







使用MybatisPlus的SimpleQuery工具类可以对查询出来的数据结果进行Stream流的封装,也可以指定具体的返回结果,并且这种方式不需要调用service以及mapper中的接口方法,就可以返回数据查询的结果,极大的简化了开发效率,也简化了代码,并且也对数据的结果做出了一定的封装。
代码实现:
package com.example.mybatisdemo3;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.toolkit.SimpleQuery;
import com.example.mybatisdemo3.domain.Student;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.function.Consumer;
/**
* @BelongsProject: mybatisplusdemo
* @BelongsPackage: com.example.mybatisdemo3
* @Author: 云边小屋(My.Tears)
* @CreateTime: 2023-06-19 18:28
*/
@SpringBootTest
public class SimpleQueryTest {
/**
* list重载的许多 我只解释其中一种
* 第一个参数是条件对象
* 第二个参数是对条件查询对象查询出来的值 进行筛选 例如我查询出来的许多值 但是我只选择其中的一列进行返回,那么就将筛选后的数据进行封装集合,也就是筛选
* 第三个参数消费性接口 他会对你获取的数据进行一些消费操作 例如获取修改信息的内容
* public static <E, A> List<A> list(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, Consumer<E>... peeks) {
* return list2List(Db.list(wrapper.setEntityClass(getType(sFunction))), sFunction, peeks);
* }
*/
@Test
void list1() {
// 封装某一列数据 通过SimpleQuery.list()来拿到某一个数据的集合 我这里是查询年龄为18的全部数据
// 将年龄为18的数据全部查询出来 并根据id来封装
List<Long> list = SimpleQuery.list(new LambdaQueryWrapper<Student>().eq(Student::getAge, 18), Student::getId);
for (Long aLong : list) {
System.out.println("年龄为18的id编号: --> " + aLong);
}
// 可以简写 -- > SimpleQuery.list(new LambdaQueryWrapper<Student>().eq(Student::getAge, 18), Student::getId).forEach(System.out::println);
}
/**
* 第一种未使用消费性接口
* 第二种使用消费性接口
*/
@Test
void list2() {
/**
* 代码意思 --> 不设置条件查询内容 那么就查询所有的数据 将查询出来的所有的数据
* 根据姓名封装筛选出来 那么查询结果只返回姓名
* 在根据消费性接口 进行处理
* 以下可以简写成Lambda表达式的形式
*/
List<String> list = SimpleQuery.list(new LambdaQueryWrapper<Student>(), Student::getName, new Consumer<Student>() {
@Override
public void accept(Student student) {
/**
* 调用Optional.of返回所有的name属性 在将name的值通过map()方法里面的toUpperCase全部替换成大写
* 然后在通过ifPresent(student::setName)将参数设置为大写
*/
Optional.of(student.getName()).map(String::toUpperCase).ifPresent(student::setName);
}
});
list.forEach(System.out::println);
}
/**
* map重载的许多 我只解释其中一种
* 第一个参数条件对象
* 第二个参数筛选的key值
* 第三个参数筛选的value值
* 第四个参数是消费性接口
* public static <E, A, P> Map<A, P> map(LambdaQueryWrapper<E> wrapper, SFunction<E, A> keyFunc, SFunction<E, P> valueFunc, Consumer<E>... peeks) {
* return list2Map(Db.list(wrapper.setEntityClass(getType(keyFunc))), keyFunc, valueFunc, peeks);
* }
*/
@Test
void map1() {
/**
* 条件查询未设置 查询所有条件
* 在所有条件中
* 我将 key设置为 id 将value设置name 那么返回的结果就是以 key、value的形式进行封装
* 查询结果 :aLong == 》 1 s == 》xiaohong
* aLong == 》 2 s == 》xaioming
* aLong == 》 3 s == 》xiaohu
* aLong == 》 5 s == 》Model测试数据1
*/
Map<Long, String> map = SimpleQuery.map(new LambdaQueryWrapper<Student>(), Student::getId, Student::getName);
map.forEach((aLong, s) -> System.out.println("aLong == 》 " + aLong+ " s == 》" + s));
}
/**
* 第一个参数条件对象
* 第二个参数根据结果筛选
* 第三个参数消费性接口
* public static <E, A> Map<A, E> keyMap(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, Consumer<E>... peeks) {
* return list2Map(Db.list(wrapper.setEntityClass(getType(sFunction))), sFunction, Function.identity(), peeks);
* }
*/
@Test
void keymap() {
/**
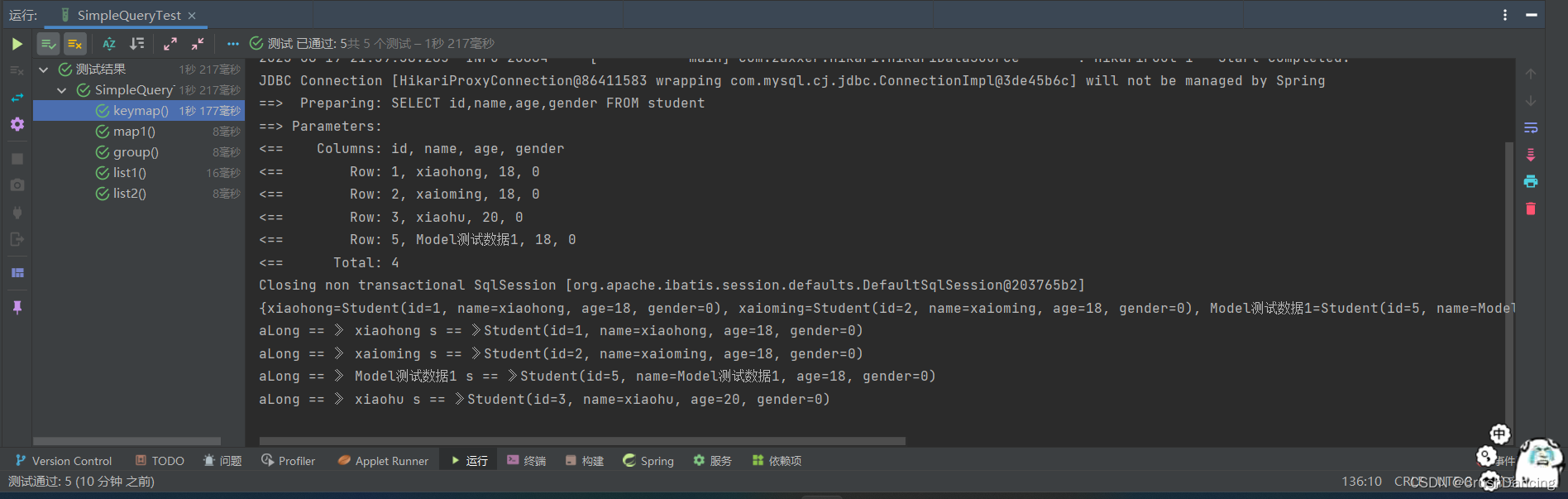
* 将name设置为key 返回的结果就是以name当作key键
* 返回结果 -- 》 {xiaohong=Student(id=1, name=xiaohong, age=18, gender=0), xaioming=Student(id=2, name=xaioming, age=18, gender=0), Model测试数据1=Student(id=5, name=Model测试数据1, age=18, gender=0), xiaohu=Student(id=3, name=xiaohu, age=20, gender=0)}
*/
Map<String, Student> map = SimpleQuery.keyMap(new LambdaQueryWrapper<Student>(), Student::getName);
System.out.println(map);
map.forEach((aLong, s) -> System.out.println("aLong == 》 " + aLong+ " s == 》" + s));
}
/**
* group重载的许多 我只解释其中一种
* 第一个参数是条件对象
* 第二个参数是对条件查询对象查询出来的值进行筛选
* 第三个参数消费性接口
* public static <E, A> Map<A, List<E>> group(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, Consumer<E>... peeks) {
* return listGroupBy(Db.list(wrapper.setEntityClass(getType(sFunction))), sFunction, peeks);
* }
*/
@Test
void group() {
/**
* 分组查询 我未设置具体的查询条件 直接返回所有的数据
* 并且我根据年龄进行分组 那么就会把相同的年龄作为一组进行划分
* integer == 年龄
* students == 封装的数据
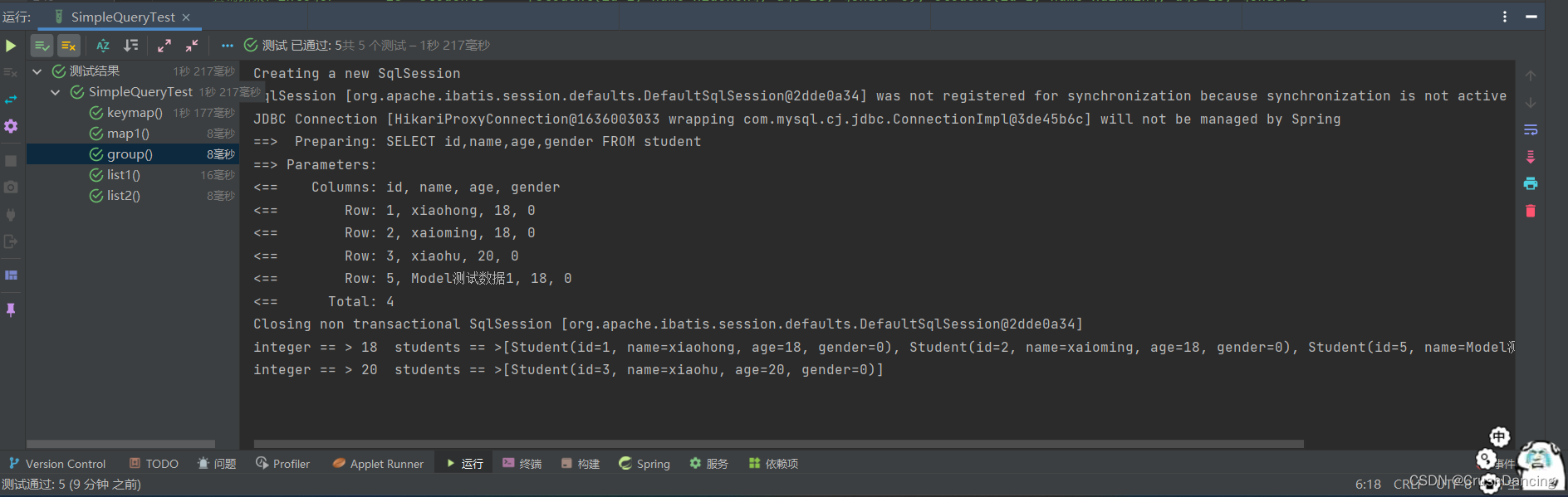
* 查询结果:integer == > 18 students == >[Student(id=1, name=xiaohong, age=18, gender=0), Student(id=2, name=xaioming, age=18, gender=0), Student(id=5, name=Model测试数据1, age=18, gender=0)]
* integer == > 20 students == >[Student(id=3, name=xiaohu, age=20, gender=0)]
*/
Map<Integer, List<Student>> group = SimpleQuery.group(new LambdaQueryWrapper<Student>(), Student::getAge);
group.forEach((integer, students) -> System.out.println("integer == > " + integer + " students == >" + students));
}
}
以上就是基本的使用,总而言之,就是使用SimpleQuery工具类可以让开发更加的快,并且代码美观,简洁。
测试结果:
list1() 的测试结果
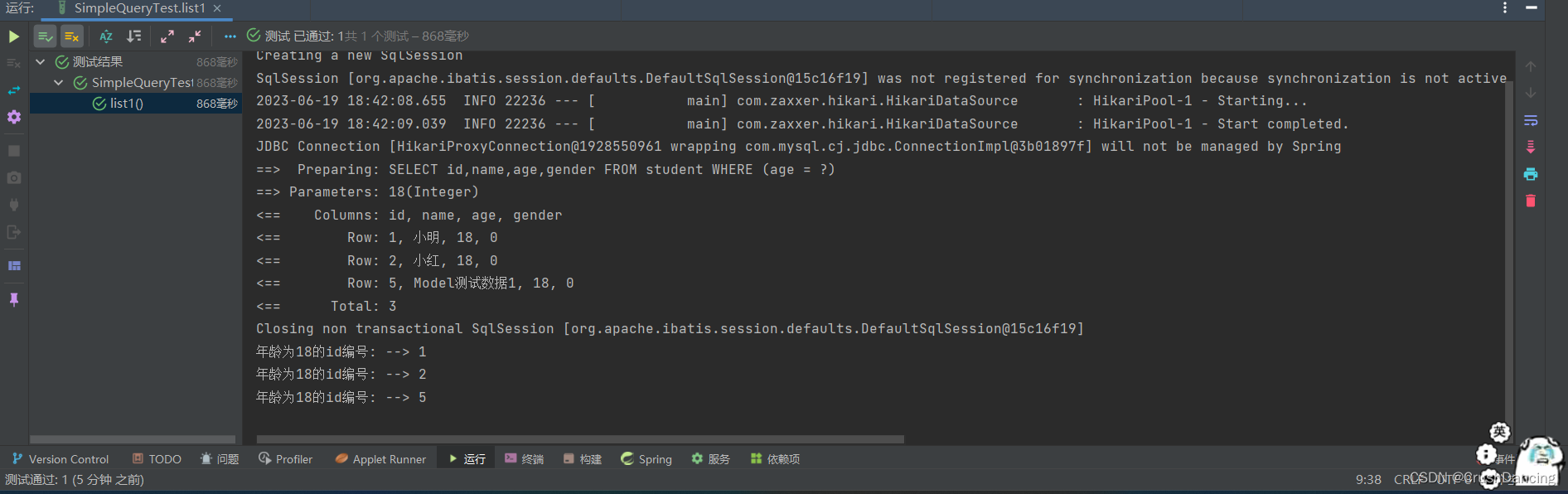
list2() 的测试结果
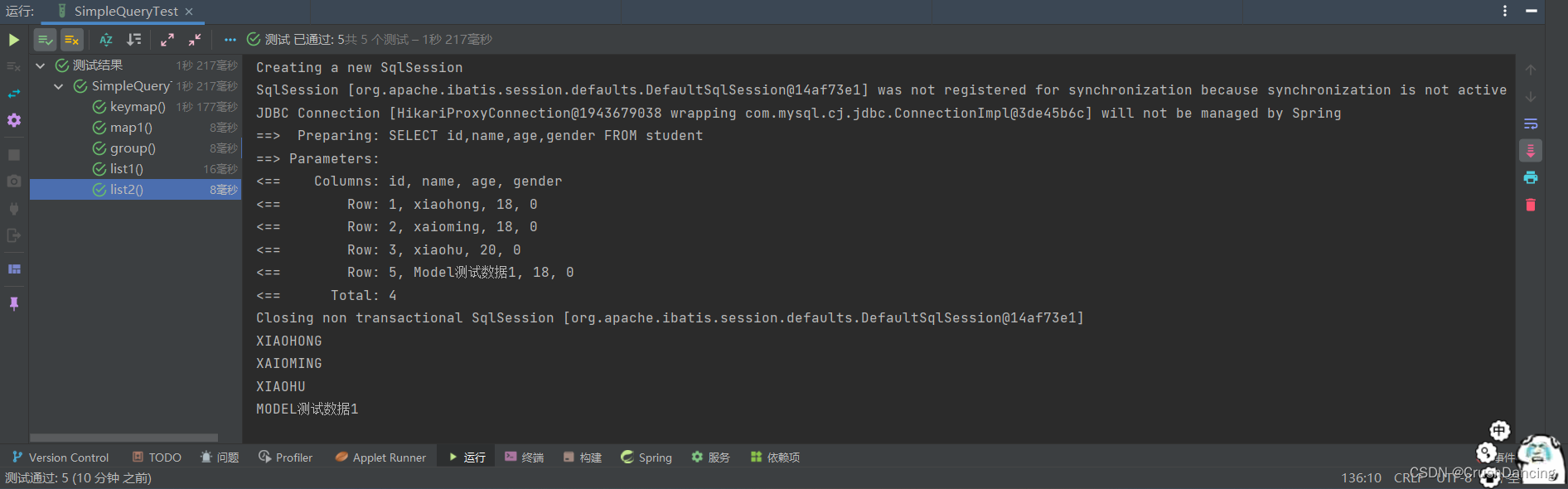
map1() 的测试结果
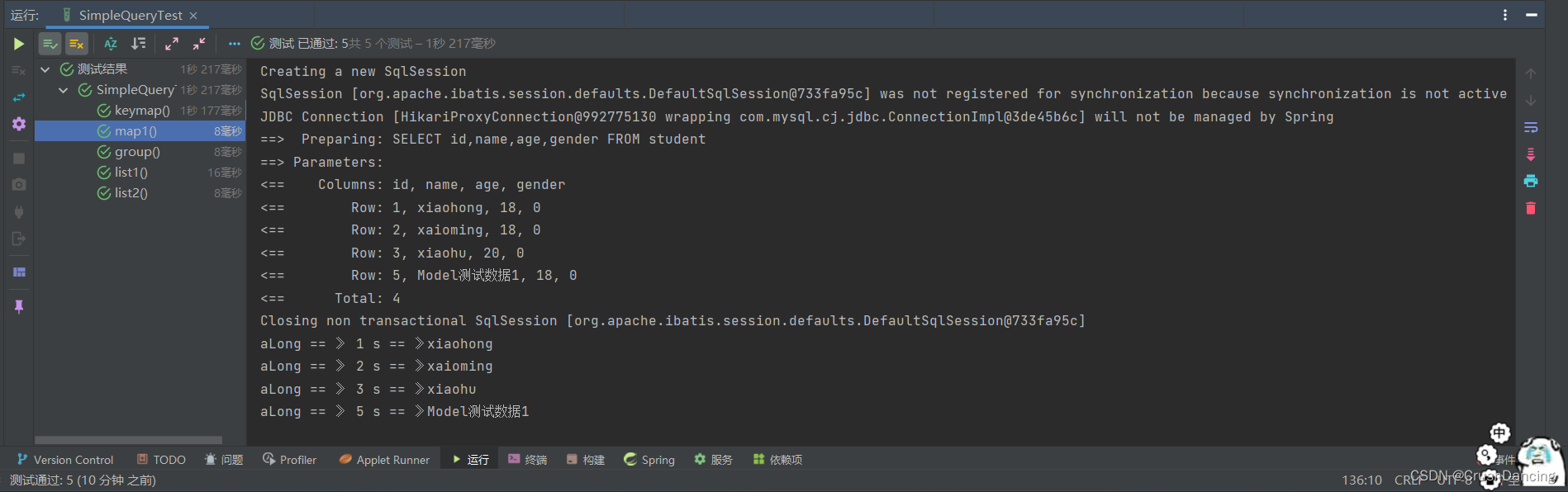
keyMap() 的测试结果
group() 的测试结果















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









