
return;
}
}
node.parentp = parent;
/*再这里进行node和parent的key值判断,判断parent是在左子树还是右子树
* 防止红黑树为空,此时的话parent就会为空*/
if (parent!=null){
int cmp = node.key.compareTo(parent.key);
if(cmp>0){
/*当node的key大于parent的key时,需要把弄的放入parent右节点*/
parent.right = node;
}else {
/*当node的key小于parent的key时将其放入parent左节点*/
parent.left = node;
}
}else {
/*红黑树为空,直接等于根节点*/
this.root = node;
}
insertFixUP(node);
}
/*插入后修复红黑树平衡的方法
* 情景1:红黑树为空
* 情景2:插入节点的key已经存在,不需要处理,已经在插入进行了替换
* 情景3:插入节点的父节点为黑色,因为需要插入2⃣路径,黑色节点没有变化
* 所以红黑树依旧平衡,不需要处理
* 情景4:插入节点的父节点为红色
* 子情景1:叔叔节点存在,并且为红色(父叔双红)
* 将父节点和叔叔节点变为黑色,将祖父节点变为红色,并设置祖父接的为当前节点
* 子情景2:叔叔节点不存在,或为黑色,父节点为爷爷节点的左子树
* 孙子情景1:插入节点为其父节点的左子节点(LL的情况)
* 将父节点染成黑色,将祖父节点染成红色并进行右旋
* 孙子情景2:插入节点为其父节点的右子节点(LR的情况)
* 以父亲节点进行左旋
* 子情景3:叔叔节点不存在,或者为黑色,父节点为爷爷节点的右子树
* 孙子情景1:插入节点为其父节点的左子节点(RL的情况)
* 以父亲节点进行右旋
* 孙子情景2:插入纠结的为其父节点的右子节点
* 将父节点染成黑色,将祖父节点染成红色,进行左旋*/
private void insertFixUP(RBNode node){
this.root.setColor(BLACK);
/*拿到父亲节点*/
RBNode parent = parentOf(node);
RBNode gparent = parentOf(parent);
//如果父亲节点是红色的情况
if (parent!=null&&isRed(parent)){
//进入情景4
RBNode uncle = null;
if (parent == gparent.left){
uncle=gparent.right;
if (uncle!=null&&isRed(uncle)){
//4.1
setBlack(parent);
setBlack(uncle);
setRed(gparent);
insertFixUP(gparent);
return;
}
if (uncle==null||isBlack(uncle)){
//4.2
//(ll)
if (node==parent.left){
setBlack(parent);
setRed(gparent);
rightRotate(gparent);
return;
}
//(lr)
if (node==parent.right){
leftRotate(parent);
insertFixUP(parent);
return;
}
}
}else {
uncle=gparent.left;
if (uncle!=null&&isRed(uncle)){
setBlack(parent);
setBlack(uncle);
setRed(gparent);
insertFixUP(gparent);
return;
}
//情景4。3
if (node==parent.left){
//(Rl)
rightRotate(parent);
insertFixUP(parent);
return;
}
if (node==parent.right){
//情景4.3.2(RR)
// 将父亲结点染成黑色,将祖父结点染成红色,进行左旋
setBlack(parent);
setRed(gparent);
leftRotate(gparent);
return;
}
}
}
}
//左旋右旋方法
public void leftRotate(RBNode x){
RBNode y = x.right;
//1.将y的左子结点的父结点更新为x,将x的右子节点更新为y的左子结点
x.right = y.left;
if (y.left!=null){
y.left.parentp=x;
}
//当x的父节点不为空时,更新y的父节点为x的父节点,并将x的父节点的指定子树(当前x的子树位置指定为y
if (x.parentp!=null){
y.parentp = x.parentp;
if (x==x.parentp.left){
x.parentp.left=y;
}else {
x.parentp.right=y;
}
}else {
//x是root
this.root = y;
this.root.parentp=null;
}
//将x的父节点更新为y,将y的左子节点更新为x
x.parentp=y;
y.left=x;
}
public void rightRotate(RBNode y){
RBNode x = y.left;
// 1.将y的左子结点更新为x的右子节点,如果x的右子节点不为空,将x的右子节点的父节点更新为y
y.left =x.right;
if (x.right!=null){
x.right.parentp=y;
}
// 2.当y的父节点不为空时,将x的父节点更新为y的父节点,将y的父节点的指定子树更新为x
if (y.parentp!=null){
x.parentp=y.parentp;
if (y == y.parentp.left){
y.parentp.left=x;
}else {
y.parentp.right=x;
}
}else {
//y为根节点
this.root=x;
this.root.parentp=null;
}
// 3.将y的父节点更新为x,将x的右子节点更新为y
y.parentp=x;
x.right=y;
}
static class RBNode<K extends Comparable<K>,V> {
/*父节点*/
private RBNode parentp;
/*左节点*/
private RBNode left;
/*右节点*/
private RBNode right;
/*颜色*/
private boolean color;
/*K*/
private K key;
/*V*/
private V value;
@Override
public String toString() {
return "RBNode{" +
"parentp=" + parentp +
", left=" + left +
", right=" + right +
", color=" + color +
", key=" + key +
", value=" + value +
'}';
}
public RBNode(RBNode parentp, RBNode left, RBNode right, boolean color, K key, V value) {
this.parentp = parentp;
this.left = left;
this.right = right;
this.color = color;
this.key = key;
this.value = value;
}
public RBNode getParentp() {
return parentp;
}
public void setParentp(RBNode parentp) {
this.parentp = parentp;
}
public RBNode getLeft() {
return left;
}
public void setLeft(RBNode left) {
this.left = left;
}
public RBNode getRight() {
return right;
}
public void setRight(RBNode right) {
this.right = right;
}
public boolean isColor() {
return color;
}
public void setColor(boolean color) {
this.color = color;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
public RBNode(){
}
}
}
矩阵展示模块
package com.ljx.rebclackTree;
// TreeOperation.java
public class TreeOperation {
/*
树的结构示例:
1
/ \
2 3
/ \ / \
4 5 6 7
*/
// 用于获得树的层数
public static int getTreeDepth(RBTree.RBNode root) {
return root == null ? 0 : (1 + Math.max(getTreeDepth(root.getLeft()), getTreeDepth(root.getRight())));
}
private static void writeArray(RBTree.RBNode currNode, int rowIndex, int columnIndex, String[][] res, int treeDepth) {
// 保证输入的树不为空
if (currNode == null) return;
// 先将当前节点保存到二维数组中
res[rowIndex][columnIndex] = String.valueOf(currNode.getKey()+"-"+(currNode.isColor()?"R":"B")+"");
// 计算当前位于树的第几层
int currLevel = ((rowIndex + 1) / 2);
// 若到了最后一层,则返回
if (currLevel == treeDepth) return;
// 计算当前行到下一行,每个元素之间的间隔(下一行的列索引与当前元素的列索引之间的间隔)
int gap = treeDepth - currLevel - 1;
// 对左儿子进行判断,若有左儿子,则记录相应的"/"与左儿子的值
if (currNode.getLeft() != null) {
res[rowIndex + 1][columnIndex - gap] = "/";
writeArray(currNode.getLeft(), rowIndex + 2, columnIndex - gap * 2, res, treeDepth);
}
// 对右儿子进行判断,若有右儿子,则记录相应的"\"与右儿子的值
if (currNode.getRight() != null) {
res[rowIndex + 1][columnIndex + gap] = "\\";
writeArray(currNode.getRight(), rowIndex + 2, columnIndex + gap * 2, res, treeDepth);
}
}
public static void show(RBTree.RBNode root) {
if (root == null) System.out.println("EMPTY!");
// 得到树的深度
int treeDepth = getTreeDepth(root);
// 最后一行的宽度为2的(n - 1)次方乘3,再加1
// 作为整个二维数组的宽度
int arrayHeight = treeDepth * 2 - 1;
int arrayWidth = (2 << (treeDepth - 2)) * 3 + 1;
// 用一个字符串数组来存储每个位置应显示的元素
String[][] res = new String[arrayHeight][arrayWidth];
// 对数组进行初始化,默认为一个空格
for (int i = 0; i < arrayHeight; i ++) {
for (int j = 0; j < arrayWidth; j ++) {
res[i][j] = " ";
}
}
// 从根节点开始,递归处理整个树
// res[0][(arrayWidth + 1)/ 2] = (char)(root.val + '0');
writeArray(root, 0, arrayWidth/ 2, res, treeDepth);
// 此时,已经将所有需要显示的元素储存到了二维数组中,将其拼接并打印即可
for (String[] line: res) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < line.length; i ++) {
sb.append(line[i]);
if (line[i].length() > 1 && i <= line.length - 1) {
i += line[i].length() > 4 ? 2: line[i].length() - 1;
}
}
System.out.println(sb.toString());
}
}
}
测试
package com.ljx.rebclackTree;
// TreeOperation.java
public class TreeOperation {
/*
树的结构示例:
1
/ \
2 3
/ \ / \
4 5 6 7
*/
// 用于获得树的层数
public static int getTreeDepth(RBTree.RBNode root) {
return root == null ? 0 : (1 + Math.max(getTreeDepth(root.getLeft()), getTreeDepth(root.getRight())));
}
private static void writeArray(RBTree.RBNode currNode, int rowIndex, int columnIndex, String[][] res, int treeDepth) {
// 保证输入的树不为空
if (currNode == null) return;
// 先将当前节点保存到二维数组中
res[rowIndex][columnIndex] = String.valueOf(currNode.getKey()+"-"+(currNode.isColor()?"R":"B")+"");
// 计算当前位于树的第几层
int currLevel = ((rowIndex + 1) / 2);
// 若到了最后一层,则返回
if (currLevel == treeDepth) return;
// 计算当前行到下一行,每个元素之间的间隔(下一行的列索引与当前元素的列索引之间的间隔)
int gap = treeDepth - currLevel - 1;
// 对左儿子进行判断,若有左儿子,则记录相应的"/"与左儿子的值
if (currNode.getLeft() != null) {
res[rowIndex + 1][columnIndex - gap] = "/";
writeArray(currNode.getLeft(), rowIndex + 2, columnIndex - gap * 2, res, treeDepth);
}
// 对右儿子进行判断,若有右儿子,则记录相应的"\"与右儿子的值
if (currNode.getRight() != null) {
res[rowIndex + 1][columnIndex + gap] = "\\";
writeArray(currNode.getRight(), rowIndex + 2, columnIndex + gap * 2, res, treeDepth);
}
}
public static void show(RBTree.RBNode root) {
if (root == null) System.out.println("EMPTY!");
// 得到树的深度
int treeDepth = getTreeDepth(root);
// 最后一行的宽度为2的(n - 1)次方乘3,再加1
// 作为整个二维数组的宽度
int arrayHeight = treeDepth * 2 - 1;
int arrayWidth = (2 << (treeDepth - 2)) * 3 + 1;
// 用一个字符串数组来存储每个位置应显示的元素
String[][] res = new String[arrayHeight][arrayWidth];
// 对数组进行初始化,默认为一个空格
for (int i = 0; i < arrayHeight; i ++) {
for (int j = 0; j < arrayWidth; j ++) {
res[i][j] = " ";
}
}
// 从根节点开始,递归处理整个树
// res[0][(arrayWidth + 1)/ 2] = (char)(root.val + '0');
writeArray(root, 0, arrayWidth/ 2, res, treeDepth);
// 此时,已经将所有需要显示的元素储存到了二维数组中,将其拼接并打印即可
for (String[] line: res) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < line.length; i ++) {
sb.append(line[i]);
if (line[i].length() > 1 && i <= line.length - 1) {
i += line[i].length() > 4 ? 2: line[i].length() - 1;
}
}
System.out.println(sb.toString());
}
}
}
做了这么多准备工作,该开始读源码了
量值定义
- 变量一
private static final long serialVersionUID = 362498820763181265L;
定义序列化id,使其可以序列化
- 变量二
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
集合的初始化容量
- 变量三
static final int MAXIMUM_CAPACITY = 1 << 30;
扩容最大范围值2^30次方
- 变量四
static final float DEFAULT_LOAD_FACTOR = 0.75f;
扩容因子初始大小0,75
- 变量四
static final int TREEIFY_THRESHOLD = 8;
链表的初始长度,超过8时将会转为红黑树
- 变量五
static final int UNTREEIFY_THRESHOLD = 6;
hash桶,当超过这个值时将会转为链表
- 变量六
static final int MIN_TREEIFY_CAPACITY = 64;
桶结构转化为红黑树的数组容量最小值
HashMap实例化方法
- 方法1
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
传入参数:Node数组大小和负载因子(初始扩容因子)
- 当初始的Node数组大小小于0,会抛出异常
- 当初始的Node数组大小大于最大扩容量时直接等于最大的扩容量
- 当负载因子小于0,或者不是数组的时候(NaN=>Not a number),抛出异常
- 将两个传如的数值参数赋给最初的map
- 方法2
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
直接进行上面的方法1进行初始长度比较
- 方法3
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
将刚开始i的最初负载因子传给HashMap位此时的负载因子,再觉得后面是否要进行扩容
- 方法4
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
初始负载因子赋位默认值
内部方法putMapEntries
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
-
传入参数,泛型类型的Map集合,和辅助判断
-
计算map的长度
-
当map长度大于0时,判断Hashmap是否初始化
-
然后对此时的map集合进行初始化计算,默认大小乘以负载因子,并加上1.0f使其转为float的类型
-
然后对此时的长度和扩容最大值进行比较,当小于最大值时,条件成立,为此时的扩容大小,否则扩容到数组的最大限额
-
当数组长度大于最大限额时,对这个数据底层进行调整
-
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } 再次进行位运算对他的大小进行调整

-
当已经被初始化过时,且当前长度大于初始化长度,则使用reszie方法进行扩容
-
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } loadFactor的默认值(DEFAULT_LOAD_FACTOR)是0.75,这是一个折中的取值,也就是说,默认情况下,数组大小为16,那么当HashMap中的元素个数超过16x0.75=12(这个值就是阈值或者边界值threshold值)的时候,就把数组的大小扩展为2x16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,这是一个非常耗性能的操作,所以如果我们已经预知HashMap中元素的个数,这能很好的提高HashMap的性能- 扩容之后的索引位置要么是原来的位置的索引,要么是原来索引+旧数组容量
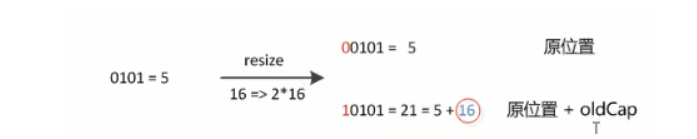
- 因此我们在扩容HashMap的时候,不需要重新计算hash,只需要来看看原来的hash值新增的那个bit是1还是0就可以了,是0的话索引不变,是1的话索引变成原位置+旧容量,可以看看下图为16扩充为32的resize示意图

- 首先引用扩容前的哈希表
- oldTab表示扩容前数组的大小
- 然后获取旧哈希表的扩容阈值
- 同时设立扩容后table数组的大小,以及设置扩容的触发条件
- 当条件成立则说明hashMap中的散列表已经初始化过了,是一场正常扩容
- 再次进行判断查看旧的容量是否大于最大值容量,如果是,则无法扩容,并设置扩容条件作为intd的最大值
- 并且设置newCap的容量为oldCap的二倍,并且雄安与最大容量,且大于16,则新阈值等于旧阈值的2倍,且新阈值大于旧阈值的2倍
- 如果oldcap=0且边界值大于0,说明三例表为null但此时oldThr>0 ,说明此时hashMap的创建是通过指定的构造方法创建的,新容量直接等于阈值
- 此种情况oldThr;oldThr说明没有经过初始化,创建hashMap通过new的方式创建
- 后面再次进入判断当newThr为0时,通过newChr和loadFactor计算出一个newThr
- 然后通过上面计算出一个更大的结果,并将table指向新建的数组,本次扩容之前table不为null,然后对数组中的元素进行遍历
- 设e为当前node节点
- 将老数组j桶位置为空,方便回收,如果e节点不存在下一个节点,说明e是单个元素,则直接放置在新数组的桶位
- 接下来进行判断,e是树节点,还是链表节点,如果是树节点则证明此时进行的是红黑树算法,如果为链表节点,则直接对链表进行遍历
- 当进入链表算法时会分为低位链表和高位链表
- 当为低位链表时,存放在扩容之后的数组的下标位置,与当前数组下标位置一致
- 当为高位链表,存放扩容之后的数组的下标,=原索引+扩容之前数组容量
- oldCap为16:10000,与e.hsah做&运算可以得到高位为1还是0
- 高位为0,放在低位链表,并将头节点loHead指向在原位
- 高位为1,放在高位链表,并将头节点指向新索引
-
然后进行遍历将key,value赋值给这个传到的参数map
-
然后进入方法putVal
-
中间使用方法hash() static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
如果key为空,则为0,不为空进行hash计算
-
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } -

-
传入参数hash,以及数据key和value
-
定义节点数据,节点p,和长度n,i
-
如果map中此时的数组table,并且等于null,且数组长度为0,如果为空就进行初始化
-
检查table中位置为(n-1)&hash是否为空,如果为空,直接放入
-
如果桶中存在的元素的key和hash相等,则直接覆盖旧value
-
判断存放该元素的链表知否转换为红黑树,如果为红黑树则直接插入,此时上面的桶覆盖不存在
-
当桶算法和红黑树算法度不成立时,则直接将元素放入链表,此时如果key和hash相等时,则直接覆盖value
-
并将记录修改次数加1,再进行扩容判断,当大于阈值时进行扩容

-
Node方法分析
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
-
方法实现Map接口
-
首先定义了final类型变量hash和key,和普通的泛型的value属性,并定义节点next
-
构造内部节点方法
-
接着实现get ,set,toString(),hashCode(),equals()方法
comparableClassFor方法
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}
相当于集合对Comparabel方法的重写比较规则
get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
输入节点的kkey,通过hash计算获取到此时的值
containkey方法
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
通过输入元素进行hash计算后找到该元素的值
getNode方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
建立节点数组,建立两个类型节点
- 先判断数组是否被初始化并定义一个标志节点(进行数组取值,链表还是红黑树)
- 先让这个节点等于数组的第一个节点的,然后将他与数组的第一个hash值进行判断
- 当不符合时选择进入链表算法还是红黑树算法
put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
使用putVal去存值
treeifybin方法
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
先判断数组是否进行了初始化判断他是否小于最大值,然后进行扩容
当e = tab[index = (n - 1) & hash]) != nul进入红黑树算法
remove()方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
通过传入存储时的key,然后计算hash后删除该节点
removeNode方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
跟addNode方法类似,先判断,然后依次按数组,红黑树,链表进行判断
clear方法
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
判断数组是否初始化,然后将数组的每个值通过遍历变为null
containsValue()
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
通过节点的值判断是否存在,不需要经过hash计算















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









